Previously, we defined eigenvectors and eigenvalues, and used them to obtain a succinct formula for the  -th Fibonacci number
-th Fibonacci number  , known as Binet’s formula:
, known as Binet’s formula:

where  denotes the golden ratio. We needed to take advantage of the eigenvectors and eigenvalues of the matrix
denotes the golden ratio. We needed to take advantage of the eigenvectors and eigenvalues of the matrix  . In particular, we needed to find two eigenvectors
. In particular, we needed to find two eigenvectors  that can encode any
that can encode any  . That is, we wanted a basis for
. That is, we wanted a basis for  comprised of the eigenvectors of
comprised of the eigenvectors of  .
.
Let  be a field and
be a field and  be a vector space over .
be a vector space over .
Definition 1. Let 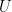 be a vector space over . The linear transformation
be a vector space over . The linear transformation  is similar to
is similar to  if there exists an isomorphism
if there exists an isomorphism  such that
such that  . Equivalently,
. Equivalently,  . We remark that the “is similar to” relation behaves like an equivalence relation.
. We remark that the “is similar to” relation behaves like an equivalence relation.
Example 1. If is finite dimensional with  , then any linear transformation is similar to some linear transformation
, then any linear transformation is similar to some linear transformation  . This means that computations in can effectively be reduced to computations in
. This means that computations in can effectively be reduced to computations in  .
.
Lemma 1. Let and be similar linear transformations. Then there exists an isomorphism such that for any  ,
,

where 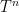 denotes -fold composition of
denotes -fold composition of  .
.
Roughly speaking, Definition 1 gives us a condition on which and have essentially the same (i.e. similar) effect on the vectors in their respective vector spaces. The similarity vocabulary empowers us to discuss diagonalisation.
Definition 2. A matrix  is diagonal if each
is diagonal if each  is an eigenvector of
is an eigenvector of  , i.e. for each , there exists
, i.e. for each , there exists  such that
such that  .
.
In matrix notation, we have

In particular, for any ,  . A matrix
. A matrix  is diagonalisable if it is similar to some diagonal matrix.
is diagonalisable if it is similar to some diagonal matrix.
Theorem 1. A matrix is diagonalisable if and only if there exists a basis  of
of  such that each
such that each  is an eigenvector of .
is an eigenvector of .
Proof. We prove this theorem in two directions. Suppose is diagonalisable. Then there exists a diagonal matrix and an invertible matrix  such that
such that

Writing  and employing the recipe-ingredient analogy for matrix multiplication,
and employing the recipe-ingredient analogy for matrix multiplication,

Since  for each
for each  ,
,  forms the desired basis proving the direction
forms the desired basis proving the direction  . Reversing the argument is not hard, and establishes the direction
. Reversing the argument is not hard, and establishes the direction  .
.
One theoretical consequence is that diagonalisation only proves meaningful when discussing vector spaces that have convenient “standard bases”, such as with the standard ordered basis  . Nevertheless, the discussion on eigenstuff generally still works in broad contexts, especially if the vector space is finite-dimensional.
. Nevertheless, the discussion on eigenstuff generally still works in broad contexts, especially if the vector space is finite-dimensional.
Corollary 1. Suppose . A linear transformation is diagonalisable if it is similar to a diagonalisable matrix . Then is diagonalisable if and only if there exists a basis of such that each is an eigenvector of .
Definition 3. A linear transformation is diagonalisable if there exists a basis of such that each is an eigenvector of .
Therefore, we can reduce our study of general finite-dimensional vector spaces to the concrete setting of . In this case, what sufficiently simple tests do we have to know if a matrix is diagonalisable?
Lemma 2. Any matrix has at most distinct eigenvalues. In particular, if has distinct eigenvalues, then is diagonalisable.
Proof. Each eigenvalue  yields an eigenvector , and since distinct eigenvalues yield linearly independent eigenvectors , the set
yields an eigenvector , and since distinct eigenvalues yield linearly independent eigenvectors , the set  is linearly independent, so that
is linearly independent, so that  . In particular, if
. In particular, if  , the set forms a basis for , as required.
, the set forms a basis for , as required.
Example 1. Since  has two eigenvalues
has two eigenvalues  , it is diagonalisable, and by Corollary 1, we could extract two key vectors
, it is diagonalisable, and by Corollary 1, we could extract two key vectors  such that
such that  trivially. This property was key in helping us derive the formula for the Fibonacci numbers.
trivially. This property was key in helping us derive the formula for the Fibonacci numbers.
Now, what if we had less than eigenvalues? Is all hope lost? Not quite. Theorem 1 only requires us to have eigenvectors. Some of them might have the same eigenvalues—that’s alright. Let  denote the eigenvalues of . Each eigenvalue yields at least one nonzero eigenvector such that
denote the eigenvalues of . Each eigenvalue yields at least one nonzero eigenvector such that

It is clear that  .
.
Definition 4. We call the function  the characteristic polynomial of . In particular,
the characteristic polynomial of . In particular,  is an eigenvalue of if and only if
is an eigenvalue of if and only if  .
.
Lemma 3. If  are similar, then
are similar, then  .
.
Proof. Let  be a matrix such that
be a matrix such that  . Then
. Then

By the factor theorem, there exists a polynomial ![p \in \mathbb K_{n-k}[x]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5Cmathbb+K_%7Bn-k%7D%5Bx%5D&bg=ffffff&fg=000&s=0&c=20201002) and unique integers
and unique integers 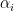 such that
such that

We call the algebraic multiplicity of  . If
. If  , then by the fundamental theorem of algebra, we can take
, then by the fundamental theorem of algebra, we can take  so that
so that

In any case, the point from Lemma 2 is that captures all of the eigenvectors of with eigenvalue . Denote  , called the geometric multiplicity of . We have a fascinating result.
, called the geometric multiplicity of . We have a fascinating result.
Theorem 2. For any eigenvalue of for  ,
,  . Hence, if and
. Hence, if and  for all , then is diagonalisable.
for all , then is diagonalisable.
Proof. Let  denote the eigenvectors in . Extend to a basis
denote the eigenvectors in . Extend to a basis  of with corresponding invertible matrix . Then is similar to the matrix
of with corresponding invertible matrix . Then is similar to the matrix

not necessarily diagonal. It follows that

Hence,  is a factor of
is a factor of  , which itself contains a factor of
, which itself contains a factor of  , which yields . In particular, over
, which yields . In particular, over 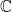 , is diagonalisable if and only if for each eigenvalue , .
, is diagonalisable if and only if for each eigenvalue , .
Far from just determining eigenvalues, the characteristic polynomial boasts remarkable algebraic properties, encapsulated by the Cayley-Hamilton theorem. In particular, rather surprisingly, we can use characteristic polynomials to compute inverse matrices. We will explore these ideas in the next post.
—Joel Kindiak, 7 Mar 25, 1707H

Leave a comment