Having ventured far into the measure-theoretic world and taking great pains to verify that taking the length ![\lambda([a,b]) = b-a](https://s0.wp.com/latex.php?latex=%5Clambda%28%5Ba%2Cb%5D%29+%3D++b-a&bg=ffffff&fg=000&s=0&c=20201002)
![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=000&s=0&c=20201002)
Definition 1. Let 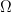
![[a, b]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%5D&bg=ffffff&fg=000&s=0&c=20201002)

![K \subseteq [a, b]](https://s0.wp.com/latex.php?latex=K+%5Csubseteq+%5Ba%2C+b%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\displaystyle \begin{aligned} \mathbb P_X(K) &= \frac{1}{b-a} \cdot \int_K \mathbb I_{[a, b]} \, \mathrm d\lambda \equiv \frac{1}{b-a} \cdot \int_a^b \mathbb I_K(x) \, \mathrm dx. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmathbb+P_X%28K%29+%26%3D+%5Cfrac%7B1%7D%7Bb-a%7D+%5Ccdot+%5Cint_K+%5Cmathbb+I_%7B%5Ba%2C+b%5D%7D+%5C%2C+%5Cmathrm+d%5Clambda+%5Cequiv+%5Cfrac%7B1%7D%7Bb-a%7D+%5Ccdot+%5Cint_a%5Eb+%5Cmathbb+I_K%28x%29+%5C%2C+%5Cmathrm+dx.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Here, the probability density function is given by ![\displaystyle f_X = \frac{1}{b-a} \cdot \mathbb I_{[a,b]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f_X+%3D+%5Cfrac%7B1%7D%7Bb-a%7D+%5Ccdot+%5Cmathbb+I_%7B%5Ba%2Cb%5D%7D&bg=ffffff&fg=000&s=0&c=20201002)
As usual, 


The expected value and variance tends to be useful statistical quantities for our purposes. Nevertheless, there is a special expected value and a special variance that causes the rest of our calculations to become trivial.
Lemma 1. Suppose ![\mathbb E[X] = \mu](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%3D+%5Cmu&bg=ffffff&fg=000&s=0&c=20201002)



Then ![\mathbb E[\tilde X] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%5Ctilde+X%5D+%3D+0&bg=ffffff&fg=000&s=0&c=20201002)


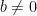

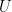



Furthermore, ![\mathbb E[X] = a + b \cdot \mathbb E[U]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%3D+a+%2B+b+%5Ccdot+%5Cmathbb+E%5BU%5D&bg=ffffff&fg=000&s=0&c=20201002)

Proof. For the p.d.f. result, by the fundamental theorem of calculus,

The other results follow from expectation and variance properties.
Theorem 1. If ![\mathbb E[X] = (a+b)/2](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%3D+%28a%2Bb%29%2F2&bg=ffffff&fg=000&s=0&c=20201002)

Proof. Let 
![\displaystyle f_X(x) = \frac{1}{b-a}\cdot \mathbb I_{[a, b]}(x) = \mathbb I_{[0, 1]} \left( \frac{x-a}{b-a} \right) \cdot \frac{1}{b-a}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f_X%28x%29+%3D+%5Cfrac%7B1%7D%7Bb-a%7D%5Ccdot+%5Cmathbb+I_%7B%5Ba%2C+b%5D%7D%28x%29+%3D++%5Cmathbb+I_%7B%5B0%2C+1%5D%7D+%5Cleft%28+%5Cfrac%7Bx-a%7D%7Bb-a%7D+%5Cright%29+%5Ccdot+%5Cfrac%7B1%7D%7Bb-a%7D&bg=ffffff&fg=000&s=0&c=20201002)
implies that

By definition,
![\begin{aligned} \mathbb E[U] &= \int_{-\infty}^{\infty} x \cdot \mathbb I_{[0,1]}(x)\, \mathrm dx = \int_{0}^{1} x\, \mathrm dx =\frac 12.\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BU%5D+%26%3D+%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D+x+%5Ccdot+%5Cmathbb+I_%7B%5B0%2C1%5D%7D%28x%29%5C%2C+%5Cmathrm+dx+%3D+%5Cint_%7B0%7D%5E%7B1%7D+x%5C%2C+%5Cmathrm+dx+%3D%5Cfrac+12.%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Similarly,
![\begin{aligned} \mathbb E[U^2] &= \int_{0}^{1} x^2\, \mathrm dx = \frac 13,\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BU%5E2%5D+%26%3D+%5Cint_%7B0%7D%5E%7B1%7D+x%5E2%5C%2C+%5Cmathrm+dx+%3D+%5Cfrac+13%2C%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
so that
![\displaystyle \mathrm{Var}(U) = \mathbb E[U^2] - \mathbb E[U]^2 = \frac 13 - \left(\frac 14\right)^2 = \frac 1{12}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7BVar%7D%28U%29+%3D+%5Cmathbb+E%5BU%5E2%5D+-+%5Cmathbb+E%5BU%5D%5E2+%3D+%5Cfrac+13+-+%5Cleft%28%5Cfrac+14%5Cright%29%5E2+%3D+%5Cfrac+1%7B12%7D.&bg=ffffff&fg=000&s=0&c=20201002)
Then the general case follows from
![\begin{aligned} \mathbb E[X] &= a + (b-a) \cdot \frac 12 = \frac{a+b}{2}, \\ \mathrm{Var}(X) &= (b-a)^2 \cdot \frac 1{12} = \frac{(b-a)^2}{12}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BX%5D+%26%3D+a+%2B+%28b-a%29+%5Ccdot+%5Cfrac+12+%3D+%5Cfrac%7Ba%2Bb%7D%7B2%7D%2C+%5C%5C+%5Cmathrm%7BVar%7D%28X%29+%26%3D+%28b-a%29%5E2+%5Ccdot+%5Cfrac+1%7B12%7D+%3D+%5Cfrac%7B%28b-a%29%5E2%7D%7B12%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
We can generalise Lemma 1 to any differentiable, invertible transformation of
Lemma 2. For any 


Proof. Apply the same arguments as in Lemma 1, but apply the chain rule.
The continuous analog of the geometric distribution would be the exponential distribution.
Theorem 2. The random variable 


![\mathbb E[X] = 1/\lambda](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%3D+1%2F%5Clambda&bg=ffffff&fg=000&s=0&c=20201002)

Proof. Let 

gives the final result. Integrating by parts,
![\begin{aligned}\mathbb E[U] &= \int_0^\infty xe^{-x}\, \mathrm dx \\ &= [-xe^{-x} - e^{-x}]_0^\infty \\ &= (0 - 0) - (0 - 1) = 1, \\ \mathbb E[U^2] &= \int_0^\infty x^2 e^{-x}\, \mathrm dx \\ &= \left[-x^2 e^{-x} \right]_0^\infty + 2\int_0^\infty x \cdot e^{-x}\, \mathrm dx \\ &= (0 - 0) + 2 \cdot \mathbb E[U] = 2,\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cmathbb+E%5BU%5D+%26%3D+%5Cint_0%5E%5Cinfty+xe%5E%7B-x%7D%5C%2C+%5Cmathrm+dx+%5C%5C+%26%3D+%5B-xe%5E%7B-x%7D+-+e%5E%7B-x%7D%5D_0%5E%5Cinfty+%5C%5C+%26%3D+%280+-+0%29+-+%280+-+1%29+%3D+1%2C+%5C%5C+%5Cmathbb+E%5BU%5E2%5D+%26%3D+%5Cint_0%5E%5Cinfty+x%5E2+e%5E%7B-x%7D%5C%2C+%5Cmathrm+dx+%5C%5C+%26%3D+%5Cleft%5B-x%5E2+e%5E%7B-x%7D+%5Cright%5D_0%5E%5Cinfty+%2B+2%5Cint_0%5E%5Cinfty+x+%5Ccdot+e%5E%7B-x%7D%5C%2C+%5Cmathrm+dx++%5C%5C+%26%3D+%280+-+0%29+%2B+2+%5Ccdot+%5Cmathbb+E%5BU%5D+%3D+2%2C%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
so that ![\mathrm{Var}(U) = \mathbb E[U^2] - \mathbb E[U]^2 = 2- 1^2 = 1](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BVar%7D%28U%29+%3D+%5Cmathbb+E%5BU%5E2%5D+-+%5Cmathbb+E%5BU%5D%5E2+%3D+2-+1%5E2+%3D+1&bg=ffffff&fg=000&s=0&c=20201002)
Another crucial distribution in probability and statistics is the normal distribution. It is a useful model to represent all kings of continuous data—heights of humans, test scores for exams, and even month-on-month returns on investment. Actually more is true—as long as we have a continuous nonzero function 
Lemma 3. For any continuous and integrable nonzero function 

where 
Theorem 3. The random variable 
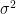


Then
Proof. Denoting 

so it suffices to prove that ![\mathbb E[Z] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BZ%5D+%3D+0&bg=ffffff&fg=000&s=0&c=20201002)




and a change of variables. The former is immediate since the function 
![\displaystyle \sqrt{2\pi} \cdot \mathbb E[Z] = \int_{-\infty}^{\infty} ze^{-z^2/2}\, \mathrm dz = 0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csqrt%7B2%5Cpi%7D+%5Ccdot+%5Cmathbb+E%5BZ%5D+%3D+%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D+ze%5E%7B-z%5E2%2F2%7D%5C%2C+%5Cmathrm+dz+%3D+0.&bg=ffffff&fg=000&s=0&c=20201002)
The latter requires integration by parts (here, as with the exponential distribution calculation, all integrals converge absolutely so we do not need to worry about the limits):
![\begin{aligned}\sqrt{2\pi} \cdot \mathbb E[Z^2] &= \int_{-\infty}^{\infty} z^2 e^{-z^2/2}\, \mathrm dz \\ &= \int_{-\infty}^{\infty} -z \cdot (-z e^{-z^2/2})\, \mathrm dz \\ &= \left[ -z \cdot e^{-z^2/2} \right]_{-\infty}^{\infty} - \int_{-\infty}^{\infty} (-1) \cdot e^{-z^2/2} \, \mathrm dz \\ &= (0 - 0) - (-1) \cdot \sqrt{2\pi} = \sqrt{2\pi}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Csqrt%7B2%5Cpi%7D+%5Ccdot+%5Cmathbb+E%5BZ%5E2%5D+%26%3D+%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D+z%5E2+e%5E%7B-z%5E2%2F2%7D%5C%2C+%5Cmathrm+dz+%5C%5C+%26%3D+%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D+-z+%5Ccdot+%28-z+e%5E%7B-z%5E2%2F2%7D%29%5C%2C+%5Cmathrm+dz+%5C%5C+%26%3D+%5Cleft%5B+-z+%5Ccdot+e%5E%7B-z%5E2%2F2%7D+%5Cright%5D_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D+-+%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D+%28-1%29+%5Ccdot+e%5E%7B-z%5E2%2F2%7D+%5C%2C+%5Cmathrm+dz+%5C%5C+%26%3D+%280+-+0%29+-+%28-1%29+%5Ccdot+%5Csqrt%7B2%5Cpi%7D+%3D+%5Csqrt%7B2%5Cpi%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Therefore,
![\mathrm{Var}(Z) = \mathbb E[Z^2] - \mathbb E[Z]^2 = 1 - 0^2 = 1.](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BVar%7D%28Z%29+%3D+%5Cmathbb+E%5BZ%5E2%5D+-+%5Cmathbb+E%5BZ%5D%5E2+%3D+1+-+0%5E2+%3D+1.&bg=ffffff&fg=000&s=0&c=20201002)
What makes the normal distribution so ubiquitous is how it arises from samples of virtually any distribution.
Theorem 4 (Central Limit Theorem). Let 



Then 
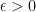



We say that 
Proof. Delayed.
Our main goal in these posts on probability is to prove this statement rigorously. The central limit theorem is responsible for our intuition about probability arising from repeated experiments.
A more immediate application comes from simulation. It turns out that the humble uniform random variable
Theorem 5. Suppose 


Proof. Let ![F_X := \mathbb P_0((-\infty, \cdot ])](https://s0.wp.com/latex.php?latex=F_X+%3A%3D+%5Cmathbb+P_0%28%28-%5Cinfty%2C+%5Ccdot+%5D%29&bg=ffffff&fg=000&s=0&c=20201002)
![F_X( \cdot ) \in [0, 1]](https://s0.wp.com/latex.php?latex=F_X%28+%5Ccdot+%29+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
![U \in [0, 1]](https://s0.wp.com/latex.php?latex=U+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)


To that end, define the measurable map

Then define 


Therefore, 
But we have a slightly more urgent question to answer: what’s the distribution of 
—Joel Kindiak. 19 Jul 25, 2258H

Leave a comment