Let  be i.i.d. random variables that denote the scores on a recent exam, with mean
be i.i.d. random variables that denote the scores on a recent exam, with mean  and standard deviation
and standard deviation  . Suppose students used to score
. Suppose students used to score  marks on an end-year exam. This time, however, students seem rather dejected after leaving the exam hall, lamenting that the exam was a lot more challenging than before.
marks on an end-year exam. This time, however, students seem rather dejected after leaving the exam hall, lamenting that the exam was a lot more challenging than before.
We can use hypothesis testing to determine with some reasonably small error  whether or not their claim holds weight; that is, whether the exam was harder, and thus, the population mean score has decreased. The default case
whether or not their claim holds weight; that is, whether the exam was harder, and thus, the population mean score has decreased. The default case  is called the null hypothesis, denoted
is called the null hypothesis, denoted  , and the proposed change
, and the proposed change  is called the alternative hypothesis, denoted
is called the alternative hypothesis, denoted  . Usually, we abbreviate as follows
. Usually, we abbreviate as follows

How do we go about testing this hypothesis? We will presume the innocence of the defendant until we have sufficient evidence to convict it guilty, concluding . Under , which states that , we have  approximately by the central limit theorem.
approximately by the central limit theorem.
We then go and sample  students, obtaining the sample points
students, obtaining the sample points  , and we can compute
, and we can compute

since  is an unbiased estimator for . But how do we estimate
is an unbiased estimator for . But how do we estimate 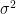 ? We use the unbiased estimator
? We use the unbiased estimator  , where
, where

If each 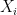 are normally distributed, so is
are normally distributed, so is  . What would be the distribution of
. What would be the distribution of  ?
?
Theorem 1. For  , if
, if  are i.i.d., then there exist i.i.d.
are i.i.d., then there exist i.i.d.  such that
such that

Proof. See Exercise 6 on multivariate normal distributions.
The right-hand side is often abbreviated as the chi-squared distribution with 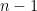 degrees of freedom. We slowly formalise it as follows.
degrees of freedom. We slowly formalise it as follows.
Lemma 1. Suppose  , where
, where  . Then the p.d.f. of
. Then the p.d.f. of  is given by
is given by

where  denotes the gamma function. Recall that
denotes the gamma function. Recall that  .
.
Proof. We first remark that  . Therefore, we restrict our attention to
. Therefore, we restrict our attention to  . Then
. Then

Differentiating and applying the p.d.f. of a standard normal distribution,

Lemma 2. For any  ,
,

Proof. Assuming all integrals are finite, we first prove that

where  denotes the Lebesgue measure on
denotes the Lebesgue measure on  . Including the dummy variables for readability, Fubini’s theorem and the change-of-variables
. Including the dummy variables for readability, Fubini’s theorem and the change-of-variables  reduces the left-hand side reduces to
reduces the left-hand side reduces to

Now define  , so that applying this result to the definition of the gamma function defined by
, so that applying this result to the definition of the gamma function defined by

yields

Evaluating the convolution, and using the change of variables  ,
,

Integrating on both sides, and applying Fubini’s theorem,

and the result follow by algebruh.
Definition 1. The random variable  is said to follow a chi-squared distribution with
is said to follow a chi-squared distribution with  degrees of freedom, denoted
degrees of freedom, denoted  , if its density function is given by
, if its density function is given by

Lemma 3. For any  , if
, if  and
and  are independent, then
are independent, then  .
.
Proof. Denoting  ,
,  , taking convolutions and applying Lemma 2,
, taking convolutions and applying Lemma 2,

Lemma 4. Fix . Then  if and only if there exist i.i.d.
if and only if there exist i.i.d.  such that
such that  .
.
Proof. The direction  is the content of Lemma 3, and the direction
is the content of Lemma 3, and the direction  follows an argument by induction applied to Lemma 3 again.
follows an argument by induction applied to Lemma 3 again.
Example 1. As defined in Theorem 1,  .
.
Let  be i.i.d. with mean and known variance , The central limit theorem (which we aim to eventually prove) tells us that regardless of the underlying distribution of ,
be i.i.d. with mean and known variance , The central limit theorem (which we aim to eventually prove) tells us that regardless of the underlying distribution of ,

Equivalently, we have that

Of course, if the terms are normally distributed, then this statement holds exactly.
If is unknown, however, then such a conclusion isn’t very useful, since our estimate  can only be expressed in terms of . However, the quantity is an unbiased estimate of . Furthermore, if the terms are normally distributed, then Example 1 characterises the distribution of via
can only be expressed in terms of . However, the quantity is an unbiased estimate of . Furthermore, if the terms are normally distributed, then Example 1 characterises the distribution of via

What would be the distribution of the modified random variable  defined below?
defined below?

By algebraic manipulation,

Definition 2. A random variable  is said to follow a Student’s
is said to follow a Student’s  -distribution with
-distribution with  degrees of freedom, denoted
degrees of freedom, denoted  , if there exist independent and such that
, if there exist independent and such that

In particular,  . As such, we recover the classic -test for statistical hypothesis testing by modelling the data, assuming the underlying data follows a normal distribution.
. As such, we recover the classic -test for statistical hypothesis testing by modelling the data, assuming the underlying data follows a normal distribution.
To use the -distribution well, we would need its p.d.f., so that we can use numerical integration techniques to estimate various crucial probabilities that we can tabulate nicely in a table.
Theorem 2. If , then has a p.d.f.  given by
given by

Proof. By definition, find i.i.d. and such that  . Denote
. Denote  . By Fubini’s theorem,
. By Fubini’s theorem,

Differentiating under the integral sign,

We leave it as an exercise to verify that

where  , so that by the substitution
, so that by the substitution  ,
,

Recall our original question: we wanted to analyse if students’ scores have decreased, by testing the hypothesis against given by

Assuming our students’ scores follow a normal distribution (which happens frequently enough to be an acceptable assumption), we can obtain a random sample and compute the -statistic  given by the expressions
given by the expressions

By collecting data to evaluate  and
and  , we obtain a -value of
, we obtain a -value of

The instance  inches towards our suspicions of marks having decreased being correct. Since , we can compute the
inches towards our suspicions of marks having decreased being correct. Since , we can compute the  -value
-value  .
.
If instead we don’t know that student’s scores follow a normal distribution but we do know what the standard deviation of their scores is, then the central limit theorem tells us the standardized random variable of is approximately normally distributed (that is, it converges in distribution to the standard normal distribution), so that we can regard

In this case, our -value is computed using the  -value:
-value:

How do we reject ? Notice that in the -value and -value calculations, we assume holds, that is, , and substituted accordingly. The larger that  or
or 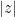 is away from
is away from  , the greater the normalised change, and so the smaller the value of .
, the greater the normalised change, and so the smaller the value of .
How small is sufficiently small for us to reject ? No one knows. If you require  , then there is no way that we can reject . Otherwise, if you require
, then there is no way that we can reject . Otherwise, if you require  for some predetermined of your choice, commonly
for some predetermined of your choice, commonly 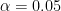 (or in physicists’ case,
(or in physicists’ case,  , known as the 5-sigma-rule), there is a chance of rejecting . We call
, known as the 5-sigma-rule), there is a chance of rejecting . We call  the level of significance, and reject if and only if .
the level of significance, and reject if and only if .
This form of statistical hypothesis testing is commonly used in sciences—physical and social—by interpreting collected data and the statistics it suggests about the underlying distribution. Yet, our conclusions may be wrong.
- If we rejected when we shouldn’t have, we call it a type-I error.
- If we did not reject when we should have, we call it the type-II error.
We note that refers to our maximum chosen probability of unintentionally committing a type-I error.
Finally, hypothesis tests pertaining an existing population mean commonly take on three flavours:
- Left-tailed:
 vs.
vs.  ,
,
- Right-tailed: vs.
 ,
,
- Two-tailed: vs.
 .
.
Now we return to our original quest: proving the central limit theorem. We will need to revisit distribution functions and characteristic functions for a not-too-challenging proof of the central limit theorem, at least for the undergraduate context.
—Joel Kindiak, 26 Jul 25, 2103H

Leave a comment