Having discussed vector spaces and linear transformations in sufficient generality, we are finally ready to discuss matrices: the beefed-up brother to vectors.
Let 




Definition 1. For positive integers 
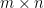




![\mathbf A = \begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1n} \\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \end{bmatrix} = \begin{bmatrix}\mathbf a_1 & \dots & \mathbf a_n \end{bmatrix} = [a_{ij}].](https://s0.wp.com/latex.php?latex=%5Cmathbf+A+%3D+%5Cbegin%7Bbmatrix%7D+a_%7B11%7D+%26+a_%7B12%7D+%26+%5Ccdots+%26+a_%7B1n%7D+%5C%5C+a_%7B21%7D+%26+a_%7B22%7D+%26+%5Ccdots+%26+a_%7B2n%7D+%5C%5C+%5Cvdots+%26+%5Cvdots+%26+%5Cddots+%26+%5Cvdots+%5C%5C+a_%7Bm1%7D+%26+a_%7Bm2%7D+%26+%5Ccdots+%26+a_%7Bmn%7D++%5Cend%7Bbmatrix%7D+%3D+%5Cbegin%7Bbmatrix%7D%5Cmathbf+a_1+%26+%5Cdots+%26+%5Cmathbf+a_n+%5Cend%7Bbmatrix%7D+%3D+%5Ba_%7Bij%7D%5D.&bg=ffffff&fg=000&s=0&c=20201002)
We will let 



This is where our discussion on matrices will diverge from the usual progression—defining the various operations and then computing several examples. We will not adopt that approach.
Instead, we will interpret matrices, fundamentally, as linear transformations. Then using established ideas in linear transformations, we will recover the natural definitions for such matrix operations.
For vector spaces 


Theorem 1. Let 

Then the map 

Proof. That 





As of now, we have not shown that

to prove that 
For injectivity, fix 

Then for each

Therefore 


Since 

Corollary 1. Let ![\mathbf A = [a_{ij}], \mathbf B = [b_{ij}] \in \mathcal M_{m \times n}(\mathbb K)](https://s0.wp.com/latex.php?latex=%5Cmathbf+A+%3D+%5Ba_%7Bij%7D%5D%2C+%5Cmathbf+B+%3D+%5Bb_%7Bij%7D%5D+%5Cin+%5Cmathcal+M_%7Bm+%5Ctimes+n%7D%28%5Cmathbb+K%29&bg=ffffff&fg=000&s=0&c=20201002)

![[a_{ij}] + [b_{ij}] = [a_{ij} + b_{ij}],\quad c \cdot [a_{ij}] = [c \cdot a_{ij}].](https://s0.wp.com/latex.php?latex=%5Ba_%7Bij%7D%5D+%2B++%5Bb_%7Bij%7D%5D+%3D+%5Ba_%7Bij%7D+%2B+b_%7Bij%7D%5D%2C%5Cquad+c+%5Ccdot++%5Ba_%7Bij%7D%5D+%3D+%5Bc+%5Ccdot+a_%7Bij%7D%5D.&bg=ffffff&fg=000&s=0&c=20201002)
In particular, we have the additive identity ![\mathbf 0 = 0 \cdot [a_{ij}] = [0]](https://s0.wp.com/latex.php?latex=%5Cmathbf+0+%3D+0+%5Ccdot+%5Ba_%7Bij%7D%5D+%3D+%5B0%5D&bg=ffffff&fg=000&s=0&c=20201002)
![[a_{ij}]](https://s0.wp.com/latex.php?latex=%5Ba_%7Bij%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![-[a_{ij}] = (-1)[a_{ij}] = [-a_{ij}]](https://s0.wp.com/latex.php?latex=-%5Ba_%7Bij%7D%5D+%3D+%28-1%29%5Ba_%7Bij%7D%5D+%3D+%5B-a_%7Bij%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
Proof. Define 


For any 

Therefore, the 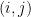


![[a_{ij}] + [b_{ij}] = [a_{ij} + b_{ij}].](https://s0.wp.com/latex.php?latex=%5Ba_%7Bij%7D%5D+%2B+%5Bb_%7Bij%7D%5D+%3D+%5Ba_%7Bij%7D+%2B+b_%7Bij%7D%5D.&bg=ffffff&fg=000&s=0&c=20201002)
Scalar multiplication is derived similarly using the definition 
This construction also strengthens
Corollary 2. 
The key point worth highlighting from Corollary 2 is this:
Matrices are effectively the same as linear transformations from
In more layperson terms, the key point is to think of matrices not as arbitrary tables of numbers, but as encodings of linear transformations. In this regard, the definition of matrix multiplication and its properties become trivial consequences of composing linear transformations.
Definition 2. Let 


Corollary 3. Let 



Proof. By the associativity of function composition,

Therefore,

Lemma 1. Let 

![\mathbf A\mathbf v = [T_{\mathbf A}(\mathbf v)]](https://s0.wp.com/latex.php?latex=%5Cmathbf+A%5Cmathbf+v+%3D+%5BT_%7B%5Cmathbf+A%7D%28%5Cmathbf+v%29%5D&bg=ffffff&fg=000&s=0&c=20201002)

Proof. To prove 


By definition of matrix multiplication,
![\begin{aligned} \mathbf A \mathbf v &= \mathcal S(T_{\mathbf A} \circ T_{\mathbf v}) \\ &= [(T_{\mathbf A} \circ T_{\mathbf v})(1)] \\ &= [T_{\mathbf A} (T_{\mathbf v}(1)) ] = [T_{\mathbf A} (\mathbf v) ]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbf+A+%5Cmathbf+v+%26%3D+%5Cmathcal+S%28T_%7B%5Cmathbf+A%7D+%5Ccirc+T_%7B%5Cmathbf+v%7D%29+%5C%5C+%26%3D+%5B%28T_%7B%5Cmathbf+A%7D+%5Ccirc+T_%7B%5Cmathbf+v%7D%29%281%29%5D+%5C%5C+%26%3D+%5BT_%7B%5Cmathbf+A%7D+%28T_%7B%5Cmathbf+v%7D%281%29%29+%5D+%3D+%5BT_%7B%5Cmathbf+A%7D+%28%5Cmathbf+v%29+%5D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
For the matrix representation, find unique scalars 


As a side-note, Lemma 1 gives us a rather comical yet useful analogy to left-multiplying the matrix 

We can think of each 

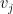

gives us the “dish” 
Corollary 4. Let

In particular,

Furthermore, for 

![\mathbf A \mathbf B = [a_{i1} b_{1j} + \cdots + a_{im} b_{mj}].](https://s0.wp.com/latex.php?latex=%5Cmathbf+A+%5Cmathbf+B+%3D+%5Ba_%7Bi1%7D+b_%7B1j%7D+%2B+%5Ccdots+%2B+a_%7Bim%7D+b_%7Bmj%7D%5D.&bg=ffffff&fg=000&s=0&c=20201002)
Proof. The associativity of matrix multiplication follows from Corollary 3. The 


where the expansion in the fourth “

The final result is the conventional definition for matrix multiplication, but the intermediate result tends to be more intuitive and useful, since it can be interpreted using our recipe-ingredient analogy in the following manner:
- The matrix
encodes the
different recipes, with
denoting the
- Since we have
- For the
to obtain the dish
, which is the
.
Therefore,
Therefore, many of our desired matrix operations arise from regarding matrices as linear transformations, including matrix multiplication, which encodes composing linear transformations. As such, it should make intuitive sense that more often than not, for matrices 


We could wonder to ourselves: are there infinite-dimensional matrices? Once again, if we interpret matrices as linear transformations, and infinite-dimensional vector spaces like ![\mathbb K[x]](https://s0.wp.com/latex.php?latex=%5Cmathbb+K%5Bx%5D&bg=ffffff&fg=000&s=0&c=20201002)
But perhaps let’s at least posit a more immediate question. If there are inverses 


This idea turns out to work. In fact, since

But we will explore this idea in more detail next time. In particular, invertible matrices will help us formalise the otherwise mundane algorithm known as Gaussian elimination.
—Joel Kindiak, 28 Feb 25, 1825H

Leave a comment