Let 




In this post, we explore the idea of invertible transformations and how we can use these ideas to help us solve simultaneous linear equations. It turns out that solving this problem is key to helping us understand dimensions in vector spaces.
Let 


Lemma 1. For any nonempty set 

- For any
,
.
- For any
,
.
- The identity map
and for any
,
.
- For any
and
.
Together, we call 

and is the group of vector space isomorphisms (under function composition) from 

It turns out that if there exists an isomorphism 
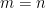
What are the solutions (in
?
Intuitively, we would think that 





Now we could represent this information in terms of vectors. Denote the vector

The equation tells us that we need to combine the recipe 


Indeed, any 


Therefore, 

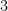

What are the solutions (in

Denoting 


Unfortunately, evaluating the right-hand side will inevitably lead us back to where we started. We need some clever tricks. Well, recalling the method of elimination, if we subtracted the first equation from the second, we get

Multiplying by 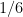

Finally, adding 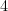

Denoting 

The key idea is that in each step, we could “undo” the process (e.g. multiplying by 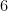


- The columns
are arranged right-ward. These are called pivot columns. Columns that are not pivot columns are non-pivot columns.
- Before a column that is
, all columns are
.
- Any column between
and
belongs to
. Here, we use round brackets to emphasise the order of the basis.
Using induction, we can prove that every matrix
Therefore, given 



If we can prove that our suggested moves do indeed correspond with bijective linear transformations, we can prove the result. We will use 
Lemma 2. Suppose 


Furthermore, 
Proof. By invertibility,

By the definition of 

We can check that the map

with identity 


yielding
Henceforth, we will make no distinction between 


Corollary 1. A matrix 

Let 
Lemma 3. Multiplying row 

Proof. To show that we multiply the row, we carry out the matrix multiplication:

We can similarly verify that the inverse of 

Lemma 4. Adding

Swapping row

Proof. Exercise. Check that

The matrices of the forms in Lemmas 3 and 4 are called elementary matrices, which can be defined similarly for 
Lemma 5. For any 





This procedure of converting a matrix into its reduced row-echelon form is called Gaussian elimination (or more precisely, Gauss-Jordan elimination).
Proof. Thanks to the matrices in Lemmas 3 and 4, there exist a sequence of elementary matrices 

Denoting 
We have come to the fundamental theorem of invertible matrices.
Theorem 1. Let
- The solution to
is
.
- The reduced row-echelon form of
.
Proof. If
Suppose the solution to
If 

Suppose 

If instead 


This implies that 


In particular, choosing 



Since

Suppose 
Since inverses of elementary matrices are themselves elementary matrices,

is a product of elementary matrices. Since each elementary matrix is invertible, so is
Analysing pivot columns is itself interesting, since we can generalise the arguments above to deduce the necessary sizes of the matrices.
Corollary 2. Let
- If
.
- If
.
Proof. Let

If
Suppose 




Now that we have established the relative sizes of matrices given its injectivity or surjectivity status, we are finally ready to discussion dimensions. Roughly speaking, a linearly independent set corresponds to an injective matrix, while a spanning set corresponds to a surjective matrix. The numbers of the dimensions will then follow accordingly. But this post is getting as lengthy as it needs to be, and so we delay this discussion to next time.
—Joel Kindiak, 1 Mar 25, 1431H

Leave a reply to What is a Determinant? – KindiakMath Cancel reply