When I took my A-Level examinations, I was required to take a Chemistry practical assessment. In this assessment, I collected data and needed to draw a line of best-fit. About that time, I learned linear algebra, and thought I’d apply what I learned to compute the perfect best-fit line. I got an ‘A’ for Chemistry in the end. It helped me quite a bit.
Given the dataset 

that minimises the total squared-error 

The probability that we can even solve this won’t be high, since we have too much data! For instance, the simple data set 

Even more generally, if 





Lemma 1. For any subspace 

is also a subspace of

Proof. If 

The decomposition 

yields the desired result.
Theorem 1. Let 



We call this expression the orthogonal decomposition of 

Proof. We have established existence by Lemma 1, and it remains to prove uniqueness. Consider two possible decompositions

Then

yielding 

So the projection is indeed a powerful tool, since we can always write 

Definition 1. For any 



Theorem 2. For any 
Proof. Firstly, for vectors 

Thus, we have Pythagoras’ theorem for inner product spaces if 

Therefore, for any

For uniqueness, suppose 


Hence, 


where we set them equal 

Substituting the various values,

Hence, 


The key take-away is this: the best approximation of
Corollary 1. Let 




Proof. Apply Theorem 2 to the subspace 
This result helps us partly solve our original equation. Let 



The key property that we want to exploit is that 


It turns out that in solving this problem, we are finally forced to introduce the idea of the matrix transpose, which we will properly discuss in the next post. Remember, we haven’t technically answered our best-fit line question: find meaningful constants 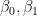

As a side-note, we can generalise this problem to a more realistic setting involving machine learning datasets 



More on these ideas in future posts.
—Joel Kindiak, 12 Mar 25, 2102H

Leave a comment