Previously, we informally introduced some key ideas in probability that we will revisit when exploring the meat of the root—measure theory. Therein, we talked about the counting measure, which we will revisit for simplicity.
Theorem 1. Let 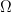 be a finite set and for any
be a finite set and for any  , let
, let  denote the number of elements in
denote the number of elements in  . Then for any
. Then for any  that do not share elements pair-wise (i.e. for
that do not share elements pair-wise (i.e. for 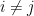 ,
,  ),
),

This is the first counting principle: the addition principle. Now we raise a seemingly obvious question: how do we count? When I read this I laughed. Shouldn’t we be beyond baby counting? Except that it’s not so obvious, and I’ll try to convince you why that’s the case in a moment.
Let’s analyse this peculiar expression:  . For
. For 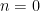 and
and 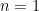 , we get trivial results:
, we get trivial results:

For 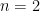 , we need to use the basic rules of expansion:
, we need to use the basic rules of expansion:

For  , we need to do it again, but using the case:
, we need to do it again, but using the case:

You may have seen the sequence of these sequences 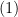 ,
,  ,
,  ,
,  in the first four rows of Pascal’s triangle:
in the first four rows of Pascal’s triangle:

This connection is no coincidence, and we might revisit this idea later on.
Now, here is my question: how do you expand  ? By observing the pattern, we can guess that this expansion will require
? By observing the pattern, we can guess that this expansion will require  terms, which will take…a long time. Indeed, we can formalise these patterns and more using the principle of mathematical induction and obtain the binomial theorem.
terms, which will take…a long time. Indeed, we can formalise these patterns and more using the principle of mathematical induction and obtain the binomial theorem.
Theorem 2 (Binomial Theorem). For any  ,
,

where  is the integer recursively defined by
is the integer recursively defined by

Proof. We have established the base case . For the inductive step,

However, how do we compute  ? We will use
? We will use  as our case-study, and in doing so, derive a more meaningful interpretation of and a relatively effective method to compute it.
as our case-study, and in doing so, derive a more meaningful interpretation of and a relatively effective method to compute it.
Let’s expand again. Intuitively,  , and when expanded, yields the sum of the following products:
, and when expanded, yields the sum of the following products:

For each  , notice that the coefficient of
, notice that the coefficient of 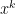 is exactly the number of arrangements of copies of
is exactly the number of arrangements of copies of  and
and  copies of
copies of  . We have particularised to here, but there is no reason to stop at
. We have particularised to here, but there is no reason to stop at 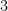 , unlike Singapore’s population planning post-WWII.
, unlike Singapore’s population planning post-WWII.
Let’s now discuss the idea of arrangements.
Theorem 2. Given finite sets  , an
, an  –arrangement is a finite sequence
–arrangement is a finite sequence  , where
, where  for each
for each  . Thus, the set of arrangements is defined by
. Thus, the set of arrangements is defined by

and the number of elements it has is given by

This is called the multiplication principle. In the special case  , we have
, we have  . An element of
. An element of  is called an –arrangement of objects in .
is called an –arrangement of objects in .
So what we are interested in the question is the collection of -arrangements of objects in  . Indeed, our suspicions are confirmed, since for the case, we did list out
. Indeed, our suspicions are confirmed, since for the case, we did list out 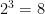 arrangements. But how do we “weed” out the coefficients of ? We need to find the arrangements of the objects
arrangements. But how do we “weed” out the coefficients of ? We need to find the arrangements of the objects

If we call this number and are able to compute this number, then immediately we recover the binomial theorem:

However, how do we actually compute ? For some nontrivial insight, let’s analyse the case  , so that we find the arrangements of the objects
, so that we find the arrangements of the objects

If we treated all of these object as different from one another, we aim to find arrangements of the objects

Crucially, we want to arrange these objects without repetitions. We call such arrangements permutations.
Let  be a finite set with distinct elements.
be a finite set with distinct elements.
Theorem 3. An arrangement of objects in a set is called a permutation of if for any ,  . Then the number of permutations is given by
. Then the number of permutations is given by 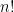 , called –factorial, defined by
, called –factorial, defined by

Proof. For convenience, define  and for any
and for any  ,
,

Then it is clear that

We will prove the claim inductively on . For the base case, the one and only permutation of  is
is  . Therefore, the number of permutations is
. Therefore, the number of permutations is  .
.
Now for the inductive step, consider a set  of
of 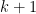 distinct elements. There are possible choices for the last term
distinct elements. There are possible choices for the last term  in the sequence. Now the set
in the sequence. Now the set  has elements. By the induction hypothesis, there are
has elements. By the induction hypothesis, there are  permutations of the elements in the first slots. By the multiplication principle, the total number of permutations is
permutations of the elements in the first slots. By the multiplication principle, the total number of permutations is

as required.
Corollary 1. The number of permutations of  is
is  and the number of permutations of
and the number of permutations of  is
is 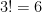 .
.
Proof. We have  and
and  .
.
We are almost there. We observe that given these labels, the permutations

are distinct. However, if we recall that  are placeholders for and
are placeholders for and  are placeholders for , then we obtain the identical permutations
are placeholders for , then we obtain the identical permutations

In fact, we can flip the question: how many permutations correspond to the overarching arrangement  ? It would be the contribution of all permutations of and all permutations of
? It would be the contribution of all permutations of and all permutations of  . If there are
. If there are  overarching arrangements of copies of and
overarching arrangements of copies of and  copies of , then the multiplication principle yields
copies of , then the multiplication principle yields

Extending this reasoning to copies of and copies of yields the computation of the binomial coefficient.
Theorem 4. For any and  with
with  , the -th binomial coefficient is given by
, the -th binomial coefficient is given by  .
.
Intriguingly, these two quantities, the factorial and binomial coefficient help us discuss more about permutations and combinations.
Definition 1. Let  be a set of elements. For integers
be a set of elements. For integers  , a –combination of is a subset of (so that the collection of combinations of is
, a –combination of is a subset of (so that the collection of combinations of is  ) and a –permutation is a permutation of some -combination of .
) and a –permutation is a permutation of some -combination of .
Given , how many -combinations are there? Furthermore, how many -permutations are there? We have seen that the number of -permutations is , and clearly the number of -combinations is . More concretely, given , we want to count

Our key idea is as follows: fix  such that
such that  . Form a sequence of and as follows: declare the -th term to be if
. Form a sequence of and as follows: declare the -th term to be if  and otherwise. We formalise this construction in Lemma 1 below:
and otherwise. We formalise this construction in Lemma 1 below:
Lemma 1. For any , define  by
by

Then the map  defined by
defined by  is bijective.
is bijective.
In particular,  corresponds to the number of arrangements of copies of and
corresponds to the number of arrangements of copies of and  copies of . But we have computed this number already—it is . Hence, we have the following result.
copies of . But we have computed this number already—it is . Hence, we have the following result.
Theorem 5. The number of -combinations of a set of distinct elements is . The number of -permutations of the same set of elements is  .
.
Proof. The first claim follows from

For the second claim, we first have choices of -combinations, followed by permutations of the elements in each -combination. The result follows from the multiplication principle.
There is a lot more that can be said about counting, studied in a much broader field called combinatorics. For now, we have convinced ourselves (somewhat) that we are able to compute for various kinds of sets , be it collections of permutations or combinations, with repetitions or otherwise.
—Joel Kindiak, 24 Jun 25, 1810H



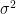


![\mathbb E[X]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D&bg=ffffff&fg=000&s=0&c=20201002)

![\mathrm{Cov}(X, Y) = \mathbb E[(X - \mathbb E[X]) \cdot (Y - \mathbb E[Y])].](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BCov%7D%28X%2C+Y%29+%3D+%5Cmathbb+E%5B%28X+-+%5Cmathbb+E%5BX%5D%29+%5Ccdot+%28Y+-+%5Cmathbb+E%5BY%5D%29%5D.&bg=ffffff&fg=000&s=0&c=20201002)
![\mathrm{Cov}(X, Y) = \mathbb E[XY] - \mathbb E[X]\cdot \mathbb E[Y].](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BCov%7D%28X%2C+Y%29+%3D+%5Cmathbb+E%5BXY%5D+-+%5Cmathbb+E%5BX%5D%5Ccdot+%5Cmathbb+E%5BY%5D.&bg=ffffff&fg=000&s=0&c=20201002)
![\begin{aligned}(X - \mathbb E[X]) \cdot (Y - \mathbb E[Y]) &= XY - \mathbb E[X] \cdot Y - \mathbb E[Y] \cdot X + \mathbb E[X] \cdot \mathbb E[Y].\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%28X+-+%5Cmathbb+E%5BX%5D%29+%5Ccdot+%28Y+-+%5Cmathbb+E%5BY%5D%29+%26%3D+XY+-+%5Cmathbb+E%5BX%5D+%5Ccdot+Y+-+%5Cmathbb+E%5BY%5D+%5Ccdot+X+%2B+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D.%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\mathbb E[\cdot]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%5Ccdot%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\begin{aligned} \mathrm{Cov}(X, Y) &= \mathbb E[(X - \mathbb E[X]) \cdot (Y - \mathbb E[Y])] \\ &=\mathbb E[XY - \mathbb E[X] \cdot Y - \mathbb E[Y] \cdot X + \mathbb E[X] \cdot \mathbb E[Y]] \\ &= \mathbb E[XY] - \mathbb E[\mathbb E[X] \cdot Y] - \mathbb E[\mathbb E[Y] \cdot X] + \mathbb E[\mathbb E[X] \cdot \mathbb E[Y]] \\ &= \mathbb E[XY] - \mathbb E[X] \cdot \mathbb E[Y] - \mathbb E[Y] \cdot \mathbb E[X] + \mathbb E[X] \cdot \mathbb E[Y] \cdot \mathbb E[1] \\ &= \mathbb E[XY] - \mathbb E[X] \cdot \mathbb E[Y]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathrm%7BCov%7D%28X%2C+Y%29+%26%3D+%5Cmathbb+E%5B%28X+-+%5Cmathbb+E%5BX%5D%29+%5Ccdot+%28Y+-+%5Cmathbb+E%5BY%5D%29%5D+%5C%5C+%26%3D%5Cmathbb+E%5BXY+-+%5Cmathbb+E%5BX%5D+%5Ccdot+Y+-+%5Cmathbb+E%5BY%5D+%5Ccdot+X+%2B+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D%5D+%5C%5C+%26%3D+%5Cmathbb+E%5BXY%5D+-+%5Cmathbb+E%5B%5Cmathbb+E%5BX%5D+%5Ccdot+Y%5D+-+%5Cmathbb+E%5B%5Cmathbb+E%5BY%5D+%5Ccdot+X%5D+%2B+%5Cmathbb+E%5B%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D%5D+%5C%5C+%26%3D+%5Cmathbb+E%5BXY%5D+-+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D+-+%5Cmathbb+E%5BY%5D+%5Ccdot+%5Cmathbb+E%5BX%5D+%2B+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D+%5Ccdot+%5Cmathbb+E%5B1%5D+%5C%5C+%26%3D+%5Cmathbb+E%5BXY%5D+-+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
,
if and only if
,
,
for
,
.
![\begin{aligned}\mathrm{Cov}(W+X, Y) &= \mathbb E[(W+X)Y] - \mathbb E[W+X] \cdot \mathbb E[Y] \\ &= \mathbb E[WY+XY] - (\mathbb E[W]+\mathbb E[X]) \cdot \mathbb E[Y] \\ &= \mathbb E[WY]+\mathbb E[XY] - (\mathbb E[W] \cdot \mathbb E[Y]+\mathbb E[X] \cdot \mathbb E[Y]) \\ &= \mathbb E[WY] - \mathbb E[W] \cdot \mathbb E[Y] +\mathbb E[XY] - \mathbb E[X] \cdot \mathbb E[Y] \\ &= \mathrm{Cov}(W,Y) + \mathrm{Cov}(X,Y). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cmathrm%7BCov%7D%28W%2BX%2C+Y%29+%26%3D+%5Cmathbb+E%5B%28W%2BX%29Y%5D+-+%5Cmathbb+E%5BW%2BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D+%5C%5C+%26%3D+%5Cmathbb+E%5BWY%2BXY%5D+-+%28%5Cmathbb+E%5BW%5D%2B%5Cmathbb+E%5BX%5D%29+%5Ccdot+%5Cmathbb+E%5BY%5D+%5C%5C+%26%3D+%5Cmathbb+E%5BWY%5D%2B%5Cmathbb+E%5BXY%5D+-+%28%5Cmathbb+E%5BW%5D+%5Ccdot+%5Cmathbb+E%5BY%5D%2B%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D%29+%5C%5C+%26%3D+%5Cmathbb+E%5BWY%5D+-+%5Cmathbb+E%5BW%5D+%5Ccdot+%5Cmathbb+E%5BY%5D+%2B%5Cmathbb+E%5BXY%5D+-+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D+%5C%5C+%26%3D+%5Cmathrm%7BCov%7D%28W%2CY%29+%2B+%5Cmathrm%7BCov%7D%28X%2CY%29.++%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)



![\mathrm{Cov}(k, Y) = \mathbb E[k Y] - \mathbb E[k] \cdot \mathbb E[Y] = k \cdot \mathbb E[Y] - k \cdot \mathbb E[Y] = 0.](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BCov%7D%28k%2C+Y%29+%3D+%5Cmathbb+E%5Bk+Y%5D+-+%5Cmathbb+E%5Bk%5D+%5Ccdot+%5Cmathbb+E%5BY%5D+%3D+k+%5Ccdot+%5Cmathbb+E%5BY%5D+-+k+%5Ccdot+%5Cmathbb+E%5BY%5D+%3D+0.&bg=ffffff&fg=000&s=0&c=20201002)
![\mathrm{Var}(X) := \mathrm{Cov}(X,X) = \mathbb E[X^2] - \mathbb E[X]^2](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BVar%7D%28X%29+%3A%3D+%5Cmathrm%7BCov%7D%28X%2CX%29+%3D+%5Cmathbb+E%5BX%5E2%5D+-+%5Cmathbb+E%5BX%5D%5E2&bg=ffffff&fg=000&s=0&c=20201002)


![\mu_X := \mathbb E[X]](https://s0.wp.com/latex.php?latex=%5Cmu_X+%3A%3D+%5Cmathbb+E%5BX%5D&bg=ffffff&fg=000&s=0&c=20201002)















![\begin{aligned} \mathbb E[XY] &= \sum_{\omega \in \Omega} X(\omega) \cdot Y(\omega) \cdot \mathbb P(\{\omega\}) \\ &= \sum_{i=1}^n x_i \cdot y_i \cdot \frac 1n = \frac{ 1 }{n} \sum_{i=1}^n x_i y_i. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BXY%5D+%26%3D+%5Csum_%7B%5Comega+%5Cin+%5COmega%7D+X%28%5Comega%29+%5Ccdot+Y%28%5Comega%29+%5Ccdot+%5Cmathbb+P%28%5C%7B%5Comega%5C%7D%29+%5C%5C+%26%3D+%5Csum_%7Bi%3D1%7D%5En+x_i+%5Ccdot+y_i+%5Ccdot+%5Cfrac+1n+%3D+%5Cfrac%7B+1+%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5En+x_i+y_i.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)





![\mathbb E[X+Y] = \mathbb E[X] + \mathbb E[Y]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%2BY%5D+%3D+%5Cmathbb+E%5BX%5D+%2B+%5Cmathbb+E%5BY%5D&bg=ffffff&fg=000&s=0&c=20201002)




![\mathbb E[XY] = \mathbb E[X] \cdot \mathbb E[Y].](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BXY%5D+%3D+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D.&bg=ffffff&fg=000&s=0&c=20201002)

![\begin{aligned} \mathbb E[XY] &= \sum_{x \in \mathbb Z} \sum_{y \in \mathbb Z} xy \cdot \mathbb P_{X,Y}(x,y) \\ &= \sum_{x \in \mathbb Z} \sum_{y \in \mathbb Z} x \cdot y \cdot \mathbb P_X(x) \cdot \mathbb P_Y(y) \\ &= \sum_{x \in \mathbb Z} x \cdot \mathbb P_X(x) \cdot \sum_{y \in \mathbb Z} y \cdot \mathbb P_Y(y) = \mathbb E[X] \cdot \mathbb E[Y]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BXY%5D+%26%3D+%5Csum_%7Bx+%5Cin+%5Cmathbb+Z%7D+%5Csum_%7By+%5Cin+%5Cmathbb+Z%7D+xy+%5Ccdot+%5Cmathbb+P_%7BX%2CY%7D%28x%2Cy%29+%5C%5C+%26%3D+%5Csum_%7Bx+%5Cin+%5Cmathbb+Z%7D+%5Csum_%7By+%5Cin+%5Cmathbb+Z%7D+x+%5Ccdot+y+%5Ccdot+%5Cmathbb+P_X%28x%29+%5Ccdot+%5Cmathbb+P_Y%28y%29+%5C%5C+%26%3D+%5Csum_%7Bx+%5Cin+%5Cmathbb+Z%7D+x+%5Ccdot+%5Cmathbb+P_X%28x%29+%5Ccdot+%5Csum_%7By+%5Cin+%5Cmathbb+Z%7D+y+%5Ccdot+%5Cmathbb+P_Y%28y%29+%3D+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)







![\mathrm{Var}( \xi) = \mathbb E[ \xi^2] - \mathbb E[ \xi]^2 = p - p^2 = p(1-p).](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BVar%7D%28+%5Cxi%29+%3D+%5Cmathbb+E%5B+%5Cxi%5E2%5D+-+%5Cmathbb+E%5B+%5Cxi%5D%5E2+%3D+p+-+p%5E2+%3D+p%281-p%29.&bg=ffffff&fg=000&s=0&c=20201002)






![\mathbb E[\bar X_n] = \mu](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%5Cbar+X_n%5D+%3D+%5Cmu&bg=ffffff&fg=000&s=0&c=20201002)


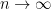


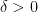
![\displaystyle \mathbb P(Y \geq \delta) \leq \frac{ \mathbb E[Y] }{ \delta }.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+P%28Y+%5Cgeq+%5Cdelta%29+%5Cleq+%5Cfrac%7B+%5Cmathbb+E%5BY%5D+%7D%7B+%5Cdelta+%7D.&bg=ffffff&fg=000&s=0&c=20201002)
![\begin{aligned} \mathbb E[Y] &= \sum_{y \in \mathbb Z} y \cdot \mathbb P_Y(y) \\ &= \sum_{y < \delta} y \cdot \mathbb P_Y(y) + \sum_{y \geq \delta} y \cdot \mathbb P_Y(y) \\ &\geq \sum_{y < \delta} 0 \cdot \mathbb P_Y(y) + \sum_{y \geq \delta} \delta \cdot \mathbb P_Y(y) \\ &= \delta \cdot \sum_{y \geq \delta} \mathbb P_Y(y) = \delta \cdot \mathbb P(Y \geq \delta). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BY%5D+%26%3D+%5Csum_%7By+%5Cin+%5Cmathbb+Z%7D+y+%5Ccdot+%5Cmathbb+P_Y%28y%29+%5C%5C+%26%3D+%5Csum_%7By+%3C+%5Cdelta%7D+y+%5Ccdot+%5Cmathbb+P_Y%28y%29+%2B+%5Csum_%7By+%5Cgeq+%5Cdelta%7D+y+%5Ccdot+%5Cmathbb+P_Y%28y%29+%5C%5C+%26%5Cgeq+%5Csum_%7By+%3C+%5Cdelta%7D+0+%5Ccdot+%5Cmathbb+P_Y%28y%29+%2B+%5Csum_%7By+%5Cgeq+%5Cdelta%7D+%5Cdelta+%5Ccdot+%5Cmathbb+P_Y%28y%29+%5C%5C+%26%3D+%5Cdelta+%5Ccdot+%5Csum_%7By+%5Cgeq+%5Cdelta%7D+%5Cmathbb+P_Y%28y%29+%3D+%5Cdelta+%5Ccdot+%5Cmathbb+P%28Y+%5Cgeq+%5Cdelta%29.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\mathbb P(Y \geq \delta) \leq \mathbb E[Y]/\delta](https://s0.wp.com/latex.php?latex=%5Cmathbb+P%28Y+%5Cgeq+%5Cdelta%29+%5Cleq+%5Cmathbb+E%5BY%5D%2F%5Cdelta&bg=ffffff&fg=000&s=0&c=20201002)


![\mathbb E[Y] = \mathrm{Var}(X) = \sigma^2](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BY%5D+%3D+%5Cmathrm%7BVar%7D%28X%29+%3D+%5Csigma%5E2&bg=ffffff&fg=000&s=0&c=20201002)
![\begin{aligned}\mathbb P(|X - \mu| \geq \delta) &= \mathbb P(|X - \mu|^2 \geq \delta^2) = \mathbb P(Y \geq \delta^2) \leq \frac{\mathbb E[Y]}{\delta^2} = \frac{\sigma^2}{\delta^2}.\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cmathbb+P%28%7CX+-+%5Cmu%7C+%5Cgeq+%5Cdelta%29+%26%3D+%5Cmathbb+P%28%7CX+-+%5Cmu%7C%5E2+%5Cgeq+%5Cdelta%5E2%29+%3D+%5Cmathbb+P%28Y+%5Cgeq+%5Cdelta%5E2%29+%5Cleq+%5Cfrac%7B%5Cmathbb+E%5BY%5D%7D%7B%5Cdelta%5E2%7D+%3D+%5Cfrac%7B%5Csigma%5E2%7D%7B%5Cdelta%5E2%7D.%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
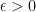







 , what is its expectation, if it exists?
, what is its expectation, if it exists?
 . The expectation of
. The expectation of  will induce a “weight” of
will induce a “weight” of  that tilts the beam anticlockwise, and similarly, each
that tilts the beam anticlockwise, and similarly, each  will induce a “weight” of
will induce a “weight” of 


 and
and  for brevity,
for brevity,
 is finite. This quantity we will formally define as the expectation, if the sum exists (even if the sum is infinite).
is finite. This quantity we will formally define as the expectation, if the sum exists (even if the sum is infinite).![\displaystyle \mathbb E[X] := \sum_{x \in \mathbb Z} x \cdot \mathbb P_X(x)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5BX%5D+%3A%3D+%5Csum_%7Bx+%5Cin+%5Cmathbb+Z%7D+x+%5Ccdot+%5Cmathbb+P_X%28x%29&bg=ffffff&fg=000&s=0&c=20201002)
![p \in [0, 1]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) , if
, if  , then
, then![\begin{aligned} \mathbb E[X] &= 0 \cdot \mathbb P_X(0) + 1 \cdot \mathbb P_X(1) \\ &= 0 \cdot (1-p) + 1 \cdot p = p. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BX%5D+%26%3D+0+%5Ccdot+%5Cmathbb+P_X%280%29+%2B+1+%5Ccdot+%5Cmathbb+P_X%281%29+%5C%5C+%26%3D+0+%5Ccdot+%281-p%29+%2B+1+%5Ccdot+p+%3D+p.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
 be a probability space and
be a probability space and  be a random variable. Then
be a random variable. Then
![\displaystyle \mathbb E[X] = \sum_{\omega \in \Omega} X(\omega) \cdot \mathbb P(\{ \omega \}).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5BX%5D+%3D+%5Csum_%7B%5Comega+%5Cin+%5COmega%7D+X%28%5Comega%29+%5Ccdot+%5Cmathbb+P%28%5C%7B+%5Comega+%5C%7D%29.&bg=ffffff&fg=000&s=0&c=20201002)


 ,
,  is a
is a ![\mathbb E[g(X)]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5Bg%28X%29%5D&bg=ffffff&fg=000&s=0&c=20201002) exists, then
exists, then![\displaystyle \mathbb E[g(X)] = \sum_{x \in \mathbb Z} g(x) \cdot \mathbb P_X(x),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5Bg%28X%29%5D+%3D+%5Csum_%7Bx+%5Cin+%5Cmathbb+Z%7D+g%28x%29+%5Ccdot+%5Cmathbb+P_X%28x%29%2C&bg=ffffff&fg=000&s=0&c=20201002)
 by Lemma 2, the proof and result in Lemma 1 yields
by Lemma 2, the proof and result in Lemma 1 yields![\begin{aligned} \mathbb E[g(X)] = \mathbb E[Y] &= \sum_{\omega \in \Omega} Y(\omega) \cdot \mathbb P(\{\omega\}) \\ &= \sum_{\omega \in \Omega} g(X(\omega)) \cdot \mathbb P(\{\omega\}) \\ &= \sum_{\omega \in \Omega} \sum_{x \in \mathbb Z} g(X(\omega)) \cdot \mathbb I\{X(\omega) = x\} \cdot \mathbb P(\{\omega\}) \\ &= \sum_{x \in \mathbb Z} \sum_{\omega \in \Omega} g(X(\omega)) \cdot \mathbb I\{X(\omega) = x\} \cdot \mathbb P(\{\omega\}) \\ &= \sum_{x \in \mathbb Z} g(x) \cdot \sum_{\omega \in \Omega} \mathbb I\{X(\omega) = x\} \cdot \mathbb P(\{\omega\}) \\ &= \sum_{x \in \mathbb Z} g(x) \cdot \mathbb P_X(x). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5Bg%28X%29%5D+%3D+%5Cmathbb+E%5BY%5D+%26%3D+%5Csum_%7B%5Comega+%5Cin++%5COmega%7D+Y%28%5Comega%29+%5Ccdot+%5Cmathbb+P%28%5C%7B%5Comega%5C%7D%29+%5C%5C+%26%3D+%5Csum_%7B%5Comega+%5Cin++%5COmega%7D+g%28X%28%5Comega%29%29+%5Ccdot+%5Cmathbb+P%28%5C%7B%5Comega%5C%7D%29+%5C%5C+%26%3D+%5Csum_%7B%5Comega+%5Cin++%5COmega%7D+%5Csum_%7Bx+%5Cin+%5Cmathbb+Z%7D+g%28X%28%5Comega%29%29+%5Ccdot+%5Cmathbb+I%5C%7BX%28%5Comega%29+%3D+x%5C%7D+%5Ccdot+%5Cmathbb+P%28%5C%7B%5Comega%5C%7D%29+%5C%5C+%26%3D+%5Csum_%7Bx+%5Cin+%5Cmathbb+Z%7D+%5Csum_%7B%5Comega+%5Cin++%5COmega%7D+g%28X%28%5Comega%29%29+%5Ccdot+%5Cmathbb+I%5C%7BX%28%5Comega%29+%3D+x%5C%7D+%5Ccdot+%5Cmathbb+P%28%5C%7B%5Comega%5C%7D%29+%5C%5C+%26%3D+%5Csum_%7Bx+%5Cin+%5Cmathbb+Z%7D+g%28x%29+%5Ccdot+%5Csum_%7B%5Comega+%5Cin++%5COmega%7D+%5Cmathbb+I%5C%7BX%28%5Comega%29+%3D+x%5C%7D+%5Ccdot+%5Cmathbb+P%28%5C%7B%5Comega%5C%7D%29+%5C%5C+%26%3D+%5Csum_%7Bx+%5Cin+%5Cmathbb+Z%7D+g%28x%29+%5Ccdot+%5Cmathbb+P_X%28x%29.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
 ,
,  is a
is a ![\displaystyle \mathbb E[g(X,Y)] = \sum_{(x, y) \in \mathbb Z^2} g(x,y) \cdot \mathbb P_{X,Y}(x,y).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5Bg%28X%2CY%29%5D+%3D+%5Csum_%7B%28x%2C+y%29+%5Cin+%5Cmathbb+Z%5E2%7D+g%28x%2Cy%29+%5Ccdot+%5Cmathbb+P_%7BX%2CY%7D%28x%2Cy%29.&bg=ffffff&fg=000&s=0&c=20201002)
![\mathbb E[X], \mathbb E[Y]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D%2C+%5Cmathbb+E%5BY%5D&bg=ffffff&fg=000&s=0&c=20201002) exist, then the following hold:
exist, then the following hold:![\mathbb E[X + Y] = \mathbb E[X] + \mathbb E[Y]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX+%2B+Y%5D+%3D+%5Cmathbb+E%5BX%5D+%2B+%5Cmathbb+E%5BY%5D&bg=ffffff&fg=000&s=0&c=20201002) ,
,![\mathbb E[\alpha X] = \alpha \cdot \mathbb E[X]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%5Calpha+X%5D+%3D+%5Calpha+%5Ccdot+%5Cmathbb+E%5BX%5D&bg=ffffff&fg=000&s=0&c=20201002) for any
for any  ,
,![\mathbb E[X - \mathbb E[X]] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX+-+%5Cmathbb+E%5BX%5D%5D+%3D+0&bg=ffffff&fg=000&s=0&c=20201002) .
. . Then
. Then![\begin{aligned} \mathbb E[g(X,Y)] &= \sum_{(x, y) \in \mathbb Z^2} g(x,y) \cdot \mathbb P_{X,Y}(x,y) \\ \mathbb E[X+Y]&= \sum_{(x, y) \in \mathbb Z^2} (x+y) \cdot \mathbb P_{X,Y}(x,y) \\ &= \sum_{(x, y) \in \mathbb Z^2} x \cdot \mathbb P_{X,Y}(x,y) + \sum_{(x, y) \in \mathbb Z^2} y \cdot \mathbb P_{X,Y}(x,y) \\ &= \sum_{x \in \mathbb Z} x \cdot \mathbb P_{X}(x) + \sum_{y \in \mathbb Z} y \cdot \mathbb P_{Y}(y) \\ &= \mathbb E[X] + \mathbb E[Y], \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5Bg%28X%2CY%29%5D+%26%3D+%5Csum_%7B%28x%2C+y%29+%5Cin+%5Cmathbb+Z%5E2%7D+g%28x%2Cy%29+%5Ccdot+%5Cmathbb+P_%7BX%2CY%7D%28x%2Cy%29+%5C%5C+%5Cmathbb+E%5BX%2BY%5D%26%3D+%5Csum_%7B%28x%2C+y%29+%5Cin+%5Cmathbb+Z%5E2%7D+%28x%2By%29+%5Ccdot+%5Cmathbb+P_%7BX%2CY%7D%28x%2Cy%29+%5C%5C+%26%3D+%5Csum_%7B%28x%2C+y%29+%5Cin+%5Cmathbb+Z%5E2%7D+x+%5Ccdot+%5Cmathbb+P_%7BX%2CY%7D%28x%2Cy%29+%2B+%5Csum_%7B%28x%2C+y%29+%5Cin+%5Cmathbb+Z%5E2%7D+y+%5Ccdot+%5Cmathbb+P_%7BX%2CY%7D%28x%2Cy%29+%5C%5C+%26%3D+%5Csum_%7Bx+%5Cin+%5Cmathbb+Z%7D+x+%5Ccdot+%5Cmathbb+P_%7BX%7D%28x%29+%2B+%5Csum_%7By+%5Cin+%5Cmathbb+Z%7D+y+%5Ccdot+%5Cmathbb+P_%7BY%7D%28y%29+%5C%5C+%26%3D+%5Cmathbb+E%5BX%5D+%2B+%5Cmathbb+E%5BY%5D%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)

 and
and  , then
, then ![\mathbb E[X] = np](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%3D+np&bg=ffffff&fg=000&s=0&c=20201002) .
. such that
such that
![\displaystyle \mathbb E[X] = \mathbb E\left[ \sum_{i=1}^n \xi_i \right] = \sum_{i=1}^n \mathbb E[\xi_i] = \sum_{i=1}^n p = np.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5BX%5D+%3D+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bi%3D1%7D%5En+%5Cxi_i+%5Cright%5D+%3D+%5Csum_%7Bi%3D1%7D%5En+%5Cmathbb+E%5B%5Cxi_i%5D+%3D+%5Csum_%7Bi%3D1%7D%5En+p+%3D+np.&bg=ffffff&fg=000&s=0&c=20201002)
 with the uniform probability measure and induced random variable
with the uniform probability measure and induced random variable  . Then
. Then![\begin{aligned} \mathbb E[X] &= \sum_{x \in \mathbb Z} x \cdot \mathbb P_X(x) \\ &= \sum_{i=1}^n x_i \cdot \mathbb P_X(x_i) \\ &= \sum_{i=1}^n x_i \cdot \frac 1n = \frac 1n \cdot \sum_{i=1}^n x_i =: \bar x. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BX%5D+%26%3D+%5Csum_%7Bx+%5Cin+%5Cmathbb+Z%7D+x+%5Ccdot+%5Cmathbb+P_X%28x%29+%5C%5C+%26%3D+%5Csum_%7Bi%3D1%7D%5En+x_i+%5Ccdot+%5Cmathbb+P_X%28x_i%29+%5C%5C+%26%3D+%5Csum_%7Bi%3D1%7D%5En+x_i+%5Ccdot+%5Cfrac+1n+%3D+%5Cfrac+1n+%5Ccdot+%5Csum_%7Bi%3D1%7D%5En+x_i+%3D%3A+%5Cbar+x.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
 ), what is the distribution of their sum
), what is the distribution of their sum  ? This question is highly nontrivial, and is worth some elementary experimentation.
? This question is highly nontrivial, and is worth some elementary experimentation. and
and  . Using ordered-pair notation,
. Using ordered-pair notation,  . In this case,
. In this case,  . Furthermore, if
. Furthermore, if  , so that there is, in a sense, only one possible case to handle. Therefore, at least informally,
, so that there is, in a sense, only one possible case to handle. Therefore, at least informally,
 ? If we insist (rather intuitively) that
? If we insist (rather intuitively) that
 , i.e. the joint distribution of
, i.e. the joint distribution of  be discrete random variables. The product map
be discrete random variables. The product map  defined by
defined by
 , and induces a push-forward measure
, and induces a push-forward measure ![\mathbb P_{\mathbf X_n} : \mathcal P(\mathbb Z^n) \to [0, 1]](https://s0.wp.com/latex.php?latex=%5Cmathbb+P_%7B%5Cmathbf+X_n%7D+%3A+%5Cmathcal+P%28%5Cmathbb+Z%5En%29+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) defined by
defined by
 shares many properties of discrete random variables, its range is not a subset of
shares many properties of discrete random variables, its range is not a subset of 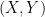 ? That is, what is the value of
? That is, what is the value of
 ? Perhaps
? Perhaps  could be defined arbitrarily, as long as we have each value in
could be defined arbitrarily, as long as we have each value in ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) and
and
 with
with  ,
,
 with
with  ,
,
 , the conditional probability
, the conditional probability ![\displaystyle \mathbb P( \cdot \mid Y = y ) : \mathcal F \to [0, 1]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+P%28+%5Ccdot++%5Cmid++Y+%3D+y+%29++%3A+%5Cmathcal+F+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\mathbb P( X \in \cdot \mid Y = y ) : \mathcal P(\mathbb Z) \to [0, 1].](https://s0.wp.com/latex.php?latex=%5Cmathbb+P%28+X+%5Cin+%5Ccdot++%5Cmid++Y+%3D+y+%29+%3A+%5Cmathcal+P%28%5Cmathbb+Z%29+%5Cto+%5B0%2C+1%5D.&bg=ffffff&fg=000&s=0&c=20201002)


 are independent for any
are independent for any  , then
, then
 are independent if for any
are independent if for any  , the events
, the events  are independent. In this case,
are independent. In this case,

 .
.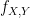 is given by
is given by
 . Hence,
. Hence,
 is evaluated by summing the cases of
is evaluated by summing the cases of 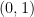 and
and 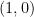 . More generally, we have
. More generally, we have
 and
and  . Time to generalise!
. Time to generalise! be discrete random variables. Given any function
be discrete random variables. Given any function  exists and is given by the distribution
exists and is given by the distribution


 are independent,
are independent,  has a distribution given by
has a distribution given by
 is given by
is given by
 ,
,
 . Then
. Then  . By the discrete convolution and Pascal’s identity,
. By the discrete convolution and Pascal’s identity,
 , denoted
, denoted  such that
such that
 .
. and
and  are independent, then
are independent, then  .
. such that
such that


 and the uniform probability measure on
and the uniform probability measure on  by
by  . Since
. Since 
 , not in the measurement
, not in the measurement  (though the former inevitably influences the latter). The quantity
(though the former inevitably influences the latter). The quantity 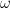 ), nor a variable (though that is captured by
), nor a variable (though that is captured by  and
and  be measurable spaces.
be measurable spaces. is
is  –measurable if for any
–measurable if for any  ,
,  . We omit the prefix
. We omit the prefix 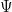 is equipped with the
is equipped with the  .
. ,
,
 on
on ![\mathbb P_X := \mathbb P \circ X^{-1} : \mathcal G \to [0, 1]](https://s0.wp.com/latex.php?latex=%5Cmathbb+P_X+%3A%3D+%5Cmathbb+P+%5Ccirc+X%5E%7B-1%7D+%3A+%5Cmathcal+G+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) is a probability measure on the measurable space
is a probability measure on the measurable space  , called the push-forward measure of
, called the push-forward measure of  . Eventually, we will want to develop measures on
. Eventually, we will want to develop measures on  too, though that will take substantially more effort.
too, though that will take substantially more effort.
 . Since we equipped
. Since we equipped  the distribution of
the distribution of  ,
,
 and that with respect to this choice,
and that with respect to this choice,  .
. .
.![\mathbb P_X^{-1}((0, 1])](https://s0.wp.com/latex.php?latex=%5Cmathbb+P_X%5E%7B-1%7D%28%280%2C+1%5D%29&bg=ffffff&fg=000&s=0&c=20201002) . The probability mass function or p.m.f. of
. The probability mass function or p.m.f. of  . The cumulative distribution function or c.d.f. of
. The cumulative distribution function or c.d.f. of ![\displaystyle F_X : \mathbb R \to [0, 1],\quad F_X(x) := \mathbb P(X \leq x) \equiv \sum_{t = 0}^{\lfloor x \rfloor} f_X(t).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F_X+%3A+%5Cmathbb+R+%5Cto+%5B0%2C+1%5D%2C%5Cquad+F_X%28x%29+%3A%3D+%5Cmathbb+P%28X+%5Cleq+x%29+%5Cequiv+%5Csum_%7Bt+%3D+0%7D%5E%7B%5Clfloor+x+%5Crfloor%7D+f_X%28t%29.&bg=ffffff&fg=000&s=0&c=20201002)
 , which may or may not be
, which may or may not be 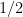 .
. equipped with the
equipped with the  . Define the probability measure
. Define the probability measure ![\mathbb P : \mathcal F \to [0, 1]](https://s0.wp.com/latex.php?latex=%5Cmathbb+P+%3A+%5Cmathcal+F+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) by
by  , which implies that
, which implies that
 and
and  . Then
. Then
 for
for  .
.
 . The random variable
. The random variable  has the distribution
has the distribution  since
since
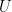 is uniform on
is uniform on ![(a, b]](https://s0.wp.com/latex.php?latex=%28a%2C+b%5D&bg=ffffff&fg=000&s=0&c=20201002) given integers
given integers  if
if![\displaystyle \mathbb P(U = u) = \frac{1}{b-a},\quad u \in (a, b] \cap \mathbb N.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+P%28U+%3D+u%29+%3D+%5Cfrac%7B1%7D%7Bb-a%7D%2C%5Cquad+u+%5Cin+%28a%2C+b%5D+%5Ccap+%5Cmathbb+N.&bg=ffffff&fg=000&s=0&c=20201002)
 . But what if
. But what if  be a probability space.
be a probability space.  . Then the map
. Then the map![\displaystyle \mathbb P( \cdot \mid K) := \frac{ \mathbb P(\cdot \cap K) }{ \mathbb P(K) } : \mathcal F \to [0, 1]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+P%28+%5Ccdot+%5Cmid+K%29+%3A%3D+%5Cfrac%7B+%5Cmathbb+P%28%5Ccdot+%5Ccap+K%29+%7D%7B+%5Cmathbb+P%28K%29+%7D+%3A+%5Cmathcal+F+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
 if
if  , and
, and if
if  .
.
 , which holds since
, which holds since 
 and each
and each 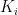 has positive probability, then
has positive probability, then
 as defined in Lemma 1 measures, roughly speaking, is the probability that the event
as defined in Lemma 1 measures, roughly speaking, is the probability that the event  occurs under the assumption that the event
occurs under the assumption that the event  , we condition on each of the varied
, we condition on each of the varied  for each
for each  automatically yields
automatically yields  ,
, .
.
 . We use this definition for the notion of independence:
. We use this definition for the notion of independence: are independent if
are independent if

 on
on  denote the event that the first coin is a Head, and
denote the event that the first coin is a Head, and  denote the event that the second coin is a Head. Then
denote the event that the second coin is a Head. Then
 ,
,  are independent,
are independent, have positive probability, then they cannot be mutually exclusive and independent at the same time,
have positive probability, then they cannot be mutually exclusive and independent at the same time, cannot be independent.
cannot be independent.
 being independent and leave the rest as exercises. Since
being independent and leave the rest as exercises. Since 
 , we have
, we have  , so that
, so that
 is nontrivial. Furthermore, the quantity seems trivial if, at least sequentially, the event
is nontrivial. Furthermore, the quantity seems trivial if, at least sequentially, the event  . Now the quantity
. Now the quantity  measures the specificity of the COVID-19 test. The quantities
measures the specificity of the COVID-19 test. The quantities  and
and  then measure the false positive rate and false negative rates respectively, and are connected to the sensitivity and specificity measures as follows:
then measure the false positive rate and false negative rates respectively, and are connected to the sensitivity and specificity measures as follows:
 of the population has been infected with COVID-19, and your COVID-19 test kit has a sensitivity of
of the population has been infected with COVID-19, and your COVID-19 test kit has a sensitivity of 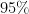 and a specificity of
and a specificity of  . Given that a patient tests positive using your test kit, what is the probability, in terms of
. Given that a patient tests positive using your test kit, what is the probability, in terms of ![\mathbb P(K \mid L) = 0.95,\quad \mathbb P(\Omega \backslash K \mid \Omega \backslash L) = 0.9,\quad \mathbb P(L) = p \in [0, 1].](https://s0.wp.com/latex.php?latex=%5Cmathbb+P%28K+%5Cmid+L%29+%3D+0.95%2C%5Cquad+%5Cmathbb+P%28%5COmega+%5Cbackslash+K+%5Cmid+%5COmega+%5Cbackslash+L%29+%3D+0.9%2C%5Cquad+%5Cmathbb+P%28L%29+%3D+p+%5Cin+%5B0%2C+1%5D.&bg=ffffff&fg=000&s=0&c=20201002)
 , so that
, so that


 ,
,  , and
, and  . This means if we know that
. This means if we know that 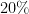 of the population has been infected with COVID-19, and assuming constant sensitivity and specificity of the COVID-19 test we tested positive for it, there is a
of the population has been infected with COVID-19, and assuming constant sensitivity and specificity of the COVID-19 test we tested positive for it, there is a  chance that we have been infected with the virus too. For better or for worse, these data points inform governments on various public health policies and measures taken to curb the virus and “
chance that we have been infected with the virus too. For better or for worse, these data points inform governments on various public health policies and measures taken to curb the virus and “
 and each
and each  has positive probability, then
has positive probability, then

 , the higher the value of
, the higher the value of ![\mathbb P := | \cdot |/|\Omega| : \mathcal P(\Omega) \to [0, 1]](https://s0.wp.com/latex.php?latex=%5Cmathbb+P+%3A%3D+%7C+%5Ccdot+%7C%2F%7C%5COmega%7C+%3A+%5Cmathcal+P%28%5COmega%29+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) . We say that we are computing the probabilities of events, since the elements of
. We say that we are computing the probabilities of events, since the elements of  satisfy several desirable properties.
satisfy several desirable properties. a
a  ,
, ,
, ,
,  .
. ,
,  is a probability measure on
is a probability measure on  .
. . Furthermore, for any
. Furthermore, for any  such that
such that  and
and  . In the latter, we say that
. In the latter, we say that 
 . For the disjoint union claim, define
. For the disjoint union claim, define  .
.
 to refer to the set
to refer to the set  if
if  ,
, , then
, then  ,
, ,
, .
.



 on both sides,
on both sides,
 and replace
and replace  and use the empty-set claim to obtain
and use the empty-set claim to obtain
 ,
, ,
, .
. , and all properties hold for Lemma 2.
, and all properties hold for Lemma 2. such that
such that 

 denotes the space for vulnerability that Person X gives to Person Y (i.e. the extent to which Person Y does not need to feel defensive when interacting with Person X).
denotes the space for vulnerability that Person X gives to Person Y (i.e. the extent to which Person Y does not need to feel defensive when interacting with Person X). denotes the space for vulnerability that Person X receives from Person Y.
denotes the space for vulnerability that Person X receives from Person Y. denotes the access that Person X gives to Person Y (i.e. the amount of personal information that Person X discloses to Person Y).
denotes the access that Person X gives to Person Y (i.e. the amount of personal information that Person X discloses to Person Y). denotes the access that Person X receives from Person Y.
denotes the access that Person X receives from Person Y. are jointly independent continuous random variables.
are jointly independent continuous random variables. that X feels he shares with Y is defined by the equation
that X feels he shares with Y is defined by the equation
![\mathbb E[C]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BC%5D&bg=ffffff&fg=000&s=0&c=20201002) is given by the quantity
is given by the quantity![\displaystyle \begin{aligned} \left(\mathbb E[Q] + \mathbb E[R] - 1 + \int_{[0, 1]} F_Q \cdot F_R\, \mathrm d\lambda \right) \cdot \left(\mathbb E[S] + \mathbb E[T] - 1 + \int_{[0, 1]} F_S \cdot F_T\, \mathrm d\lambda\right). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cleft%28%5Cmathbb+E%5BQ%5D+%2B+%5Cmathbb+E%5BR%5D+-+1+%2B+%5Cint_%7B%5B0%2C+1%5D%7D+F_Q+%5Ccdot+F_R%5C%2C+%5Cmathrm+d%5Clambda+%5Cright%29+%5Ccdot+%5Cleft%28%5Cmathbb+E%5BS%5D+%2B+%5Cmathbb+E%5BT%5D+-+1+%2B+%5Cint_%7B%5B0%2C+1%5D%7D+F_S+%5Ccdot+F_T%5C%2C+%5Cmathrm+d%5Clambda%5Cright%29.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)

![\mathbb E[V]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BV%5D&bg=ffffff&fg=000&s=0&c=20201002) . By definition,
. By definition,

![\displaystyle \mathbb E[V] = \mathbb E[Q] + \mathbb E[R] - 1 + \int_{[0, 1]} (F_Q \cdot F_R)(v)\, \mathrm dv.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5BV%5D+%3D+%5Cmathbb+E%5BQ%5D+%2B+%5Cmathbb+E%5BR%5D+-+1+%2B+%5Cint_%7B%5B0%2C+1%5D%7D+%28F_Q+%5Ccdot+F_R%29%28v%29%5C%2C+%5Cmathrm+dv.&bg=ffffff&fg=000&s=0&c=20201002)
![\displaystyle \mathbb E[A] = \mathbb E[S] + \mathbb E[T] - 1 + \int_0^1 (F_S \cdot F_T)(a)\, \mathrm da.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5BA%5D+%3D+%5Cmathbb+E%5BS%5D+%2B+%5Cmathbb+E%5BT%5D+-+1+%2B+%5Cint_0%5E1+%28F_S+%5Ccdot+F_T%29%28a%29%5C%2C+%5Cmathrm+da.&bg=ffffff&fg=000&s=0&c=20201002)
 and
and  are also independent, and
are also independent, and![\mathbb E[C] = \mathbb E[V \cdot A] = \mathbb E[V] \cdot \mathbb E[A],](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BC%5D+%3D+%5Cmathbb+E%5BV+%5Ccdot+A%5D+%3D+%5Cmathbb+E%5BV%5D+%5Ccdot+%5Cmathbb+E%5BA%5D%2C&bg=ffffff&fg=000&s=0&c=20201002)
 . After one flip, what is your score? Well, it depends. Does the coin land ‘Head’? Does it land ‘Tail’? It could go either way. How do we model this phenomenon. Well, there are
. After one flip, what is your score? Well, it depends. Does the coin land ‘Head’? Does it land ‘Tail’? It could go either way. How do we model this phenomenon. Well, there are  denote the set of possible outcomes after one flip of the coin. What are the different events that we can measure? Surely we have the non-negative probabilities
denote the set of possible outcomes after one flip of the coin. What are the different events that we can measure? Surely we have the non-negative probabilities


 . Furthermore, for any two distinct outcomes
. Furthermore, for any two distinct outcomes  , we stipulate the event that either one occurs as their sum:
, we stipulate the event that either one occurs as their sum:
 a finite measure on
a finite measure on  for distinct outcomes
for distinct outcomes 
 , we call
, we call  .
. with
with  , there exists a probability measure
, there exists a probability measure ![\mathbb P : \mathcal P(\Omega) \to [0, 1]](https://s0.wp.com/latex.php?latex=%5Cmathbb+P+%3A+%5Cmathcal+P%28%5COmega%29+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) .
. and verify Definition 1: for distinct outcomes
and verify Definition 1: for distinct outcomes  ,
,
 .
. is finite and there exists
is finite and there exists 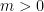 such that for any outcome
such that for any outcome  , then
, then  . We call
. We call 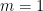 , we call
, we call  .
. ,
,
 so that we can regard
so that we can regard  as the counting measure.
as the counting measure. .
.



 . Here’s a simple question: what is the probability that we end up with a score of
. Here’s a simple question: what is the probability that we end up with a score of  defined as follows:
defined as follows:
 yield
yield  . Using inverse-image notation,
. Using inverse-image notation,
 ? Intuitively, since there are
? Intuitively, since there are  . The probability is derived from the subset
. The probability is derived from the subset  of desired outcomes:
of desired outcomes:
 a random variable on
a random variable on  is finite.
is finite. . Then the map
. Then the map  defined by
defined by  for any
for any  is a measure on
is a measure on  and call it the push-forward measure of
and call it the push-forward measure of  ,
,
