We are trying to answer a simple yet very, very nontrivial question: what is a determinant?
Let  be a field and
be a field and  . Let
. Let  . Recall that
. Recall that

Hence, we can think of  as a function that takes in the vectors
as a function that takes in the vectors  and returns a scalar
and returns a scalar  .
.
Definition 1. The determinant of a  matrix is a function
matrix is a function  defined by
defined by

From this definition, we obtain several interesting properties of the determinant.
Theorem 1. The function satisfies the following properties:
- For any
 , the functions
, the functions  and
and  are linear. We call a multilinear function.
are linear. We call a multilinear function.
- For any ,
 . We call an alternative function.
. We call an alternative function.
 . We call a normalised function.
. We call a normalised function.
It turns out that is the only function where these properties hold.
Theorem 2. If  is a multilinear, alternative, and normalised function, then
is a multilinear, alternative, and normalised function, then  .
.
Proof. We observe that for any  , since
, since  is multilinear,
is multilinear,

Since is alternative,  , so that
, so that  . Furthermore, since is normalised.
. Furthermore, since is normalised.

Therefore,

Now for the more crucial question: does this definition work for the general case when  ? Well, if we can construct it, then we can use it. We are going to use these three properties to construct the determinant function. This function is going to coincide with the usual computational definitions.
? Well, if we can construct it, then we can use it. We are going to use these three properties to construct the determinant function. This function is going to coincide with the usual computational definitions.
Henceforth, let with the standard ordered basis  .
.
Definition 2.  be a function. is multilinear if for any
be a function. is multilinear if for any  ,
,

is linear. is alternative if for any 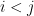 ,
,

is normalised if  .
.
Denote  . For each , find unique scalars
. For each , find unique scalars  such that
such that

Lemma 1. If is multilinear, then

Proof. The first key insight is that summing over all possible ordered choices  corresponds to summing over all possible functions
corresponds to summing over all possible functions  , not necessarily just the bijective ones. With this in mind, a direct though tedious calculation yields
, not necessarily just the bijective ones. With this in mind, a direct though tedious calculation yields

This now reduces our problem to evaluating

given any function . If is alternative, however, then we can whittle down the calculations by one more layer.
Lemma 2. Suppose is alternative, and let . If  , then
, then

Recall that  refers to the set (group, actually) of bijections , also known as permutations.
refers to the set (group, actually) of bijections , also known as permutations.
Proof. Since  is finite, if
is finite, if  is not bijective, then it is not injective. Hence, there exists
is not bijective, then it is not injective. Hence, there exists  such that
such that  . Since is alternative,
. Since is alternative,

By algebruh,  .
.
Corollary 1. If is multilinear and alternative, then

Let’s not underestimate the magnitude of what we did here. The key trick is that when we used multi-linearity, we could reduce the computation over all indices into sums over  . This set is massive: there are
. This set is massive: there are  such functions.
such functions.
To put this computation into perspective: this means computing a  determinant originally needs to account for
determinant originally needs to account for  summands! Thankfully, the alternative property comes in clutch, because we can reduce the sum to index over
summands! Thankfully, the alternative property comes in clutch, because we can reduce the sum to index over  . In the
. In the 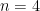 case, this means
case, this means  summands. Still tedious, but way less tedious than
summands. Still tedious, but way less tedious than  terms.
terms.
So now we reduce the problem one more layer: how do we evaluate
for ? Let’s first consider the simplest case:  . In this case, we get the expression
. In this case, we get the expression

If is normalised, then  . How then do we deal with other kinds of permutations ?
. How then do we deal with other kinds of permutations ?
Let’s leverage the alternative property of . What that refers to is that swapping vectors will cause a sign-flip on the determinant. While we could do a brute-force definition, a special permutation known as a transposition will simplify the process for us.
Definition 3. A bijection  is called a transposition if there exist two distinct elements
is called a transposition if there exist two distinct elements  such that for any
such that for any  ,
,

In this case, we denote  .
.
Lemma 3. If is alternative, then

for any transposition 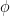 . Furthermore, for any composition
. Furthermore, for any composition  of transpositions,
of transpositions,

Now here’s the golden ticket to the problem: if can be written as a product of transpositions, i.e.  , then
, then

If is normalised, then the right-hand side yields a simple quantity. However, does this property hold? Tune into the next post to find out.
—Joel Kindiak, 4 Mar 25, 2310H

Leave a comment