A random variable is neither random nor a variable. Let me explain.
Flip a fair coin twice. Let  denote the number of Heads that you obtain. What is the value of ? Well, it depends on each outcome in the sample space
denote the number of Heads that you obtain. What is the value of ? Well, it depends on each outcome in the sample space 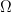 :
:

Denote  and the uniform probability measure on
and the uniform probability measure on  by
by  . Since denotes the number of Heads, we have
. Since denotes the number of Heads, we have

Notice then the randomness arises in selecting the outcome  , not in the measurement
, not in the measurement  (though the former inevitably influences the latter). The quantity just records the number of Heads in the outcome
(though the former inevitably influences the latter). The quantity just records the number of Heads in the outcome 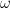 , and each occurs with some probability (which we will explore later on).
, and each occurs with some probability (which we will explore later on).
Thus, while we call a random variable, it is neither random (though that is captured by the randomness of ), nor a variable (though that is captured by  ).
).
Let  and
and  be measurable spaces.
be measurable spaces.
Definition 1. A map  is
is  –measurable if for any
–measurable if for any  ,
,  . We omit the prefix when the context is clear.
. We omit the prefix when the context is clear.
Lemma 1. Suppose . Any map is measurable, where 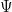 is equipped with the
is equipped with the  -algebra
-algebra  .
.
Proof. For any  ,
,

Lemma 2. Suppose furthermore there exists a probability measure  on . Then the map
on . Then the map ![\mathbb P_X := \mathbb P \circ X^{-1} : \mathcal G \to [0, 1]](https://s0.wp.com/latex.php?latex=%5Cmathbb+P_X+%3A%3D+%5Cmathbb+P+%5Ccirc+X%5E%7B-1%7D+%3A+%5Cmathcal+G+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) is a probability measure on the measurable space
is a probability measure on the measurable space  , called the push-forward measure of .
, called the push-forward measure of .
Lemmas 1 and 2 are crucial for this purpose: they illustrate that, all things considered, the underlying sample space  is not as nearly as relevant as the measures induced on
is not as nearly as relevant as the measures induced on  . Eventually, we will want to develop measures on
. Eventually, we will want to develop measures on  too, though that will take substantially more effort.
too, though that will take substantially more effort.
Equip with the -algebra 
Definition 2. Let be any probability space. A discrete random variable is a map  . Since we equipped with the -algebra , is automatically measurable. We call its pushforward measure
. Since we equipped with the -algebra , is automatically measurable. We call its pushforward measure  the distribution of , and for convenience denote, for
the distribution of , and for convenience denote, for  ,
,

Without loss of generality, given that a discrete random variable has distribution , we assume that  and that with respect to this choice,
and that with respect to this choice,  .
.
Lemma 3. For any discrete random variable ,  .
.
The support of a discrete random variable is ![\mathbb P_X^{-1}((0, 1])](https://s0.wp.com/latex.php?latex=%5Cmathbb+P_X%5E%7B-1%7D%28%280%2C+1%5D%29&bg=ffffff&fg=000&s=0&c=20201002) . The probability mass function or p.m.f. of is defined by
. The probability mass function or p.m.f. of is defined by  . The cumulative distribution function or c.d.f. of is defined by
. The cumulative distribution function or c.d.f. of is defined by
![\displaystyle F_X : \mathbb R \to [0, 1],\quad F_X(x) := \mathbb P(X \leq x) \equiv \sum_{t = 0}^{\lfloor x \rfloor} f_X(t).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F_X+%3A+%5Cmathbb+R+%5Cto+%5B0%2C+1%5D%2C%5Cquad+F_X%28x%29+%3A%3D+%5Cmathbb+P%28X+%5Cleq+x%29+%5Cequiv+%5Csum_%7Bt+%3D+0%7D%5E%7B%5Clfloor+x+%5Crfloor%7D+f_X%28t%29.&bg=ffffff&fg=000&s=0&c=20201002)
To illustrate meaningful examples, let’s consider the flipping of a biased coin with parameter ![p \in [0, 1]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) . This means the probability of getting ‘Head’ is some fixed value
. This means the probability of getting ‘Head’ is some fixed value  , which may or may not be
, which may or may not be 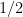 .
.
Example 1. Consider the usual sample space  equipped with the -algebra
equipped with the -algebra  . Define the probability measure
. Define the probability measure ![\mathbb P : \mathcal F \to [0, 1]](https://s0.wp.com/latex.php?latex=%5Cmathbb+P+%3A+%5Cmathcal+F+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) by
by  , which implies that
, which implies that

Define the random variable defined by  and
and  . Then
. Then

so that  for
for  .
.
Definition 3. Let be any probability space and be a discrete random variable. We say that follows a Bernoulli distribution with parameter , denoted  , if
, if

Example 2. The random variable defined in Example 1 has the distribution  . The random variable
. The random variable  has the distribution
has the distribution  since
since

Example 3. The discrete random variable 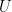 is uniform on
is uniform on ![(a, b]](https://s0.wp.com/latex.php?latex=%28a%2C+b%5D&bg=ffffff&fg=000&s=0&c=20201002) given integers
given integers  if
if
![\displaystyle \mathbb P(U = u) = \frac{1}{b-a},\quad u \in (a, b] \cap \mathbb N.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+P%28U+%3D+u%29+%3D+%5Cfrac%7B1%7D%7Bb-a%7D%2C%5Cquad+u+%5Cin+%28a%2C+b%5D+%5Ccap+%5Cmathbb+N.&bg=ffffff&fg=000&s=0&c=20201002)
Having properly defined a discrete random variable, a natural question arises: are there approaches to create new random variables from old ones? For instance, given two random variables and  , what is the distribution of their sum
, what is the distribution of their sum  ? In the special case of Example 2, it is obvious that by construction,
? In the special case of Example 2, it is obvious that by construction,  . But what if
. But what if  don’t have any obvious connection?
don’t have any obvious connection?
Next time, we explore the idea of independence of random variables and think about ways to combine them.
—Joel Kindiak, 27 Jun 25, 1300H

Leave a comment