We are now justified in adding random variables. For instance, if  , what is the distribution of
, what is the distribution of  ? Unfortunately, in the most extreme cases, this answer is trivial.
? Unfortunately, in the most extreme cases, this answer is trivial.
Lemma 1. Let  and
and  . Then
. Then  and
and  .
.
Proof. We observe that for any  , since
, since  , by a change of variables,
, by a change of variables,

Therefore, for any ,

Therefore,  so that .
so that .
Here, it is clear that  is entirely dependent—
is entirely dependent—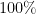 correlated even—to the random variable
correlated even—to the random variable  . We got a rather useless answer to our question in this case. If instead we swung to the other extreme, namely
. We got a rather useless answer to our question in this case. If instead we swung to the other extreme, namely  being independent, we don’t have a general formula for any
being independent, we don’t have a general formula for any  . Nevertheless, the independent case proves to be far more useful in reality—for instance, the exam scores of two students are effectively independent barring (sufficiently drastic) externalities.
. Nevertheless, the independent case proves to be far more useful in reality—for instance, the exam scores of two students are effectively independent barring (sufficiently drastic) externalities.
Therefore, let’s discuss what it means for two random variables  to be independent. We have previously seen that two events
to be independent. We have previously seen that two events  are called independent if
are called independent if  .
.
Lemma 2. The set  forms a
forms a  -algebra, called the -algebra generated by .
-algebra, called the -algebra generated by .
Given two -algebras  , also known as sub--algebras of
, also known as sub--algebras of  , we say that
, we say that  are independent if for any
are independent if for any  ,
,  are independent.
are independent.
Definition 1. Two random variables are said to be independent if  are independent.
are independent.
Suppose  and
and  , where
, where  denotes either the counting measure
denotes either the counting measure  or the Lebesgue measure
or the Lebesgue measure  . Let
. Let  be the product of two copies of . Suppose
be the product of two copies of . Suppose  .
.
Theorem 1. are independent and if and only if

where the integrand in the right-hand side is interpreted to mean

Proof. Consider the cumulative distribution functions
![F_X(x) := \mathbb P(X \in (-\infty, x]) \equiv \mathbb P(X \leq x),\quad F_Y(y) := \mathbb P( Y \leq y).](https://s0.wp.com/latex.php?latex=F_X%28x%29+%3A%3D+%5Cmathbb+P%28X+%5Cin+%28-%5Cinfty%2C+x%5D%29+%5Cequiv+%5Cmathbb+P%28X+%5Cleq+x%29%2C%5Cquad+F_Y%28y%29+%3A%3D+%5Cmathbb+P%28+Y+%5Cleq+y%29.&bg=ffffff&fg=000&s=0&c=20201002)
By the Radon-Nikodým theorem,
![\displaystyle F_X(x) = \int_{(-\infty, x]} f_X\, \mathrm d\mu,\quad F_Y(y) = \int_{(-\infty, y]} f_Y\, \mathrm d\mu.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F_X%28x%29+%3D+%5Cint_%7B%28-%5Cinfty%2C+x%5D%7D+f_X%5C%2C+%5Cmathrm+d%5Cmu%2C%5Cquad+F_Y%28y%29+%3D+%5Cint_%7B%28-%5Cinfty%2C+y%5D%7D+f_Y%5C%2C+%5Cmathrm+d%5Cmu.&bg=ffffff&fg=000&s=0&c=20201002)
In the direction  , by the Fubini-Tonelli theorem,
, by the Fubini-Tonelli theorem,
![\begin{aligned} \mathbb P(X^{-1}((-\infty, x]) \cap Y^{-1}((-\infty, y])) &= \mathbb P((X,Y) \in (-\infty, x] \times (-\infty, y]) \\ &= \int_{(-\infty, x] \times (-\infty, y]} f_{X,Y}\, \mathrm d\mu^2 \\ &= \int_{(-\infty, x]} \int_{(-\infty, y]} f_{X,Y}\, \mathrm d \mu\, \mathrm d \mu \\ &= \int_{(-\infty, x]} \int_{(-\infty, y]} f_X \cdot f_Y\, \mathrm d \mu\, \mathrm d \mu \\ &= \int_{(-\infty, x]} f_X \, \mathrm d \mu \cdot \int_{(-\infty, y]} f_Y\, \mathrm d \mu \\ &= \mathbb P(X^{-1}(-\infty, x]) \cdot \mathbb P(Y^{-1}(-\infty, y]), \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+P%28X%5E%7B-1%7D%28%28-%5Cinfty%2C+x%5D%29+%5Ccap+Y%5E%7B-1%7D%28%28-%5Cinfty%2C+y%5D%29%29+%26%3D+%5Cmathbb+P%28%28X%2CY%29+%5Cin+%28-%5Cinfty%2C+x%5D+%5Ctimes+%28-%5Cinfty%2C+y%5D%29+%5C%5C+%26%3D+%5Cint_%7B%28-%5Cinfty%2C+x%5D+%5Ctimes+%28-%5Cinfty%2C+y%5D%7D+f_%7BX%2CY%7D%5C%2C+%5Cmathrm+d%5Cmu%5E2+%5C%5C+%26%3D+%5Cint_%7B%28-%5Cinfty%2C+x%5D%7D+%5Cint_%7B%28-%5Cinfty%2C+y%5D%7D+f_%7BX%2CY%7D%5C%2C+%5Cmathrm+d+%5Cmu%5C%2C+%5Cmathrm+d+%5Cmu+%5C%5C+%26%3D+%5Cint_%7B%28-%5Cinfty%2C+x%5D%7D+%5Cint_%7B%28-%5Cinfty%2C+y%5D%7D+f_X+%5Ccdot+f_Y%5C%2C+%5Cmathrm+d+%5Cmu%5C%2C+%5Cmathrm+d+%5Cmu+%5C%5C+%26%3D+%5Cint_%7B%28-%5Cinfty%2C+x%5D%7D+f_X+%5C%2C+%5Cmathrm+d+%5Cmu+%5Ccdot+%5Cint_%7B%28-%5Cinfty%2C+y%5D%7D+f_Y%5C%2C+%5Cmathrm+d+%5Cmu+%5C%5C+%26%3D+%5Cmathbb+P%28X%5E%7B-1%7D%28-%5Cinfty%2C+x%5D%29++%5Ccdot+%5Cmathbb+P%28Y%5E%7B-1%7D%28-%5Cinfty%2C+y%5D%29%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
establishing independence.
In the direction  , we similarly use the Fubini-Tonelli theorem to obtain
, we similarly use the Fubini-Tonelli theorem to obtain
![\begin{aligned} \iint_{(-\infty, x] \times (-\infty, y]} f_{X,Y}\, \mathrm d\mu^2 &= \int_{(-\infty, x]} f_X\, \mathrm d\mu \cdot \int_{(-\infty, y]} f_Y\, \mathrm d\mu \\ &= \int_{(-\infty, x]} \int_{(-\infty, y]} f_X \cdot f_Y\, \mathrm d \mu\, \mathrm d \mu \\ &= \iint_{(-\infty, x] \times (-\infty, y]} f_X \cdot f_Y\, \mathrm d\mu^2, \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Ciint_%7B%28-%5Cinfty%2C+x%5D+%5Ctimes+%28-%5Cinfty%2C+y%5D%7D+f_%7BX%2CY%7D%5C%2C+%5Cmathrm+d%5Cmu%5E2+%26%3D+%5Cint_%7B%28-%5Cinfty%2C+x%5D%7D+f_X%5C%2C+%5Cmathrm+d%5Cmu+%5Ccdot+%5Cint_%7B%28-%5Cinfty%2C+y%5D%7D+f_Y%5C%2C+%5Cmathrm+d%5Cmu+%5C%5C+%26%3D+%5Cint_%7B%28-%5Cinfty%2C+x%5D%7D+%5Cint_%7B%28-%5Cinfty%2C+y%5D%7D+f_X+%5Ccdot+f_Y%5C%2C+%5Cmathrm+d+%5Cmu%5C%2C+%5Cmathrm+d+%5Cmu+%5C%5C+%26%3D+%5Ciint_%7B%28-%5Cinfty%2C+x%5D+%5Ctimes+%28-%5Cinfty%2C+y%5D%7D+f_X+%5Ccdot+f_Y%5C%2C+%5Cmathrm+d%5Cmu%5E2%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
so that  .
.
Henceforth, when are independent and  and
and  , we assume
, we assume  so that
so that 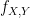 is a meaningful quantity.
is a meaningful quantity.
Corollary 1. Define
![\displaystyle F_{X,Y}(x,y) = \mathbb P((X,Y) \in (-\infty, x] \times (-\infty, y]) \equiv \mathbb P(X \leq x, Y \leq y).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F_%7BX%2CY%7D%28x%2Cy%29+%3D+%5Cmathbb+P%28%28X%2CY%29+%5Cin+%28-%5Cinfty%2C+x%5D+%5Ctimes+%28-%5Cinfty%2C+y%5D%29++%5Cequiv+%5Cmathbb+P%28X+%5Cleq+x%2C+Y+%5Cleq+y%29.&bg=ffffff&fg=000&s=0&c=20201002)
Then are independent and if and only if for any  ,
,

Finally, let’s add these random variables together.
Theorem 1. If are independent  -valued random variables with density functions
-valued random variables with density functions  , then
, then 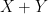 is a random variable with density function
is a random variable with density function

where the right-hand side denotes convolution with respect to :

If is the counting measure, we get

If is the Lebesgue measure, we get

Proof. Denote  so that for any fixed
so that for any fixed  ,
,  if and only if
if and only if  . For any ,
. For any ,

Finally, let’s concretely add two independently normally distributed random variables.
Theorem 2. If  and
and  are independent, then
are independent, then  .
.
Proof. Write  and
and  . Then
. Then

where  are independent. It suffices to prove that
are independent. It suffices to prove that

By construction, for any  , if
, if  , then
, then

Defining  ,
,

By algebruh,

for carefully calculated constants  , in particular, with
, in particular, with

Denoting  , the integral then simplifies to
, the integral then simplifies to

Therefore, denoting  so that
so that  ,
,

Therefore,  , as required.
, as required.
In practice, to compute probabilities involving normal distributions, we define

and tabulate commonly used approximate values of  for
for  , known in the statistics community as a
, known in the statistics community as a  -table. By symmetry,
-table. By symmetry,  . For any
. For any  , since
, since  , we can reduce the computation to
, we can reduce the computation to

By induction, we have the following sampling distribution  .
.
Corollary 2. For independent, identically distributed random variables  ,
,

The central limit theorem claims that even if 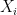 are not normally distributed, converges in distribution to
are not normally distributed, converges in distribution to  . For the limiting distribution to be constant, the equivalent claim is that
. For the limiting distribution to be constant, the equivalent claim is that  converges in distribution to
converges in distribution to  .
.
We have previously stated the special case  and aim to prove it properly using techniques in stochastic calculus. If we have this result, we are emboldened to carry out hypothesis tests, which are commonplace in the STEM fields as well as the data-driven social sciences. We will digress to this application before we dive right back into our ascent toward the central limit theorem.
and aim to prove it properly using techniques in stochastic calculus. If we have this result, we are emboldened to carry out hypothesis tests, which are commonplace in the STEM fields as well as the data-driven social sciences. We will digress to this application before we dive right back into our ascent toward the central limit theorem.
—Joel Kindiak, 23 Jul 25, 2257H

Leave a comment