Introductory mathematics undergraduates do not know what diagonalization is. Those introduced to linear algebra learn that not all matrices can be diagonalised—not even all square matrices. Those who learn a bit more recognise that square matrices over 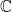
Legends suggest that any matrix over 
Theorem 1 (Singular Value Decomposition). For any matrix 




Here, we say that 
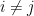
Lemma 1. The matrix 
Proof. By conjugate-transpose properties,

Therefore, the matrix 

Now suppose 

By the non-degeneracy of 

Lemma 2. Let 

.
.
.
.
Proof. For the first claim, we leave it as an exercise to verify that 

Hence,

By the rank-nullity theorem,

The second result follows from the inequalities 



The direction 
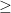

Proof of Theorem 1. We first note that it suffices to establish the equation

Letting 





we obtain for any 

and

This means we need to find suitable orthonormal vectors 



In particular,

By Lemma 2, suppose 

some possibly repeated, and orthonormal basis 

In particular, 



Then 
Remark 1. The constants 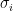

Therefore, any matrix, given effort, can be diagonalised, albeit rather creatively using our arsenal of linear algebraic tools.
—Joel Kindiak, 26 Mar 25, 1920H

Leave a comment