In high school, the standard deviation 


Today, we will approach the standard deviation from far more intuitive perspective, and recover the above formula as a special case. Its cousin 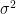
We first define the covariance between two random variables 

![\mathbb E[X]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D&bg=ffffff&fg=000&s=0&c=20201002)
Definition 1. The covariance of 
![\mathrm{Cov}(X, Y) = \mathbb E[(X - \mathbb E[X]) \cdot (Y - \mathbb E[Y])].](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BCov%7D%28X%2C+Y%29+%3D+%5Cmathbb+E%5B%28X+-+%5Cmathbb+E%5BX%5D%29+%5Ccdot+%28Y+-+%5Cmathbb+E%5BY%5D%29%5D.&bg=ffffff&fg=000&s=0&c=20201002)
Lemma 1. By expectation properties, we obtain
![\mathrm{Cov}(X, Y) = \mathbb E[XY] - \mathbb E[X]\cdot \mathbb E[Y].](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BCov%7D%28X%2C+Y%29+%3D+%5Cmathbb+E%5BXY%5D+-+%5Cmathbb+E%5BX%5D%5Ccdot+%5Cmathbb+E%5BY%5D.&bg=ffffff&fg=000&s=0&c=20201002)
Proof. Expanding within the expectation,
![\begin{aligned}(X - \mathbb E[X]) \cdot (Y - \mathbb E[Y]) &= XY - \mathbb E[X] \cdot Y - \mathbb E[Y] \cdot X + \mathbb E[X] \cdot \mathbb E[Y].\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%28X+-+%5Cmathbb+E%5BX%5D%29+%5Ccdot+%28Y+-+%5Cmathbb+E%5BY%5D%29+%26%3D+XY+-+%5Cmathbb+E%5BX%5D+%5Ccdot+Y+-+%5Cmathbb+E%5BY%5D+%5Ccdot+X+%2B+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D.%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Applying the linearity of ![\mathbb E[\cdot]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%5Ccdot%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\begin{aligned} \mathrm{Cov}(X, Y) &= \mathbb E[(X - \mathbb E[X]) \cdot (Y - \mathbb E[Y])] \\ &=\mathbb E[XY - \mathbb E[X] \cdot Y - \mathbb E[Y] \cdot X + \mathbb E[X] \cdot \mathbb E[Y]] \\ &= \mathbb E[XY] - \mathbb E[\mathbb E[X] \cdot Y] - \mathbb E[\mathbb E[Y] \cdot X] + \mathbb E[\mathbb E[X] \cdot \mathbb E[Y]] \\ &= \mathbb E[XY] - \mathbb E[X] \cdot \mathbb E[Y] - \mathbb E[Y] \cdot \mathbb E[X] + \mathbb E[X] \cdot \mathbb E[Y] \cdot \mathbb E[1] \\ &= \mathbb E[XY] - \mathbb E[X] \cdot \mathbb E[Y]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathrm%7BCov%7D%28X%2C+Y%29+%26%3D+%5Cmathbb+E%5B%28X+-+%5Cmathbb+E%5BX%5D%29+%5Ccdot+%28Y+-+%5Cmathbb+E%5BY%5D%29%5D+%5C%5C+%26%3D%5Cmathbb+E%5BXY+-+%5Cmathbb+E%5BX%5D+%5Ccdot+Y+-+%5Cmathbb+E%5BY%5D+%5Ccdot+X+%2B+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D%5D+%5C%5C+%26%3D+%5Cmathbb+E%5BXY%5D+-+%5Cmathbb+E%5B%5Cmathbb+E%5BX%5D+%5Ccdot+Y%5D+-+%5Cmathbb+E%5B%5Cmathbb+E%5BY%5D+%5Ccdot+X%5D+%2B+%5Cmathbb+E%5B%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D%5D+%5C%5C+%26%3D+%5Cmathbb+E%5BXY%5D+-+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D+-+%5Cmathbb+E%5BY%5D+%5Ccdot+%5Cmathbb+E%5BX%5D+%2B+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D+%5Ccdot+%5Cmathbb+E%5B1%5D+%5C%5C+%26%3D+%5Cmathbb+E%5BXY%5D+-+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Lemma 2. The covariance satisfies the following properties:
,
if and only if
,
,
for
,
.
Proof. We prove the fourth property to illustrate:
![\begin{aligned}\mathrm{Cov}(W+X, Y) &= \mathbb E[(W+X)Y] - \mathbb E[W+X] \cdot \mathbb E[Y] \\ &= \mathbb E[WY+XY] - (\mathbb E[W]+\mathbb E[X]) \cdot \mathbb E[Y] \\ &= \mathbb E[WY]+\mathbb E[XY] - (\mathbb E[W] \cdot \mathbb E[Y]+\mathbb E[X] \cdot \mathbb E[Y]) \\ &= \mathbb E[WY] - \mathbb E[W] \cdot \mathbb E[Y] +\mathbb E[XY] - \mathbb E[X] \cdot \mathbb E[Y] \\ &= \mathrm{Cov}(W,Y) + \mathrm{Cov}(X,Y). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cmathrm%7BCov%7D%28W%2BX%2C+Y%29+%26%3D+%5Cmathbb+E%5B%28W%2BX%29Y%5D+-+%5Cmathbb+E%5BW%2BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D+%5C%5C+%26%3D+%5Cmathbb+E%5BWY%2BXY%5D+-+%28%5Cmathbb+E%5BW%5D%2B%5Cmathbb+E%5BX%5D%29+%5Ccdot+%5Cmathbb+E%5BY%5D+%5C%5C+%26%3D+%5Cmathbb+E%5BWY%5D%2B%5Cmathbb+E%5BXY%5D+-+%28%5Cmathbb+E%5BW%5D+%5Ccdot+%5Cmathbb+E%5BY%5D%2B%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D%29+%5C%5C+%26%3D+%5Cmathbb+E%5BWY%5D+-+%5Cmathbb+E%5BW%5D+%5Ccdot+%5Cmathbb+E%5BY%5D+%2B%5Cmathbb+E%5BXY%5D+-+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D+%5C%5C+%26%3D+%5Cmathrm%7BCov%7D%28W%2CY%29+%2B+%5Cmathrm%7BCov%7D%28X%2CY%29.++%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
It is similar to the properties of an inner product, but not exactly, since the second property should require 
Lemma 3. Given any constant 

Proof. By Lemma 2, it suffices to prove that 
![\mathrm{Cov}(k, Y) = \mathbb E[k Y] - \mathbb E[k] \cdot \mathbb E[Y] = k \cdot \mathbb E[Y] - k \cdot \mathbb E[Y] = 0.](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BCov%7D%28k%2C+Y%29+%3D+%5Cmathbb+E%5Bk+Y%5D+-+%5Cmathbb+E%5Bk%5D+%5Ccdot+%5Cmathbb+E%5BY%5D+%3D+k+%5Ccdot+%5Cmathbb+E%5BY%5D+-+k+%5Ccdot+%5Cmathbb+E%5BY%5D+%3D+0.&bg=ffffff&fg=000&s=0&c=20201002)
Lemma 4. For any random variable
![\mathrm{Var}(X) := \mathrm{Cov}(X,X) = \mathbb E[X^2] - \mathbb E[X]^2](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BVar%7D%28X%29+%3A%3D+%5Cmathrm%7BCov%7D%28X%2CX%29+%3D+%5Cmathbb+E%5BX%5E2%5D+-+%5Cmathbb+E%5BX%5D%5E2&bg=ffffff&fg=000&s=0&c=20201002)
whenever the right-hand side exists. Then 
Proof. We have

Lemma 5. Denote ![\mu_X := \mathbb E[X]](https://s0.wp.com/latex.php?latex=%5Cmu_X+%3A%3D+%5Cmathbb+E%5BX%5D&bg=ffffff&fg=000&s=0&c=20201002)




Proof. By Lemma 2,

The covariance helps us measure the correlation between the random variables, which we formally define below.
Definition 2. The correlation between

Corollary 1. Given the dataset 







where 

for brevity.
Proof. By an equivalent definition for expectation,
![\begin{aligned} \mathbb E[XY] &= \sum_{\omega \in \Omega} X(\omega) \cdot Y(\omega) \cdot \mathbb P(\{\omega\}) \\ &= \sum_{i=1}^n x_i \cdot y_i \cdot \frac 1n = \frac{ 1 }{n} \sum_{i=1}^n x_i y_i. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BXY%5D+%26%3D+%5Csum_%7B%5Comega+%5Cin+%5COmega%7D+X%28%5Comega%29+%5Ccdot+Y%28%5Comega%29+%5Ccdot+%5Cmathbb+P%28%5C%7B%5Comega%5C%7D%29+%5C%5C+%26%3D+%5Csum_%7Bi%3D1%7D%5En+x_i+%5Ccdot+y_i+%5Ccdot+%5Cfrac+1n+%3D+%5Cfrac%7B+1+%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5En+x_i+y_i.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
The other quantities can be computed in a similar manner.
Corollary 2. Setting 

Furthermore, combining Definition 2 and Corollaries 1 and 2, the product moment correlation coefficient 

Finally,

Given two random variables ![\mathbb E[X+Y] = \mathbb E[X] + \mathbb E[Y]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%2BY%5D+%3D+%5Cmathbb+E%5BX%5D+%2B+%5Cmathbb+E%5BY%5D&bg=ffffff&fg=000&s=0&c=20201002)


So it’s not as simple as 

![\mathbb E[XY] = \mathbb E[X] \cdot \mathbb E[Y].](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BXY%5D+%3D+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D.&bg=ffffff&fg=000&s=0&c=20201002)
Lemma 6. If

Proof. By definition, since
![\begin{aligned} \mathbb E[XY] &= \sum_{x \in \mathbb Z} \sum_{y \in \mathbb Z} xy \cdot \mathbb P_{X,Y}(x,y) \\ &= \sum_{x \in \mathbb Z} \sum_{y \in \mathbb Z} x \cdot y \cdot \mathbb P_X(x) \cdot \mathbb P_Y(y) \\ &= \sum_{x \in \mathbb Z} x \cdot \mathbb P_X(x) \cdot \sum_{y \in \mathbb Z} y \cdot \mathbb P_Y(y) = \mathbb E[X] \cdot \mathbb E[Y]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BXY%5D+%26%3D+%5Csum_%7Bx+%5Cin+%5Cmathbb+Z%7D+%5Csum_%7By+%5Cin+%5Cmathbb+Z%7D+xy+%5Ccdot+%5Cmathbb+P_%7BX%2CY%7D%28x%2Cy%29+%5C%5C+%26%3D+%5Csum_%7Bx+%5Cin+%5Cmathbb+Z%7D+%5Csum_%7By+%5Cin+%5Cmathbb+Z%7D+x+%5Ccdot+y+%5Ccdot+%5Cmathbb+P_X%28x%29+%5Ccdot+%5Cmathbb+P_Y%28y%29+%5C%5C+%26%3D+%5Csum_%7Bx+%5Cin+%5Cmathbb+Z%7D+x+%5Ccdot+%5Cmathbb+P_X%28x%29+%5Ccdot+%5Csum_%7By+%5Cin+%5Cmathbb+Z%7D+y+%5Ccdot+%5Cmathbb+P_Y%28y%29+%3D+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Cmathbb+E%5BY%5D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Therefore, we recover the core variance properties of interest.
Theorem 1. If

Proof. For the minus case,

Example 1. For any 



Proof. We observe that 
![\mathrm{Var}( \xi) = \mathbb E[ \xi^2] - \mathbb E[ \xi]^2 = p - p^2 = p(1-p).](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BVar%7D%28+%5Cxi%29+%3D+%5Cmathbb+E%5B+%5Cxi%5E2%5D+-+%5Cmathbb+E%5B+%5Cxi%5D%5E2+%3D+p+-+p%5E2+%3D+p%281-p%29.&bg=ffffff&fg=000&s=0&c=20201002)
Writing 


Example 2. Let 


Then ![\mathbb E[\bar X_n] = \mu](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%5Cbar+X_n%5D+%3D+%5Cmu&bg=ffffff&fg=000&s=0&c=20201002)

Thus, at least intuitively, we should get 
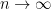

Lemma 7. For any 
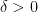
![\displaystyle \mathbb P(Y \geq \delta) \leq \frac{ \mathbb E[Y] }{ \delta }.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+P%28Y+%5Cgeq+%5Cdelta%29+%5Cleq+%5Cfrac%7B+%5Cmathbb+E%5BY%5D+%7D%7B+%5Cdelta+%7D.&bg=ffffff&fg=000&s=0&c=20201002)
This result is known as Markov’s inequality.
Proof. For any
![\begin{aligned} \mathbb E[Y] &= \sum_{y \in \mathbb Z} y \cdot \mathbb P_Y(y) \\ &= \sum_{y < \delta} y \cdot \mathbb P_Y(y) + \sum_{y \geq \delta} y \cdot \mathbb P_Y(y) \\ &\geq \sum_{y < \delta} 0 \cdot \mathbb P_Y(y) + \sum_{y \geq \delta} \delta \cdot \mathbb P_Y(y) \\ &= \delta \cdot \sum_{y \geq \delta} \mathbb P_Y(y) = \delta \cdot \mathbb P(Y \geq \delta). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BY%5D+%26%3D+%5Csum_%7By+%5Cin+%5Cmathbb+Z%7D+y+%5Ccdot+%5Cmathbb+P_Y%28y%29+%5C%5C+%26%3D+%5Csum_%7By+%3C+%5Cdelta%7D+y+%5Ccdot+%5Cmathbb+P_Y%28y%29+%2B+%5Csum_%7By+%5Cgeq+%5Cdelta%7D+y+%5Ccdot+%5Cmathbb+P_Y%28y%29+%5C%5C+%26%5Cgeq+%5Csum_%7By+%3C+%5Cdelta%7D+0+%5Ccdot+%5Cmathbb+P_Y%28y%29+%2B+%5Csum_%7By+%5Cgeq+%5Cdelta%7D+%5Cdelta+%5Ccdot+%5Cmathbb+P_Y%28y%29+%5C%5C+%26%3D+%5Cdelta+%5Ccdot+%5Csum_%7By+%5Cgeq+%5Cdelta%7D+%5Cmathbb+P_Y%28y%29+%3D+%5Cdelta+%5Ccdot+%5Cmathbb+P%28Y+%5Cgeq+%5Cdelta%29.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Hence, ![\mathbb P(Y \geq \delta) \leq \mathbb E[Y]/\delta](https://s0.wp.com/latex.php?latex=%5Cmathbb+P%28Y+%5Cgeq+%5Cdelta%29+%5Cleq+%5Cmathbb+E%5BY%5D%2F%5Cdelta&bg=ffffff&fg=000&s=0&c=20201002)
Lemma 8. For any random variable

This result is known as Chebychev’s inequality.
Proof. Setting 
![\mathbb E[Y] = \mathrm{Var}(X) = \sigma^2](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BY%5D+%3D+%5Cmathrm%7BVar%7D%28X%29+%3D+%5Csigma%5E2&bg=ffffff&fg=000&s=0&c=20201002)
![\begin{aligned}\mathbb P(|X - \mu| \geq \delta) &= \mathbb P(|X - \mu|^2 \geq \delta^2) = \mathbb P(Y \geq \delta^2) \leq \frac{\mathbb E[Y]}{\delta^2} = \frac{\sigma^2}{\delta^2}.\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cmathbb+P%28%7CX+-+%5Cmu%7C+%5Cgeq+%5Cdelta%29+%26%3D+%5Cmathbb+P%28%7CX+-+%5Cmu%7C%5E2+%5Cgeq+%5Cdelta%5E2%29+%3D+%5Cmathbb+P%28Y+%5Cgeq+%5Cdelta%5E2%29+%5Cleq+%5Cfrac%7B%5Cmathbb+E%5BY%5D%7D%7B%5Cdelta%5E2%7D+%3D+%5Cfrac%7B%5Csigma%5E2%7D%7B%5Cdelta%5E2%7D.%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Theorem 2. Fix 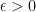



Hence, with more technical caveats, we can conclude that

This result is known as the weak law of large numbers.
Proof. Applying Chebychev’s inequality.,

This writeup brings us to the limit, pun not intended, of our intuitive ideas of probability. Up till now, we assumed that 

—Joel Kindiak, 3 Jul 25, 0019H

Leave a comment