Probability is our attempt at making sense of random events in our rather random world. The simplest example—a coin toss—will surprisingly motivate many topics that we will formulate with greater and greater generality.
Flip a coin. You get 


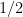
In mathematical notation, we let the sample space 

But more is true. What is the probability that we get either a ‘Head’ or a ‘Tail’? In the real would it could be the case that a coin lands on its edge, but in a mathematical world, we preclude such a possibility. This means that there are only two possible outcomes: a ‘Head’ or a ‘Tail’, and they don’t overlap. At least one of them must be true! Hence, it makes sense to assert

This discussion almost seems trivial, until we make one modification. Now flip the coin two times. You get
Let’s list down the different possible outcomes:

How do we assign their probabilities? And furthermore, how do we determine our score? Assuming no funny business, we would think that all outcomes are equally likely. Once again, at least one outcome should hold, so we stipulate 


We can now formalise probability theory for finite sample spaces; the infinite case deserves a much, much longer elaboration.
Definition 1. Let 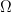



for distinct outcomes 
Additionally, if 


Lemma 1. For any finite sample space 

![\mathbb P : \mathcal P(\Omega) \to [0, 1]](https://s0.wp.com/latex.php?latex=%5Cmathbb+P+%3A+%5Cmathcal+P%28%5COmega%29+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
Proof. Define 

Hence, we can discuss most ideas using the more general 

Theorem 1. If 
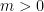



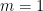

Proof. Denoting 

Therefore,
In particular, for any 


Corollary 1. Under the conditions of Theorem 1, if 
Proof. By Theorem 1, for any

Hence,

In particular,

Let’s return to the situation

Recall that our goal is to determine the score 



This means that the outcomes 


Well then, what do we mean by 



Definition 2. Let 

Theorem 2. As per the notation in Definition 2, denote 





Proof. For any 

Before continuing, you might wonder: what’s with the rather complicated terminology? Well, it’s to tease you on the key vocabulary that one cannot escape when studying measure theory and probability.
In fact, there is even a simpler question that isn’t entirely obvious, given a set
—Joel Kindiak, 22 Jun 25, 1249H

Leave a comment