As part of the school curriculum, students are taught the binomial theorem and use solve various meaningless problems. I even asked the following question out of pure curiosity: what is the expansion of 
As a pure math student by training, I find no application of the binomial theorem at the secondary school level, except for the proof of one concept: derivatives. Let me use the examples 
Among other crucial ideas, one key component in differentiation is to evaluate the expression

If we consider 

In the differentiation process, we would set 


so that setting 

It boils down to expanding the expression 
Before we answer this question more completely, we remark that the binomial expansion does get extended to the cases when 
The content in this post will mirror the discussion in this one, which ties in the binomial expansion with counting problems in probability, but perhaps with less technical terminology.
Firstly, by observation, the highest power of 


Therefore, we will suppose that for any 


How do we expand 
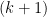


Therefore, our expansion of 


For the very special case 







as expected.
Lemma 1. For any 
Proof. We have 

so that 
Now working on the case

Hence,

as expected.
Remark 1. Since the numbers 


Theorem 1 (Binomial Theorem). For real numbers 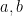

Furthermore, using ideas in counting problems (i.e. Theorem 4 of this post), for any 

where 
Proof. The result is trivial if 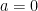
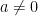


For the general case, we first factorise to reduce to the special case:

We then use the special case to obtain

as required.
Theorem 2. Given 

yields
Proof. Using the binomial theorem,

Setting

A slightly more interesting example arises in the expansion of 

Coupling this calculation with several other high-level convergence ideas, we can derive the definition of 
We touch base with the idea of exponential functions next time. For a fully rigorous construction of these objects, see this post involving real analysis.
—Joel Kindiak, 27 Oct 25, 1827H
