Let  be Fréchet-differentiable.
be Fréchet-differentiable.
Problem 1. Prove that if  gives a local extremum for
gives a local extremum for  , then
, then  .
.
(Click for Solution)
Solution. Suppose  is a local maximum for without loss of generality (otherwise, is a local maximum for
is a local maximum for without loss of generality (otherwise, is a local maximum for  ). Then there exists
). Then there exists  and a neighborhood of with radius
and a neighborhood of with radius  such that for
such that for  ,
,

Consider the quantity  . By definition,
. By definition,

For  , we have
, we have  . Therefore, taking
. Therefore, taking  yields
yields  , and taking
, and taking  yields
yields  , so that
, so that  . Therefore, for any
. Therefore, for any  ,
,

Therefore, .
Suppose has continuous first- and second-order partial deriatives and  be a domain.
be a domain.
Definition 1. Define the Hessian matrix  of by
of by

We remark that is symmetric by Clairaut’s theorem.
Problem 2. Suppose 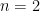 and
and  . Prove the following:
. Prove the following:
 gives a local maximum if
gives a local maximum if  and
and  .
.- gives a local minimum if and
 .
.
- is not a local extremum if
 .
.
(Click for Solution)
Solution. In the case ,

and so by Clairaut’s theorem has a determinant of

Fix  and assume
and assume  without loss of generality. Compute
without loss of generality. Compute  and simplify using Clairaut’s theorem and completing the square to obtain
and simplify using Clairaut’s theorem and completing the square to obtain
![\displaystyle \begin{aligned}\partial_{\mathbf v}^2(f) &= \partial_{\mathbf v}(\partial_{\mathbf v}(f)) \\ &= \partial_{\mathbf v}(v_1 \cdot f_x + v_2 \cdot f_y) \\ &= v_1 \cdot (v_1 \cdot f_x + v_2 \cdot f_y)_x + v_2 \cdot (v_1 \cdot f_x + v_2 \cdot f_y)_y \\ &= v_1^2 \cdot f_{xx} + 2v_1 v_2 \cdot f_{xy} + v_2^2 \cdot f_{yy} \\ &= f_{xx} \cdot \left( v_1 + v_2\cdot \frac{f_{xy}}{f_{xx}}\right)^2 + \frac{v_2^2}{f_{xx}} \cdot (f_{xx} \cdot f_{yy} - f_{xy}^2) \\ &= f_{xx} \cdot \left[ \left( v_1 + v_2\cdot \frac{f_{xy}}{f_{xx}}\right)^2 + \frac{v_2^2}{f_{xx}^2} \cdot |(\mathbf H(f))(\cdot)| \right]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D%5Cpartial_%7B%5Cmathbf+v%7D%5E2%28f%29+%26%3D+%5Cpartial_%7B%5Cmathbf+v%7D%28%5Cpartial_%7B%5Cmathbf+v%7D%28f%29%29+%5C%5C+%26%3D+%5Cpartial_%7B%5Cmathbf+v%7D%28v_1+%5Ccdot+f_x+%2B+v_2+%5Ccdot+f_y%29+%5C%5C+%26%3D+v_1+%5Ccdot+%28v_1+%5Ccdot+f_x+%2B+v_2+%5Ccdot+f_y%29_x+%2B+v_2+%5Ccdot+%28v_1+%5Ccdot+f_x+%2B+v_2+%5Ccdot+f_y%29_y+%5C%5C+%26%3D+v_1%5E2+%5Ccdot+f_%7Bxx%7D+%2B+2v_1+v_2+%5Ccdot+f_%7Bxy%7D+%2B+v_2%5E2+%5Ccdot+f_%7Byy%7D+%5C%5C+%26%3D+f_%7Bxx%7D+%5Ccdot+%5Cleft%28+v_1+%2B+v_2%5Ccdot+%5Cfrac%7Bf_%7Bxy%7D%7D%7Bf_%7Bxx%7D%7D%5Cright%29%5E2+%2B+%5Cfrac%7Bv_2%5E2%7D%7Bf_%7Bxx%7D%7D+%5Ccdot+%28f_%7Bxx%7D+%5Ccdot+f_%7Byy%7D+-+f_%7Bxy%7D%5E2%29+%5C%5C+%26%3D+f_%7Bxx%7D+%5Ccdot+%5Cleft%5B+%5Cleft%28+v_1+%2B+v_2%5Ccdot+%5Cfrac%7Bf_%7Bxy%7D%7D%7Bf_%7Bxx%7D%7D%5Cright%29%5E2+%2B+%5Cfrac%7Bv_2%5E2%7D%7Bf_%7Bxx%7D%5E2%7D+%5Ccdot+%7C%28%5Cmathbf+H%28f%29%29%28%5Ccdot%29%7C+%5Cright%5D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Suppose  . If
. If  , then there exists
, then there exists 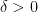 such that if
such that if  , then
, then  . Consider the function
. Consider the function ![\gamma : [-1, 1] \to \mathbb R](https://s0.wp.com/latex.php?latex=%5Cgamma+%3A+%5B-1%2C+1%5D+%5Cto+%5Cmathbb+R&bg=ffffff&fg=000&s=0&c=20201002) defined by
defined by

Differentiating twice,

In particular,  and
and  . By the usual second derivative test,
. By the usual second derivative test,  is a local minimum on the line segment
is a local minimum on the line segment ![\mathbf x_0 + [-\delta, \delta] \cdot \mathbf v](https://s0.wp.com/latex.php?latex=%5Cmathbf+x_0+%2B+%5B-%5Cdelta%2C+%5Cdelta%5D+%5Ccdot+%5Cmathbf+v&bg=ffffff&fg=000&s=0&c=20201002) . Since this argument holds regardless of ,
. Since this argument holds regardless of , 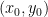 yields a local minimum for .
yields a local minimum for .
The argument holds similarly in the other two cases.
Problem 3. Write down the maximum value of  in terms of
in terms of 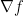 .
.
(Click for Solution)
Solution. Assume  without loss of generality. Recall that
without loss of generality. Recall that

where ![\theta \in [0, \pi]](https://s0.wp.com/latex.php?latex=%5Ctheta+%5Cin+%5B0%2C+%5Cpi%5D&bg=ffffff&fg=000&s=0&c=20201002) . To maximise , we need
. To maximise , we need  such that
such that  , which means
, which means 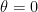 . In this case,
. In this case,  , so that
, so that

Therefore, the maximum value of is  . On the opposite end, the vector
. On the opposite end, the vector

minimises , yielding the famous machine learning technique called gradient descent.
Let  be Fréchet-differentiable.
be Fréchet-differentiable.
Problem 4. Define the zero surface of  by
by

Let ![\mathbf r : [-1, 1] \to S](https://s0.wp.com/latex.php?latex=%5Cmathbf+r+%3A+%5B-1%2C+1%5D+%5Cto+S&bg=ffffff&fg=000&s=0&c=20201002) be a continuously differentiable curve with
be a continuously differentiable curve with  . Prove that
. Prove that  .
.
(Click for Solution)
Solution. By the chain rule,

Problem 5. The tangent plane  to
to  at is defined by
at is defined by

Prove that if  , then for any vector
, then for any vector  ,
,

(Click for Solution)
Solution. Since can be affinely transformed to a subspace of  , we assume
, we assume  without loss of generality. Then we see that
without loss of generality. Then we see that  with dimension
with dimension 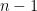 . In this case,
. In this case,  if and only if
if and only if  .
.
Problem 6. Suppose  has continuous first-order partial derivatives and
has continuous first-order partial derivatives and  for any
for any  . Evaluate the local extrema of on whenever they exist.
. Evaluate the local extrema of on whenever they exist.
(Click for Solution)
Solution. Let be a local extremum of on . We claim that there exists  such that
such that

Let be any continuously differentiable curve with . Define ![h = f \circ \mathbf r : [-1, 1] \to \mathbb R](https://s0.wp.com/latex.php?latex=h+%3D+f+%5Ccirc+%5Cmathbf+r+%3A+%5B-1%2C+1%5D+%5Cto+%5Cmathbb+R&bg=ffffff&fg=000&s=0&c=20201002) . Differentiating using the chain rule, since
. Differentiating using the chain rule, since  is a local extremum at
is a local extremum at  ,
,

In particular,  . Therefore,
. Therefore,  . Hence, there exists such that
. Hence, there exists such that
Corollary 1. Define the Lagrangian  by
by

Under the hypotheses of Problems 4 to 6, if is a local extremum, then there exists such that  . In this case, we call
. In this case, we call  a Lagrange multiplier for the optimisation problem.
a Lagrange multiplier for the optimisation problem.
—Joel Kindiak, 13 Aug 25, 1243H

Leave a comment