Previously, we undertook the heavy duty of defining determinants. Let  be a field and
be a field and  .
.
Definition 1. Define the determinant  of an
of an  matrix by
matrix by

By this definition, the determinant is multilinear, alternating, and normalised.
By our investigations in previous posts, any function  that satisfies these three properties can only have the formula in Definition 1. Why then do we describe the determinant in terms of these three properties?
that satisfies these three properties can only have the formula in Definition 1. Why then do we describe the determinant in terms of these three properties?
So that manipulation makes more sense.
Lemma 1. Let  . For any elementary matrix
. For any elementary matrix  ,
,

Proof. We just need to verify this fact for each of the three row operations. For the row operation corresponding to multiplying one row by nonzero  , suppose without loss of generality that the first row of
, suppose without loss of generality that the first row of  gets multiplied by . Let
gets multiplied by . Let  denote the corresponding elementary matrix. By multi-linearity, the corresponding elementary matrix will then have determinant
denote the corresponding elementary matrix. By multi-linearity, the corresponding elementary matrix will then have determinant

By normality,

Therefore,
 .
.
For the row operation corresponding to adding times of one row to another, suppose without loss of generality we are adding times of row  to row
to row  . Then multi-linearity and alternativity yields
. Then multi-linearity and alternativity yields  equalling
equalling

Therefore,

For row-swapping, the result is immediate due to  being alternative.
being alternative.
In particular, we have one of the most important uses of determinants: characterising invertible matrices.
Theorem 1. For any square matrix , is invertible if and only if  .
.
Proof. Let  denote the reduced row-echelon form of and
denote the reduced row-echelon form of and  be elementary matrices that transform into :
be elementary matrices that transform into :

Recall that inverses of elementary matrices are themselves elementary matrices. By induction on Lemma 1,

where we denote  for brevity. Recall that is invertible if and only if
for brevity. Recall that is invertible if and only if  . If , then
. If , then  as a product of nonzero scalars. If
as a product of nonzero scalars. If  , then is not injective, and thus has at least one zero row. Hence,
, then is not injective, and thus has at least one zero row. Hence,

so that  .
.
Furthermore, we obtain the crucial multiplicativity property of determinants.
Theorem 2. For  ,
,  .
.
Proof. If and  are both invertible, then both matrices can be expressed as products of elementary matrices, and Lemma 1 yields the desired result. If either or are not invertible (i.e. singular), then by Theorem 1, it suffices to prove that
are both invertible, then both matrices can be expressed as products of elementary matrices, and Lemma 1 yields the desired result. If either or are not invertible (i.e. singular), then by Theorem 1, it suffices to prove that  is singular.
is singular.
If is singular, then is not injective and there exists some nonzero  such that
such that  . Hence,
. Hence,

Thus, is not injective and thus singular, as required.
Suppose otherwise that is invertible. If is invertible, then  is invertible too. Taking contrapositives, if is singular, then is singular, as required.
is invertible too. Taking contrapositives, if is singular, then is singular, as required.
What these investigations tell us is that to compute the determinant of a square matrices, , we can perform Gauss-Jordan elimination, and then multiply the determinants of the corresponding “actions” along the way.
While this certainly gives us some computational grasp on the determinant, we are instant-gratification addicts—can we look at a matrix and compute its determinant immediately and quickly? For instance, in the  case, we don’t have any issues, since
case, we don’t have any issues, since

as per prior investigations. Denote  for brevity. For the
for brevity. For the  case, the idea is to build it up from the case. Recall the computational definition of
case, the idea is to build it up from the case. Recall the computational definition of  :
:

Now, for  , it is obvious that
, it is obvious that  . Therefore, the right-hand side simplifies to
. Therefore, the right-hand side simplifies to

For each  , since
, since  is bijective (and thus injective),
is bijective (and thus injective),  . Therefore, for any with
. Therefore, for any with  , define the permutation
, define the permutation  by
by

In general,  for
for  and
and  . Defining
. Defining  , where
, where  is increasing, since is bijective,
is increasing, since is bijective,  is a permutation on
is a permutation on  , which corresponds to a permutation
, which corresponds to a permutation  on
on  with
with  , via the relation
, via the relation

Therefore,  and
and

where we write  for convenience. Thus, we can use the determinant to define the determinant. In fact, the same relation works in the sense of using the
for convenience. Thus, we can use the determinant to define the determinant. In fact, the same relation works in the sense of using the  determinant (i.e. the entry itself) to define the determinant. This yields the Laplace expansion of the determinant, also known as cofactor expansion, which is computationally much more convenient than previous ideas.
determinant (i.e. the entry itself) to define the determinant. This yields the Laplace expansion of the determinant, also known as cofactor expansion, which is computationally much more convenient than previous ideas.
Theorem 3 (Laplace Expansion). For any  , define the
, define the 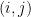 –minor matrix
–minor matrix  by
by

where  and
and  is strictly increasing in
is strictly increasing in  . Then
. Then

regardless of the choice of  . The term
. The term  is called the –cofactor of .
is called the –cofactor of .
Proof. We have proven the case  in preceding discussions. We used
in preceding discussions. We used  for concreteness and simplicity, but the argument can be generalised. For the case of general , perform
for concreteness and simplicity, but the argument can be generalised. For the case of general , perform  row-swaps and apply the case for (with the needful relabelings) to obtain
row-swaps and apply the case for (with the needful relabelings) to obtain

Lemma 2. Doing cofactor expansion on the columns instead of the rows yields the same result: for any fixed ,

Proof. It suffices to prove that ![|[a_{ij}]| = [a_{ji}]](https://s0.wp.com/latex.php?latex=%7C%5Ba_%7Bij%7D%5D%7C+%3D+%5Ba_%7Bji%7D%5D&bg=ffffff&fg=000&s=0&c=20201002) . We will use Definition 1 to achieve this goal:
. We will use Definition 1 to achieve this goal:

Corollary 1. If , then
![\displaystyle \mathbf A^{-1} = \frac 1{\det(\mathbf A)} \mathrm{adj}(\mathbf A), \quad \mathrm{adj}(\mathbf A) = [{(-1)}^{i+j} |\mathbf A_{ji}|].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbf+A%5E%7B-1%7D+%3D+%5Cfrac+1%7B%5Cdet%28%5Cmathbf+A%29%7D+%5Cmathrm%7Badj%7D%28%5Cmathbf+A%29%2C+%5Cquad+%5Cmathrm%7Badj%7D%28%5Cmathbf+A%29+%3D+%5B%7B%28-1%29%7D%5E%7Bi%2Bj%7D+%7C%5Cmathbf+A_%7Bji%7D%7C%5D.&bg=ffffff&fg=000&s=0&c=20201002)
Proof. Let  denote the
denote the 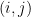 -term of
-term of  . By cofactor-expanding along the -th row according to Theorem 1,
. By cofactor-expanding along the -th row according to Theorem 1,

The -entry of  is, by matrix multiplication,
is, by matrix multiplication,

since for 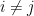 , the sum is the determinant of a matrix with two identical rows and thus equals
, the sum is the determinant of a matrix with two identical rows and thus equals  . Therefore,
. Therefore,

Taking inverses on both sides yields the desired result.
Corollary 2. For matrices  of relevant sizes,
of relevant sizes,

Proof Sketch. Apply induction on the size of .
Corollary 3. Applying Theorem 3 on row , the determinant of a matrix is given by

Finally, with all that hard work, we recover our usual formulas for the determinant that are otherwise spawned from thin air in understandably time- and resource-constrained introductory linear algebra courses.
Back to the main fun of linear algebra: eigenvectors and eigenvalues a.k.a. eigenstuff.
—Joel Kindiak, 6 Mar 25, 1400H

Leave a comment