In this appendix for the multi-armed bandit writeups, I thought I’d revisit my final year project in a relatively readable manner, demonstrating how 



As a set-up, we initialise 

since the conjugate prior of a Bernoulli distribution is the Beta distribution. For the update function, we use

and 



Observe that the map 
![\tilde{\rho} : [0, 1] \to \mathbb R](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D+%3A+%5B0%2C+1%5D+%5Cto+%5Cmathbb+R&bg=ffffff&fg=000&s=0&c=20201002)

Definition 1. Call a risk functional ![\tilde{\rho} : [0,1] \to \mathbb R](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D+%3A+%5B0%2C1%5D+%5Cto+%5Cmathbb+R&bg=ffffff&fg=000&s=0&c=20201002)
If ![\tilde{\rho}([0,1])](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D%28%5B0%2C1%5D%29&bg=ffffff&fg=000&s=0&c=20201002)
![p_1, p_2 \in [0,1]](https://s0.wp.com/latex.php?latex=p_1%2C+p_2+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)
![p \in [0, 1]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)

Lemma 1. If ![p \in [0,1]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)

![p_* \in [0, 1]](https://s0.wp.com/latex.php?latex=p_%2A+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)

Proof. By definition,

By a direct computation,

so that 
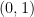
If 





Suppose 

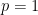


Suppose instead that 

![[r + \epsilon, \tilde{\rho}(p_2)]](https://s0.wp.com/latex.php?latex=%5Br+%2B+%5Cepsilon%2C+%5Ctilde%7B%5Crho%7D%28p_2%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\tilde{\rho}^{-1}( [r + \epsilon, \infty) ) = \tilde{\rho}^{-1}( [r+ \epsilon, \tilde{\rho}(p_2) ] )](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D%5E%7B-1%7D%28+%5Br+%2B+%5Cepsilon%2C+%5Cinfty%29+%29+%3D+%5Ctilde%7B%5Crho%7D%5E%7B-1%7D%28+%5Br%2B+%5Cepsilon%2C+%5Ctilde%7B%5Crho%7D%28p_2%29+%5D+%29&bg=ffffff&fg=000&s=0&c=20201002)
is closed and bounded, and thus compact by the Heine-Borel theorem. Since the sets
![\begin{aligned} C_1(\epsilon) &:= \tilde{\rho}^{-1}( [r+ \epsilon, \infty) ) \cap [0, p],\\ C_2 (\epsilon)&:= \tilde{\rho}^{-1}( [r+ \epsilon, \infty) ) \cap [p, 1], \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+C_1%28%5Cepsilon%29+%26%3A%3D+%5Ctilde%7B%5Crho%7D%5E%7B-1%7D%28+%5Br%2B+%5Cepsilon%2C+%5Cinfty%29+%29+%5Ccap+%5B0%2C+p%5D%2C%5C%5C+C_2+%28%5Cepsilon%29%26%3A%3D+%5Ctilde%7B%5Crho%7D%5E%7B-1%7D%28+%5Br%2B+%5Cepsilon%2C+%5Cinfty%29+%29+%5Ccap+%5Bp%2C+1%5D%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
are also compact, we can define their extrema

At least one of these sets will always be non-empty, since ![r_2 \in [0, 1]](https://s0.wp.com/latex.php?latex=r_2+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)






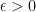
Using monotonicity properties, 


Now it is clear that 

![q_j \in [0,1]](https://s0.wp.com/latex.php?latex=q_j+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)


Define 


Taking 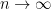

Finally, choose

to deduce that

Remark 1. Most arguments in Lemma 1 boils down to the compactness of ![[a, b]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%5D&bg=ffffff&fg=000&s=0&c=20201002)

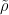

- Generalise the risk functional to
, where
is a space of probability distributions that is compact under a suitable metric or topology.
- We would probably need to partition
into
.
- During the sequential argument, we could use sequential compactness to concoct a convergent subsequence
in place of a by-default convergent subsequence. That way, we might still be able to infimise over
via
.
- Since we only care about infimising, we do not need the strength of full continuity for
; rather we would only require its lower semi-continuity property, which could be conceived as the “lower half” of vanilla continuity.
Thanks to the continuity of
Theorem 1. Fix 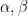

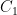


Proof. Denote the closed (and thus, compact) sets 
![S_2 := \tilde{\rho}^{-1}((-\infty, r])](https://s0.wp.com/latex.php?latex=S_2+%3A%3D+%5Ctilde%7B%5Crho%7D%5E%7B-1%7D%28%28-%5Cinfty%2C+r%5D%29&bg=ffffff&fg=000&s=0&c=20201002)

for brevity. Using the conjugate-prior connection between Beta distributions and Bernoulli distributions, since the sum of i.i.d. Bernoullis yield a Binomial,

where 



![\begin{aligned} f_{X|Y}(x \mid y) &= \frac{ f_{Y\mid X}(y \mid x) \cdot f_X(x) }{ f_Y(y) } \\ &= \frac{ f_{Y\mid X}(y \mid x) \cdot f_X(x) }{ \int_{[0,1]} f_{Y \mid X}(y \mid x) \cdot f_X(x) \, \mathrm dx} \\ &= \frac{ {n \choose y} \cdot x^{y} (1-x)^{n-y} \cdot 1 }{ \int_{[0,1]} {n \choose y} \cdot x^{y} (1-x)^{n-y} \cdot 1 \, \mathrm dx} \\ &= \frac{ x^{y} (1-x)^{n-y} }{ \int_{[0,1]} x^{y} (1-x)^{n-y} \, \mathrm dx}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+f_%7BX%7CY%7D%28x+%5Cmid+y%29+%26%3D+%5Cfrac%7B+f_%7BY%5Cmid+X%7D%28y+%5Cmid+x%29+%5Ccdot+f_X%28x%29+%7D%7B+f_Y%28y%29+%7D+%5C%5C+%26%3D+%5Cfrac%7B+f_%7BY%5Cmid+X%7D%28y+%5Cmid+x%29+%5Ccdot+f_X%28x%29+%7D%7B+%5Cint_%7B%5B0%2C1%5D%7D++f_%7BY+%5Cmid+X%7D%28y+%5Cmid+x%29+%5Ccdot+f_X%28x%29+%5C%2C+%5Cmathrm+dx%7D+%5C%5C+%26%3D+%5Cfrac%7B+%7Bn+%5Cchoose+y%7D+%5Ccdot+x%5E%7By%7D+%281-x%29%5E%7Bn-y%7D+%5Ccdot+1+%7D%7B+%5Cint_%7B%5B0%2C1%5D%7D++%7Bn+%5Cchoose+y%7D++%5Ccdot+x%5E%7By%7D+%281-x%29%5E%7Bn-y%7D+%5Ccdot++1+%5C%2C+%5Cmathrm+dx%7D+%5C%5C+%26%3D+%5Cfrac%7B+x%5E%7By%7D+%281-x%29%5E%7Bn-y%7D++%7D%7B+%5Cint_%7B%5B0%2C1%5D%7D++x%5E%7By%7D+%281-x%29%5E%7Bn-y%7D+%5C%2C+%5Cmathrm+dx%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
In particular,
![\begin{aligned} \mathbb P(X \in S \mid Y = \alpha) &= \int_{S} f_{X\mid Y}(x \mid \alpha)\, \mathrm dx \\ &= \int_{S} \frac{ x^{y} (1-x)^{n-y} }{ \int_{[0,1]} x^{\alpha} (1-x)^{n-\alpha} \, \mathrm dx}, \mathrm dx \\ &= \frac{ \int_{S} x^{\alpha} (1-x)^{n-\alpha} \, \mathrm dx }{ \int_{[0,1]} x^{\alpha} (1-x)^{n-\alpha} \, \mathrm dx} . \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+P%28X+%5Cin+S+%5Cmid+Y+%3D+%5Calpha%29+%26%3D+%5Cint_%7BS%7D+f_%7BX%5Cmid+Y%7D%28x+%5Cmid+%5Calpha%29%5C%2C+%5Cmathrm+dx+%5C%5C+%26%3D+%5Cint_%7BS%7D+%5Cfrac%7B+x%5E%7By%7D+%281-x%29%5E%7Bn-y%7D++%7D%7B+%5Cint_%7B%5B0%2C1%5D%7D++x%5E%7B%5Calpha%7D+%281-x%29%5E%7Bn-%5Calpha%7D+%5C%2C+%5Cmathrm+dx%7D%2C+%5Cmathrm+dx+%5C%5C+%26%3D+%5Cfrac%7B+%5Cint_%7BS%7D++x%5E%7B%5Calpha%7D+%281-x%29%5E%7Bn-%5Calpha%7D+%5C%2C+%5Cmathrm+dx+%7D%7B+%5Cint_%7B%5B0%2C1%5D%7D++x%5E%7B%5Calpha%7D+%281-x%29%5E%7Bn-%5Calpha%7D+%5C%2C+%5Cmathrm+dx%7D+.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
In what follows, set

where 


would be a somewhat confusing random variable, and the tail concentration bounds are conditioned on 
Remark 2. The challenge to generalise this result comes in require concrete distributions to work with, and so our general version would need to be “simplified” into, or expressed in terms of, a more computationally tractable option. One possible area for exploration would be considering the compact set of bounded-mean Gaussian distributions

where 
These upper bounds are, with more technical bookkeeping, ultimately responsible for the asymptotically optimal regret bounds. And since contiunity is a relatively benign condition, many risk functionals enjoy the tail upper bound of Theorem 1, and potentially, the asymptotically optimal regret bound for
Example 1. Given continuous risk functionals 
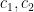

However, a proper proof of the Thompson sampling algorithm requires tail lower bounds. To achieve that goal, we introduce the notion of a dominant risk functional.
Definition 2. For any
![V(p, 0) = [p, 1],\quad V(p, 1) = [0,p].](https://s0.wp.com/latex.php?latex=V%28p%2C+0%29+%3D+%5Bp%2C+1%5D%2C%5Cquad++V%28p%2C+1%29+%3D+%5B0%2Cp%5D.&bg=ffffff&fg=000&s=0&c=20201002)
We say that a risk functional ![q \in [0,1]](https://s0.wp.com/latex.php?latex=q+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)


and 
In the original version, it was this concept that I dreamt of while struggling to solve the bandit problem. I prayed long and hard, and solved the problem in my dream thrice. I was shocked, and said to myself, “I must be dreaming. I will wake up and write down my solution.” And so at 4.30am sometime in February 2022, I did just that, and after a sanity check at 8.30am the next morning, concluded that the solution was correct.
In any case, the dominant risk functional property guarantees for us a much-needed tail lower bound.
Theorem 2. Fix 

Proof. Fix
and 

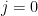
![\begin{aligned} \mathbb P(\tilde{\rho}(X) \in [r, \infty)) &\geq \mathbb P( \tilde{\rho}(X) \in \tilde{\rho}( V(q,0) )) \\ &= \mathbb P( \tilde{\rho}(X) \in \tilde{\rho}( [q, 1] )) \\ &= \mathbb P(X \in [q, 1]) \\ &= \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\int_q^1 x^{\alpha-1} (1-x)^{\beta-1}\, \mathrm dx \\ &\geq \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)} \cdot q^{\alpha-1} \int_q^1 x^{\beta-1}\, \mathrm dx \\ &=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)} \cdot q^{\alpha-1} \cdot \frac{(1-q)^{\beta}}{\beta} \\ &=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)} \cdot \underbrace{ \frac{\beta}{q} }_{\geq \beta} \cdot \underbrace{ \frac{q^{\alpha}}{(\alpha/n)^{\alpha}} \cdot \frac{(1-q)^{\beta}}{(\beta/n)^{\beta}} }_{\exp(-n \cdot \mathrm{KL}( \alpha/n, q ) )} \cdot \frac{\alpha^{\alpha} \cdot \beta^{\beta}}{n^n} \\ &\geq \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta+1)} \cdot \frac{\alpha^{\alpha} \cdot \beta^{\beta}}{n^n} \cdot \exp(-n \cdot \mathrm{KL}( \alpha/n, q ) ) . \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+P%28%5Ctilde%7B%5Crho%7D%28X%29+%5Cin+%5Br%2C+%5Cinfty%29%29+%26%5Cgeq+%5Cmathbb+P%28+%5Ctilde%7B%5Crho%7D%28X%29+%5Cin+%5Ctilde%7B%5Crho%7D%28+V%28q%2C0%29+%29%29+%5C%5C+%26%3D+%5Cmathbb+P%28+%5Ctilde%7B%5Crho%7D%28X%29+%5Cin+%5Ctilde%7B%5Crho%7D%28+%5Bq%2C+1%5D+%29%29+%5C%5C+%26%3D+%5Cmathbb+P%28X+%5Cin+%5Bq%2C+1%5D%29+%5C%5C+%26%3D+%5Cfrac%7B%5CGamma%28%5Calpha%2B%5Cbeta%29%7D%7B%5CGamma%28%5Calpha%29%5CGamma%28%5Cbeta%29%7D%5Cint_q%5E1+x%5E%7B%5Calpha-1%7D+%281-x%29%5E%7B%5Cbeta-1%7D%5C%2C+%5Cmathrm+dx+%5C%5C+%26%5Cgeq+%5Cfrac%7B%5CGamma%28%5Calpha%2B%5Cbeta%29%7D%7B%5CGamma%28%5Calpha%29%5CGamma%28%5Cbeta%29%7D+%5Ccdot+q%5E%7B%5Calpha-1%7D+%5Cint_q%5E1+x%5E%7B%5Cbeta-1%7D%5C%2C+%5Cmathrm+dx+%5C%5C+%26%3D%5Cfrac%7B%5CGamma%28%5Calpha%2B%5Cbeta%29%7D%7B%5CGamma%28%5Calpha%29%5CGamma%28%5Cbeta%29%7D+%5Ccdot+q%5E%7B%5Calpha-1%7D+%5Ccdot+%5Cfrac%7B%281-q%29%5E%7B%5Cbeta%7D%7D%7B%5Cbeta%7D+%5C%5C+%26%3D%5Cfrac%7B%5CGamma%28%5Calpha%2B%5Cbeta%29%7D%7B%5CGamma%28%5Calpha%29%5CGamma%28%5Cbeta%29%7D+%5Ccdot+%5Cunderbrace%7B+%5Cfrac%7B%5Cbeta%7D%7Bq%7D+%7D_%7B%5Cgeq+%5Cbeta%7D+%5Ccdot+%5Cunderbrace%7B+%5Cfrac%7Bq%5E%7B%5Calpha%7D%7D%7B%28%5Calpha%2Fn%29%5E%7B%5Calpha%7D%7D+%5Ccdot+%5Cfrac%7B%281-q%29%5E%7B%5Cbeta%7D%7D%7B%28%5Cbeta%2Fn%29%5E%7B%5Cbeta%7D%7D+%7D_%7B%5Cexp%28-n+%5Ccdot+%5Cmathrm%7BKL%7D%28+%5Calpha%2Fn%2C+q+%29+%29%7D+%5Ccdot+%5Cfrac%7B%5Calpha%5E%7B%5Calpha%7D+%5Ccdot+%5Cbeta%5E%7B%5Cbeta%7D%7D%7Bn%5En%7D+%5C%5C+%26%5Cgeq+%5Cfrac%7B%5CGamma%28%5Calpha%2B%5Cbeta%29%7D%7B%5CGamma%28%5Calpha%29%5CGamma%28%5Cbeta%2B1%29%7D+%5Ccdot+%5Cfrac%7B%5Calpha%5E%7B%5Calpha%7D+%5Ccdot+%5Cbeta%5E%7B%5Cbeta%7D%7D%7Bn%5En%7D+%5Ccdot+%5Cexp%28-n+%5Ccdot+%5Cmathrm%7BKL%7D%28+%5Calpha%2Fn%2C+q+%29+%29+.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
The rest of the calculation follows from the proof of Lemma 2 in Baudry et al (2021) by using Stirling’s approximation, and yields the desired lower bound

Remark 3. This tail bound eventually bounds all other terms by constants, once the exponentials cancel other exponentials out in subsequent calculations. The dream dealt with the slightly more general case 

Remark 4. The bounds in Theorems 1 and 2 work precisely for a special class of distributions, namely Bernoulli bandits (or slightly more generally, multinomial bandits). For other common classes of distributions, like Gaussians for example, we would need different tail lower bounds. Moreover, we would need to work with specific conjugate pairs of distributions, and approximate non-parametric bandits using parametric ones, which leads to messier approximation-controlling calculations when evaluating the regret bound.
But you might wonder—what functionals could pass the dominant risk functional criteria?
Lemma 2. Let ![c \in [0, 1]](https://s0.wp.com/latex.php?latex=c+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\tilde{\rho}|_{[0,c]}](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D%7C_%7B%5B0%2Cc%5D%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\tilde{\rho}|_{[c,1]}](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D%7C_%7B%5Bc%2C1%5D%7D&bg=ffffff&fg=000&s=0&c=20201002)
Proof. Fix

Set 

![q \in [0, c]](https://s0.wp.com/latex.php?latex=q+%5Cin+%5B0%2C+c%5D&bg=ffffff&fg=000&s=0&c=20201002)
![q \in [c, 1]](https://s0.wp.com/latex.php?latex=q+%5Cin+%5Bc%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)

![s \in [0, q]](https://s0.wp.com/latex.php?latex=s+%5Cin+%5B0%2C+q%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\tilde{\rho}(V(q,1)) = \tilde{\rho}([0, q]) \subseteq [\tilde{\rho}(q), \infty),](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D%28V%28q%2C1%29%29+%3D+%5Ctilde%7B%5Crho%7D%28%5B0%2C+q%5D%29+%5Csubseteq+%5B%5Ctilde%7B%5Crho%7D%28q%29%2C+%5Cinfty%29%2C&bg=ffffff&fg=000&s=0&c=20201002)
as required. In the latter, ![s \in [q,1]](https://s0.wp.com/latex.php?latex=s+%5Cin+%5Bq%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\tilde{\rho}(V(q,0)) = \tilde{\rho}([q, 1]) \subseteq [\tilde{\rho}(q), \infty),](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D%28V%28q%2C0%29%29+%3D+%5Ctilde%7B%5Crho%7D%28%5Bq%2C+1%5D%29+%5Csubseteq+%5B%5Ctilde%7B%5Crho%7D%28q%29%2C+%5Cinfty%29%2C&bg=ffffff&fg=000&s=0&c=20201002)
as required. If 
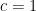
Remark 5. For two risk functionals 



Example 2. Given 


![\phi : [0, 1] \to [0,\infty)](https://s0.wp.com/latex.php?latex=%5Cphi+%3A+%5B0%2C+1%5D+%5Cto+%5B0%2C%5Cinfty%29&bg=ffffff&fg=000&s=0&c=20201002)

- Expected value:
,
- Conditional value-at-risk:
- Proportional hazard:
- Lookback:
- Spectral risk:
- Entropic risk:
- Dual power distortion:
- Wang transform:
- Logarithmic distortion:
-Sharpe ratio:









Remark 6. Since the Sharpe ratio is not well-defined at 

![[0, (1-\delta)^{-1}) \supseteq [0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C+%281-%5Cdelta%29%5E%7B-1%7D%29+%5Csupseteq+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)



satisfies the requirements of Lemma 1, and we recover its useful tail bounds.
Lemma 3. If ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)

Proof. We claim that no matter what,
- If
, then
- If
, then
- If there exists
such that
, then the intermediate value property of derivatives yields
such that
. Since
is non-increasing and
.
In all three cases,
Remark 7. More generally, if ![t \in [0, 1]](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
![x, y \in [0, 1]](https://s0.wp.com/latex.php?latex=x%2C+y+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)

the risk functional
Example 3. Given
- Second moment:
- Negative variance:
- Mean-variance:
- Exponential tilt:
- Quadratic utility:
![\rho_{\text{SM}}(\nu_p) = \mathbb E[X^2] = p](https://s0.wp.com/latex.php?latex=%5Crho_%7B%5Ctext%7BSM%7D%7D%28%5Cnu_p%29+%3D+%5Cmathbb+E%5BX%5E2%5D+%3D+p&bg=ffffff&fg=000&s=0&c=20201002)




Furthermore, for two risk functionals 

Therefore, most risk functionals as listed in Examples 1, 2, and 3 are the ones that most people care about are in fact continuous and dominant, and therefore, by passing the relevant arguments through much book-keeping, enjoy the asymptotically optimal regret bound for
Theorem 3. The regret bound of

Proof. Follow the proof of Theorem 1 in Chang and Tan (2022), and apply Theorems 1 and 2 in the analysis. Left as an exercise (effectively) in algebra and mildly clever calculus.
Oh, by the way, with the help of ChatGPT, here’s a Jupyter writeup of the implemented algorithm and some pretty pictures!
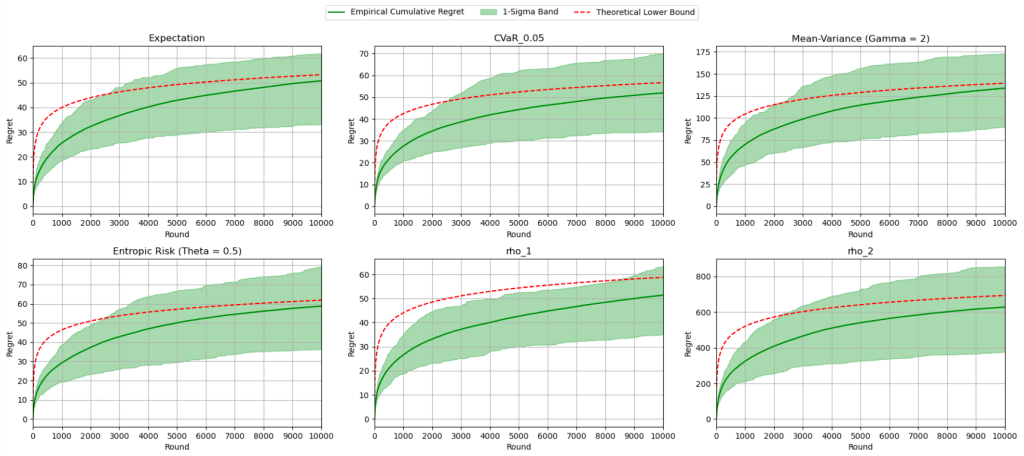
The red curve indicates the theoretical asymptotic lower bound, and each diagram reflects the algorithm running for a fixed 


And for them all, the asymptotic lower bound lies happily in their 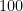
And with that, we are truly done. Happy lunar new year!
—Joel Kindiak, 16 Feb 26, 1131H
 be a real-valued random variable with finite expectation. For any
be a real-valued random variable with finite expectation. For any 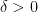 ,
,![\displaystyle \mathbb P(|X| \geq \delta) \leq \frac{\mathbb E[|X|]}{\delta}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+P%28%7CX%7C+%5Cgeq+%5Cdelta%29+%5Cleq+%5Cfrac%7B%5Cmathbb+E%5B%7CX%7C%5D%7D%7B%5Cdelta%7D.&bg=ffffff&fg=000&s=0&c=20201002)
![\displaystyle \mathbb P(|X - \mathbb E[X]| \geq \delta ) \leq \frac{\mathrm{Var}(X)}{\delta^2}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+P%28%7CX+-+%5Cmathbb+E%5BX%5D%7C+%5Cgeq+%5Cdelta+%29+%5Cleq+%5Cfrac%7B%5Cmathrm%7BVar%7D%28X%29%7D%7B%5Cdelta%5E2%7D.&bg=ffffff&fg=000&s=0&c=20201002)
![\begin{aligned} \mathbb E[|X|] &= \mathbb E[|X| \cdot \mathbb I_{[\delta, \infty)}] + \mathbb E[|X| \cdot \mathbb I_{(-\infty, \delta)}] \\ &\geq \mathbb E[\delta \cdot \mathbb I_{[\delta, \infty)}] + 0\\ &= \delta \cdot \mathbb E[\mathbb I_{[\delta, \infty)} ] \\ &= \delta \cdot \mathbb P(|X| \geq \delta). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5B%7CX%7C%5D+%26%3D+%5Cmathbb+E%5B%7CX%7C+%5Ccdot+%5Cmathbb+I_%7B%5B%5Cdelta%2C+%5Cinfty%29%7D%5D+%2B+%5Cmathbb+E%5B%7CX%7C+%5Ccdot+%5Cmathbb+I_%7B%28-%5Cinfty%2C+%5Cdelta%29%7D%5D+%5C%5C+%26%5Cgeq+%5Cmathbb+E%5B%5Cdelta+%5Ccdot+%5Cmathbb+I_%7B%5B%5Cdelta%2C+%5Cinfty%29%7D%5D+%2B+0%5C%5C+%26%3D+%5Cdelta+%5Ccdot+%5Cmathbb+E%5B%5Cmathbb+I_%7B%5B%5Cdelta%2C+%5Cinfty%29%7D+%5D+%5C%5C+%26%3D+%5Cdelta+%5Ccdot+%5Cmathbb+P%28%7CX%7C+%5Cgeq+%5Cdelta%29.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
![(X - \mathbb E[X])^2](https://s0.wp.com/latex.php?latex=%28X+-+%5Cmathbb+E%5BX%5D%29%5E2&bg=ffffff&fg=000&s=0&c=20201002) to get
to get![\begin{aligned} \mathbb P(|X - \mathbb E[X]| \geq \delta) &= \mathbb P( (X - \mathbb E[X])^2 \geq \delta^2 ) \\ &= \frac{\mathbb E[(X - \mathbb E[X])^2]}{\delta^2} \\ &\leq \frac{\mathrm{Var}(X)}{\delta^2}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+P%28%7CX+-+%5Cmathbb+E%5BX%5D%7C+%5Cgeq+%5Cdelta%29+%26%3D+%5Cmathbb+P%28+%28X+-+%5Cmathbb+E%5BX%5D%29%5E2+%5Cgeq+%5Cdelta%5E2+%29+%5C%5C+%26%3D+%5Cfrac%7B%5Cmathbb+E%5B%28X+-+%5Cmathbb+E%5BX%5D%29%5E2%5D%7D%7B%5Cdelta%5E2%7D+%5C%5C+%26%5Cleq+%5Cfrac%7B%5Cmathrm%7BVar%7D%28X%29%7D%7B%5Cdelta%5E2%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
 and denote
and denote  . Define the i.i.d. random variables
. Define the i.i.d. random variables  by
by  , so that
, so that  . Define
. Define
 . In this case, we say that
. In this case, we say that  in probability.
in probability.![\mathbb E[\xi_n] = p](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%5Cxi_n%5D+%3D+p&bg=ffffff&fg=000&s=0&c=20201002) and
and  ,
,![\displaystyle \mathbb E[\bar \xi_n] = p,\quad \mathrm{Var}(\bar \xi_n) = \frac{p(1-p)}{n}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5B%5Cbar+%5Cxi_n%5D+%3D+p%2C%5Cquad+%5Cmathrm%7BVar%7D%28%5Cbar+%5Cxi_n%29+%3D+%5Cfrac%7Bp%281-p%29%7D%7Bn%7D.&bg=ffffff&fg=000&s=0&c=20201002)

 and its c.d.f. by
and its c.d.f. by  be real-valued random variables. Suppose for any thrice-differentiable
be real-valued random variables. Suppose for any thrice-differentiable  such that
such that  are bounded,
are bounded,![\displaystyle \lim_{n \to \infty} \mathbb E[f(X_n)] = \mathbb E[f(Z)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cmathbb+E%5Bf%28X_n%29%5D+%3D+%5Cmathbb+E%5Bf%28Z%29%5D.&bg=ffffff&fg=000&s=0&c=20201002)
 ,
,
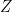 is continuous, there exists
is continuous, there exists 
 . Define thrice-differentiable bounded functions
. Define thrice-differentiable bounded functions ![f, F : \mathbb R \to [0, 1]](https://s0.wp.com/latex.php?latex=f%2C+F+%3A+%5Cmathbb+R+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) with bounded first, second, and third derivatives such that
with bounded first, second, and third derivatives such that![f|_{(-\infty, z-\delta]} = 1,\quad f|_{[z, \infty)} = 0,\quad F|_{(-\infty, z]} = 1,\quad F|_{[z+\delta, \infty)} = 0.](https://s0.wp.com/latex.php?latex=f%7C_%7B%28-%5Cinfty%2C+z-%5Cdelta%5D%7D+%3D+1%2C%5Cquad++f%7C_%7B%5Bz%2C+%5Cinfty%29%7D+%3D+0%2C%5Cquad++F%7C_%7B%28-%5Cinfty%2C+z%5D%7D+%3D+1%2C%5Cquad++F%7C_%7B%5Bz%2B%5Cdelta%2C+%5Cinfty%29%7D+%3D+0.&bg=ffffff&fg=000&s=0&c=20201002)
![\displaystyle \lim_{n \to \infty} \mathbb E[f(X_n)] = \mathbb P(Z \leq z -\delta) = \Phi(z-\delta) \geq \Phi(z) - \epsilon.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cmathbb+E%5Bf%28X_n%29%5D+%3D+%5Cmathbb+P%28Z+%5Cleq+z+-%5Cdelta%29+%3D+%5CPhi%28z-%5Cdelta%29+%5Cgeq+%5CPhi%28z%29+-+%5Cepsilon.&bg=ffffff&fg=000&s=0&c=20201002)
![\mathbb E[F(X_n)] < \Phi(z) + \epsilon](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BF%28X_n%29%5D+%3C+%5CPhi%28z%29+%2B+%5Cepsilon&bg=ffffff&fg=000&s=0&c=20201002) . Since
. Since ![f \leq \mathbb I_{(-\infty, z]} \leq F](https://s0.wp.com/latex.php?latex=f+%5Cleq+%5Cmathbb+I_%7B%28-%5Cinfty%2C+z%5D%7D+%5Cleq+F&bg=ffffff&fg=000&s=0&c=20201002) point-wise, for sufficiently large
point-wise, for sufficiently large ![\Phi(z) - \epsilon < \mathbb E[f(X_n)] \leq \underbrace{ \mathbb E[ \mathbb I_{(-\infty, z]} ] }_{ \mathbb P(X_n \leq z)} \leq \mathbb E[F(X_n)] < \Phi(z) + \epsilon,](https://s0.wp.com/latex.php?latex=%5CPhi%28z%29+-+%5Cepsilon+%3C+%5Cmathbb+E%5Bf%28X_n%29%5D+%5Cleq+%5Cunderbrace%7B+%5Cmathbb+E%5B+%5Cmathbb+I_%7B%28-%5Cinfty%2C+z%5D%7D+%5D+%7D_%7B+%5Cmathbb+P%28X_n+%5Cleq+z%29%7D+%5Cleq+%5Cmathbb+E%5BF%28X_n%29%5D+%3C+%5CPhi%28z%29+%2B+%5Cepsilon%2C&bg=ffffff&fg=000&s=0&c=20201002)
 , as required.
, as required. be i.i.d. with mean
be i.i.d. with mean  and variance
and variance 
 in distribution.
in distribution. that are independent of
that are independent of  and
and  , define
, define
 and
and  . The key idea is using Lemma 2 to conclude our proof. Fix any thrice-differentiable
. The key idea is using Lemma 2 to conclude our proof. Fix any thrice-differentiable ![\displaystyle \lim_{n \to \infty} \mathbb E[f(Z_{n,n})] = \mathbb E[f(Z_{n,0})].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cmathbb+E%5Bf%28Z_%7Bn%2Cn%7D%29%5D+%3D+%5Cmathbb+E%5Bf%28Z_%7Bn%2C0%7D%29%5D.&bg=ffffff&fg=000&s=0&c=20201002)
 such that for
such that for  ,
,![\displaystyle |\mathbb E[f(Z_{n,n})] - \mathbb E[f(Z_{n,0})]| < \epsilon.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7C%5Cmathbb+E%5Bf%28Z_%7Bn%2Cn%7D%29%5D+-+%5Cmathbb+E%5Bf%28Z_%7Bn%2C0%7D%29%5D%7C+%3C+%5Cepsilon.&bg=ffffff&fg=000&s=0&c=20201002)
 and
and  , there exists
, there exists  between them such that
between them such that

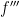 is bounded, there exists
is bounded, there exists 
 ,
,
 and its complement
and its complement
 in the “good event”
in the “good event”  by
by![\displaystyle |f''(C_{n,i}) - f''(S_{n,i})| \leq \epsilon \quad \Rightarrow \quad \mathbb E[|R_{n,i}| \cdot \mathbb I_G] \leq \frac{\epsilon}{2n} \cdot \mathbb E[X_i^2] = \frac{\epsilon}{2n}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7Cf%27%27%28C_%7Bn%2Ci%7D%29+-+f%27%27%28S_%7Bn%2Ci%7D%29%7C+%5Cleq+%5Cepsilon+%5Cquad+%5CRightarrow+%5Cquad+%5Cmathbb+E%5B%7CR_%7Bn%2Ci%7D%7C+%5Ccdot+%5Cmathbb+I_G%5D+%5Cleq+%5Cfrac%7B%5Cepsilon%7D%7B2n%7D+%5Ccdot+%5Cmathbb+E%5BX_i%5E2%5D+%3D+%5Cfrac%7B%5Cepsilon%7D%7B2n%7D.&bg=ffffff&fg=000&s=0&c=20201002)
 , since
, since  for some
for some  ,
,![\displaystyle \mathbb E[|R_{n,i}| \cdot \mathbb I_{G^c}] \leq \frac{M}{n} \cdot \mathbb E[X_i^2 \cdot \mathbb I_{G^c}] \leq \frac Mn \cdot \mathbb E[\mathbb I_{G^c}].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5B%7CR_%7Bn%2Ci%7D%7C+%5Ccdot+%5Cmathbb+I_%7BG%5Ec%7D%5D+%5Cleq+%5Cfrac%7BM%7D%7Bn%7D+%5Ccdot+%5Cmathbb+E%5BX_i%5E2+%5Ccdot+%5Cmathbb+I_%7BG%5Ec%7D%5D+%5Cleq+%5Cfrac+Mn+%5Ccdot+%5Cmathbb+E%5B%5Cmathbb+I_%7BG%5Ec%7D%5D.&bg=ffffff&fg=000&s=0&c=20201002)
![\begin{aligned}\mathbb E[\mathbb I_{G^c}] &= \mathbb P(|X_i| \geq \delta \sqrt n) \leq \frac{1}{\delta \cdot \sqrt{n}^2} = \frac{1}{n \delta}.\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cmathbb+E%5B%5Cmathbb+I_%7BG%5Ec%7D%5D+%26%3D+%5Cmathbb+P%28%7CX_i%7C+%5Cgeq+%5Cdelta+%5Csqrt+n%29+%5Cleq+%5Cfrac%7B1%7D%7B%5Cdelta+%5Ccdot+%5Csqrt%7Bn%7D%5E2%7D+%3D+%5Cfrac%7B1%7D%7Bn+%5Cdelta%7D.%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\displaystyle \mathbb E[|R_{n,i}|] = \mathbb E[|R_{n,i}| \cdot \mathbb I_G] + \mathbb E[|R_{n,i}| \cdot \mathbb I_{G^c}] \leq \left( \frac{\epsilon}{2} + \frac{M}{n\delta} \right) \cdot \frac 1n.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5B%7CR_%7Bn%2Ci%7D%7C%5D+%3D+%5Cmathbb+E%5B%7CR_%7Bn%2Ci%7D%7C+%5Ccdot+%5Cmathbb+I_G%5D+%2B+%5Cmathbb+E%5B%7CR_%7Bn%2Ci%7D%7C+%5Ccdot+%5Cmathbb+I_%7BG%5Ec%7D%5D+%5Cleq+%5Cleft%28+%5Cfrac%7B%5Cepsilon%7D%7B2%7D+%2B+%5Cfrac%7BM%7D%7Bn%5Cdelta%7D+%5Cright%29+%5Ccdot+%5Cfrac+1n.&bg=ffffff&fg=000&s=0&c=20201002)
 yields
yields ![\mathbb E[|R_{n,i}|] \leq \epsilon/n](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%7CR_%7Bn%2Ci%7D%7C%5D+%5Cleq+%5Cepsilon%2Fn&bg=ffffff&fg=000&s=0&c=20201002) . Plugging in the left-hand side of
. Plugging in the left-hand side of ![\displaystyle |\mathbb E[f(Z_{n,i})] - \mathbb E[f(S_{n,i})] - \mathbb E[f''(S_{n,i}) ] / 2n |\leq \frac{\epsilon}{n}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7C%5Cmathbb+E%5Bf%28Z_%7Bn%2Ci%7D%29%5D+-+%5Cmathbb+E%5Bf%28S_%7Bn%2Ci%7D%29%5D+-+%5Cmathbb+E%5Bf%27%27%28S_%7Bn%2Ci%7D%29+%5D+%2F+2n+%7C%5Cleq+%5Cfrac%7B%5Cepsilon%7D%7Bn%7D.&bg=ffffff&fg=000&s=0&c=20201002)
 , so that we have the bound
, so that we have the bound![\displaystyle |\mathbb E[f(Z_{n,i-1})] - \mathbb E[f(S_{n,i})] - \mathbb E[f''(S_{n,i}) ] / 2n |\leq \frac{\epsilon}{n}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7C%5Cmathbb+E%5Bf%28Z_%7Bn%2Ci-1%7D%29%5D+-+%5Cmathbb+E%5Bf%28S_%7Bn%2Ci%7D%29%5D+-+%5Cmathbb+E%5Bf%27%27%28S_%7Bn%2Ci%7D%29+%5D+%2F+2n+%7C%5Cleq+%5Cfrac%7B%5Cepsilon%7D%7Bn%7D.&bg=ffffff&fg=000&s=0&c=20201002)
![\displaystyle |\mathbb E[f(Z_{n,i})] - \mathbb E [f(Z_{n,i-1})]| \leq \frac{\epsilon}{n} + \frac{\epsilon}{n} = \frac{2\epsilon}{n}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7C%5Cmathbb+E%5Bf%28Z_%7Bn%2Ci%7D%29%5D+-+%5Cmathbb+E+%5Bf%28Z_%7Bn%2Ci-1%7D%29%5D%7C++%5Cleq+%5Cfrac%7B%5Cepsilon%7D%7Bn%7D+%2B+%5Cfrac%7B%5Cepsilon%7D%7Bn%7D+%3D+%5Cfrac%7B2%5Cepsilon%7D%7Bn%7D.&bg=ffffff&fg=000&s=0&c=20201002)
![\begin{aligned} |\mathbb E[f(Z_{n,n})] - \mathbb E [f(Z_{n,0})]| &\leq \sum_{i=1}^n |\mathbb E[f(Z_{n,i})] - \mathbb E [f(Z_{n,i-1})]| \leq \sum_{i=1}^n \frac{2\epsilon}n = 2\epsilon. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%7C%5Cmathbb+E%5Bf%28Z_%7Bn%2Cn%7D%29%5D+-+%5Cmathbb+E+%5Bf%28Z_%7Bn%2C0%7D%29%5D%7C+%26%5Cleq+%5Csum_%7Bi%3D1%7D%5En+%7C%5Cmathbb+E%5Bf%28Z_%7Bn%2Ci%7D%29%5D+-+%5Cmathbb+E+%5Bf%28Z_%7Bn%2Ci-1%7D%29%5D%7C+%5Cleq+%5Csum_%7Bi%3D1%7D%5En+%5Cfrac%7B2%5Cepsilon%7Dn+%3D+2%5Cepsilon.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
 with
with  to complete the argument.
to complete the argument. ,
,
 for i.i.d.
for i.i.d. 

 are i.i.d. with mean
are i.i.d. with mean 

 . Write
. Write  for i.i.d.
for i.i.d.  and
and

 are i.i.d. with mean
are i.i.d. with mean 
 , what is the distribution of
, what is the distribution of  ? Unfortunately, in the most extreme cases, this answer is trivial.
? Unfortunately, in the most extreme cases, this answer is trivial. and
and  . Then
. Then  and
and  .
. , since
, since  , by a change of variables,
, by a change of variables, 

 so that
so that  is entirely dependent—
is entirely dependent— correlated even—to the random variable
correlated even—to the random variable  being independent, we don’t have a general formula for any
being independent, we don’t have a general formula for any  . Nevertheless, the independent case proves to be far more useful in reality—for instance, the exam scores of two students are effectively independent barring (sufficiently drastic) externalities.
. Nevertheless, the independent case proves to be far more useful in reality—for instance, the exam scores of two students are effectively independent barring (sufficiently drastic) externalities. to be independent. We have previously seen that two events
to be independent. We have previously seen that two events  are called independent if
are called independent if  .
. forms a
forms a  -algebra, called the
-algebra, called the  , also known as sub-
, also known as sub- , we say that
, we say that  are independent if for any
are independent if for any  ,
,  are independent.
are independent. are independent.
are independent. and
and  , where
, where  denotes either the counting measure
denotes either the counting measure  or the Lebesgue measure
or the Lebesgue measure  . Let
. Let  be the product of two copies of
be the product of two copies of  .
.

![F_X(x) := \mathbb P(X \in (-\infty, x]) \equiv \mathbb P(X \leq x),\quad F_Y(y) := \mathbb P( Y \leq y).](https://s0.wp.com/latex.php?latex=F_X%28x%29+%3A%3D+%5Cmathbb+P%28X+%5Cin+%28-%5Cinfty%2C+x%5D%29+%5Cequiv+%5Cmathbb+P%28X+%5Cleq+x%29%2C%5Cquad+F_Y%28y%29+%3A%3D+%5Cmathbb+P%28+Y+%5Cleq+y%29.&bg=ffffff&fg=000&s=0&c=20201002)
![\displaystyle F_X(x) = \int_{(-\infty, x]} f_X\, \mathrm d\mu,\quad F_Y(y) = \int_{(-\infty, y]} f_Y\, \mathrm d\mu.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F_X%28x%29+%3D+%5Cint_%7B%28-%5Cinfty%2C+x%5D%7D+f_X%5C%2C+%5Cmathrm+d%5Cmu%2C%5Cquad+F_Y%28y%29+%3D+%5Cint_%7B%28-%5Cinfty%2C+y%5D%7D+f_Y%5C%2C+%5Cmathrm+d%5Cmu.&bg=ffffff&fg=000&s=0&c=20201002)
 , by the Fubini-Tonelli theorem,
, by the Fubini-Tonelli theorem,![\begin{aligned} \mathbb P(X^{-1}((-\infty, x]) \cap Y^{-1}((-\infty, y])) &= \mathbb P((X,Y) \in (-\infty, x] \times (-\infty, y]) \\ &= \int_{(-\infty, x] \times (-\infty, y]} f_{X,Y}\, \mathrm d\mu^2 \\ &= \int_{(-\infty, x]} \int_{(-\infty, y]} f_{X,Y}\, \mathrm d \mu\, \mathrm d \mu \\ &= \int_{(-\infty, x]} \int_{(-\infty, y]} f_X \cdot f_Y\, \mathrm d \mu\, \mathrm d \mu \\ &= \int_{(-\infty, x]} f_X \, \mathrm d \mu \cdot \int_{(-\infty, y]} f_Y\, \mathrm d \mu \\ &= \mathbb P(X^{-1}(-\infty, x]) \cdot \mathbb P(Y^{-1}(-\infty, y]), \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+P%28X%5E%7B-1%7D%28%28-%5Cinfty%2C+x%5D%29+%5Ccap+Y%5E%7B-1%7D%28%28-%5Cinfty%2C+y%5D%29%29+%26%3D+%5Cmathbb+P%28%28X%2CY%29+%5Cin+%28-%5Cinfty%2C+x%5D+%5Ctimes+%28-%5Cinfty%2C+y%5D%29+%5C%5C+%26%3D+%5Cint_%7B%28-%5Cinfty%2C+x%5D+%5Ctimes+%28-%5Cinfty%2C+y%5D%7D+f_%7BX%2CY%7D%5C%2C+%5Cmathrm+d%5Cmu%5E2+%5C%5C+%26%3D+%5Cint_%7B%28-%5Cinfty%2C+x%5D%7D+%5Cint_%7B%28-%5Cinfty%2C+y%5D%7D+f_%7BX%2CY%7D%5C%2C+%5Cmathrm+d+%5Cmu%5C%2C+%5Cmathrm+d+%5Cmu+%5C%5C+%26%3D+%5Cint_%7B%28-%5Cinfty%2C+x%5D%7D+%5Cint_%7B%28-%5Cinfty%2C+y%5D%7D+f_X+%5Ccdot+f_Y%5C%2C+%5Cmathrm+d+%5Cmu%5C%2C+%5Cmathrm+d+%5Cmu+%5C%5C+%26%3D+%5Cint_%7B%28-%5Cinfty%2C+x%5D%7D+f_X+%5C%2C+%5Cmathrm+d+%5Cmu+%5Ccdot+%5Cint_%7B%28-%5Cinfty%2C+y%5D%7D+f_Y%5C%2C+%5Cmathrm+d+%5Cmu+%5C%5C+%26%3D+%5Cmathbb+P%28X%5E%7B-1%7D%28-%5Cinfty%2C+x%5D%29++%5Ccdot+%5Cmathbb+P%28Y%5E%7B-1%7D%28-%5Cinfty%2C+y%5D%29%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
 , we similarly use the Fubini-Tonelli theorem to obtain
, we similarly use the Fubini-Tonelli theorem to obtain![\begin{aligned} \iint_{(-\infty, x] \times (-\infty, y]} f_{X,Y}\, \mathrm d\mu^2 &= \int_{(-\infty, x]} f_X\, \mathrm d\mu \cdot \int_{(-\infty, y]} f_Y\, \mathrm d\mu \\ &= \int_{(-\infty, x]} \int_{(-\infty, y]} f_X \cdot f_Y\, \mathrm d \mu\, \mathrm d \mu \\ &= \iint_{(-\infty, x] \times (-\infty, y]} f_X \cdot f_Y\, \mathrm d\mu^2, \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Ciint_%7B%28-%5Cinfty%2C+x%5D+%5Ctimes+%28-%5Cinfty%2C+y%5D%7D+f_%7BX%2CY%7D%5C%2C+%5Cmathrm+d%5Cmu%5E2+%26%3D+%5Cint_%7B%28-%5Cinfty%2C+x%5D%7D+f_X%5C%2C+%5Cmathrm+d%5Cmu+%5Ccdot+%5Cint_%7B%28-%5Cinfty%2C+y%5D%7D+f_Y%5C%2C+%5Cmathrm+d%5Cmu+%5C%5C+%26%3D+%5Cint_%7B%28-%5Cinfty%2C+x%5D%7D+%5Cint_%7B%28-%5Cinfty%2C+y%5D%7D+f_X+%5Ccdot+f_Y%5C%2C+%5Cmathrm+d+%5Cmu%5C%2C+%5Cmathrm+d+%5Cmu+%5C%5C+%26%3D+%5Ciint_%7B%28-%5Cinfty%2C+x%5D+%5Ctimes+%28-%5Cinfty%2C+y%5D%7D+f_X+%5Ccdot+f_Y%5C%2C+%5Cmathrm+d%5Cmu%5E2%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
 .
. and
and  , we assume
, we assume  so that
so that 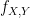 is a meaningful quantity.
is a meaningful quantity.![\displaystyle F_{X,Y}(x,y) = \mathbb P((X,Y) \in (-\infty, x] \times (-\infty, y]) \equiv \mathbb P(X \leq x, Y \leq y).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F_%7BX%2CY%7D%28x%2Cy%29+%3D+%5Cmathbb+P%28%28X%2CY%29+%5Cin+%28-%5Cinfty%2C+x%5D+%5Ctimes+%28-%5Cinfty%2C+y%5D%29++%5Cequiv+%5Cmathbb+P%28X+%5Cleq+x%2C+Y+%5Cleq+y%29.&bg=ffffff&fg=000&s=0&c=20201002)
 ,
,
 -valued random variables with density functions
-valued random variables with density functions  , then
, then 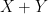 is a random variable with density function
is a random variable with density function



 so that for any fixed
so that for any fixed  ,
,  if and only if
if and only if  . For any
. For any 
 and
and  are independent, then
are independent, then  .
. and
and  . Then
. Then
 are independent. It suffices to prove that
are independent. It suffices to prove that
 , if
, if  , then
, then
 ,
,

 , in particular, with
, in particular, with
 , the integral then simplifies to
, the integral then simplifies to
 so that
so that  ,
,
 , as required.
, as required.
 for
for  , known in the statistics community as a
, known in the statistics community as a  -table. By symmetry,
-table. By symmetry,  . For any
. For any  , since
, since  , we can reduce the computation to
, we can reduce the computation to
 .
. ,
,
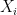 are not normally distributed,
are not normally distributed,  . For the limiting distribution to be constant, the equivalent claim is that
. For the limiting distribution to be constant, the equivalent claim is that  converges in distribution to
converges in distribution to  and aim to prove it properly using techniques in stochastic calculus. If we have this result, we are emboldened to carry out hypothesis tests, which are commonplace in the STEM fields as well as the data-driven social sciences. We will digress to this application before we dive right back into our ascent toward the central limit theorem.
and aim to prove it properly using techniques in stochastic calculus. If we have this result, we are emboldened to carry out hypothesis tests, which are commonplace in the STEM fields as well as the data-driven social sciences. We will digress to this application before we dive right back into our ascent toward the central limit theorem. as rigorously as possible.
as rigorously as possible. be a measure space (or a probability space if
be a measure space (or a probability space if  is equipped with the Borel
is equipped with the Borel  , generated by open balls under the Euclidean metric.
, generated by open balls under the Euclidean metric. be a random variable. Then
be a random variable. Then  defined by
defined by  is a random variable.
is a random variable.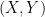 is continuous, and therefore, has open sets as pre-images of open sets. Therefore,
is continuous, and therefore, has open sets as pre-images of open sets. Therefore,  -measurable.
-measurable. ? Intuitively, we should have a measure
? Intuitively, we should have a measure 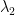 on
on  , where
, where  denotes the usual Lebesgue measure that we painstakingly constructed. In fact, more generally, given measure spaces
denotes the usual Lebesgue measure that we painstakingly constructed. In fact, more generally, given measure spaces  , we would like to define a reasonable
, we would like to define a reasonable  and a measure
and a measure 
 and
and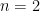 for simplicity. Define the algebra
for simplicity. Define the algebra
 and
and  , define the
, define the  by
by
 -section
-section  similarly. Now given
similarly. Now given  , for any
, for any 
 is well-defined. Similarly,
is well-defined. Similarly,  is well-defined for any
is well-defined for any  . Hence, define the function
. Hence, define the function  , which is non-negative and simple since in the special case
, which is non-negative and simple since in the special case  ,
,
 , and define
, and define
 is a disjoint union (the rest follows by careful bookkeeping),
is a disjoint union (the rest follows by careful bookkeeping),
 . We claim that
. We claim that  is countably additive. Fix
is countably additive. Fix  . Then for any
. Then for any 
 converges monotonically to
converges monotonically to  , and by the monotone convergence theorem,
, and by the monotone convergence theorem,
 and a measure
and a measure ![\mu : \mathcal F \to [0, \infty]](https://s0.wp.com/latex.php?latex=%5Cmu+%3A+%5Cmathcal+F+%5Cto+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) such that
such that  .
. and go on our merry way. But we still need to answer a key question: given the distributions
and go on our merry way. But we still need to answer a key question: given the distributions  and
and  , how do we compute
, how do we compute  ? In a more abstract manner, we need to integrate with respect to our newly minted measure
? In a more abstract manner, we need to integrate with respect to our newly minted measure  respectively. Surprisingly, answering this question leads us to one of the most important theorems in multivariable calculus, which is Fubini’s theorem, as it allows us to rigorously swap integrals—a key tool in any reasonable calculation.
respectively. Surprisingly, answering this question leads us to one of the most important theorems in multivariable calculus, which is Fubini’s theorem, as it allows us to rigorously swap integrals—a key tool in any reasonable calculation. and
and  , and their product space by
, and their product space by  . By construction,
. By construction,  . We remark that for any
. We remark that for any  and
and  ,
,  and
and  , since the
, since the 
 .
. and each
and each  has Lebesgue measure
has Lebesgue measure  with
with  such that
such that  . For instance,
. For instance,  are
are  by
by
 holds for any
holds for any  and
and  . It is straightforward that
. It is straightforward that  or even a disjoint union of sets in
or even a disjoint union of sets in  . If
. If  and
and  , then
, then  . Finally, if
. Finally, if  and
and  , then defining
, then defining  ,
,  is measurable, and by the monotone convergence theorem,
is measurable, and by the monotone convergence theorem,
 denote the smallest subset of
denote the smallest subset of  is a
is a  such that
such that  , and
, and  similarly. For each
similarly. For each  , define
, define  so that
so that ![f : \Omega_1 \times \Omega_2 \to [0, \infty]](https://s0.wp.com/latex.php?latex=f+%3A+%5COmega_1+%5Ctimes+%5COmega_2+%5Cto+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) , all of its sections
, all of its sections![f_x := f(x, \cdot) : \Omega_2 \to [0, \infty],\quad f^y := f( \cdot, y) : \Omega_1 \to [0, \infty]](https://s0.wp.com/latex.php?latex=f_x+%3A%3D+f%28x%2C+%5Ccdot%29+%3A+%5COmega_2+%5Cto+%5B0%2C+%5Cinfty%5D%2C%5Cquad+f%5Ey+%3A%3D+f%28+%5Ccdot%2C+y%29+%3A+%5COmega_1+%5Cto+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002)
![f_x^{-1}([a, \infty]) = (f^{-1}([a, \infty]))_x \in \mathcal F_2](https://s0.wp.com/latex.php?latex=f_x%5E%7B-1%7D%28%5Ba%2C+%5Cinfty%5D%29+%3D+%28f%5E%7B-1%7D%28%5Ba%2C+%5Cinfty%5D%29%29_x+%5Cin+%5Cmathcal+F_2&bg=ffffff&fg=000&s=0&c=20201002) .
.![f : \Omega \to [-\infty, \infty]](https://s0.wp.com/latex.php?latex=f+%3A+%5COmega+%5Cto+%5B-%5Cinfty%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) is integrable if
is integrable if  has measure zero and
has measure zero and  is integrable.
is integrable.![f:\Omega_1 \times \Omega_2 \to [-\infty, \infty]](https://s0.wp.com/latex.php?latex=f%3A%5COmega_1+%5Ctimes+%5COmega_2+%5Cto+%5B-%5Cinfty%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) is either non-negative and measurable (resp. integrable), then the functions
is either non-negative and measurable (resp. integrable), then the functions 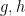 defined by
defined by

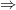 non-negative measurable
non-negative measurable  , then we obtain this result by Lemma 2. The result extends by linearity to non-negative simple functions.
, then we obtain this result by Lemma 2. The result extends by linearity to non-negative simple functions. that monotonically converge to
that monotonically converge to 
 by setting for each
by setting for each  . Then
. Then  . By the monotone convergence theorem again, since
. By the monotone convergence theorem again, since 
 and perform needful bookkeeping.
and perform needful bookkeeping. denote the density function for any sufficiently nice random variable
denote the density function for any sufficiently nice random variable 
 in the sense that for any Borel-measurable
in the sense that for any Borel-measurable  ,
,
 be a measurable space. If
be a measurable space. If  are
are  , then there exists a measurable function
, then there exists a measurable function ![f : \Omega \to [0, \infty]](https://s0.wp.com/latex.php?latex=f+%3A+%5COmega+%5Cto+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) such that
such that
 .
. , where
, where 
 (excluding infinities) is called a signed measure if
(excluding infinities) is called a signed measure if  and
and  such that
such that![\displaystyle \mu( \cdot \cap P) \in [0,\infty),\quad \mu( \cdot \cap N) \in (-\infty, 0],\quad P \sqcup N = \Omega.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmu%28+%5Ccdot+%5Ccap+P%29+%5Cin+%5B0%2C%5Cinfty%29%2C%5Cquad+%5Cmu%28+%5Ccdot+%5Ccap+N%29+%5Cin+%28-%5Cinfty%2C+0%5D%2C%5Cquad+P+%5Csqcup+N+%3D+%5COmega.&bg=ffffff&fg=000&s=0&c=20201002)
 a positive set, denoted
a positive set, denoted  , and
, and  a negative set, denoted
a negative set, denoted  . A set
. A set  .
. . If not, then for any
. If not, then for any  , there exists
, there exists  with
with  such that
such that  . Then
. Then  has measure
has measure  for any
for any  , a contradiction.
, a contradiction. such that
such that  . It follows by bookkeeping that
. It follows by bookkeeping that  is positive. We claim that
is positive. We claim that  is negative.
is negative. such that
such that  . Assume
. Assume  so that
so that  . If
. If  , thus
, thus  , a contradiction. Therefore, there exists
, a contradiction. Therefore, there exists  such that
such that  . Furthermore,
. Furthermore,  .
. , which exists by the Archimedean property of
, which exists by the Archimedean property of  , we obtain
, we obtain  such that
such that  and
and  , where
, where 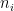 is the smallest possible positive integer. Define
is the smallest possible positive integer. Define  , which has positive finite measure. Since
, which has positive finite measure. Since 
 as
as  .
. , then
, then  , yielding the desired contradiction. To that end, suppose for a contradiction that there exists
, yielding the desired contradiction. To that end, suppose for a contradiction that there exists  such that
such that  . Then
. Then  for some
for some 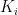 , as required.
, as required. , define the signed measure
, define the signed measure  . By the Hahn decomposition theorem, there exist disjoint positive and negative sets
. By the Hahn decomposition theorem, there exist disjoint positive and negative sets  with respect to
with respect to  such that
such that  .
. implies
implies  , for any
, for any  is decreasing in
is decreasing in  . Define the set
. Define the set  , which is positive with respect to all
, which is positive with respect to all 
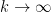 , we obtain
, we obtain  for any
for any 
 ,
,
 , so that
, so that

 ,
,
 ,
,
 is monotonically non-decreasing in
is monotonically non-decreasing in  by the monotone convergence theorem, and
by the monotone convergence theorem, and
 , so we set
, so we set  , as required.
, as required. with each
with each  . For each
. For each  such that
such that
 . Then for any
. Then for any  ,
,

 so that by the Radon-Nikodým theorem, there exists a density function
so that by the Radon-Nikodým theorem, there exists a density function  .
.![f|_{[a, b]}](https://s0.wp.com/latex.php?latex=f%7C_%7B%5Ba%2C+b%5D%7D&bg=ffffff&fg=000&s=0&c=20201002) is Riemann-integrable, then
is Riemann-integrable, then ![\displaystyle \int_{[a, b]} f\, \mathrm d\lambda = \int_a^b f \equiv \int_a^b f(x)\, \mathrm dx](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cint_%7B%5Ba%2C+b%5D%7D+f%5C%2C+%5Cmathrm+d%5Clambda+%3D+%5Cint_a%5Eb+f+%5Cequiv+%5Cint_a%5Eb+f%28x%29%5C%2C+%5Cmathrm+dx&bg=ffffff&fg=000&s=0&c=20201002)
 for simplicity. We first note that all step functions
for simplicity. We first note that all step functions  are simple functions. By the definition of the lower integral
are simple functions. By the definition of the lower integral  and upper integral
and upper integral  ,
,![\begin{aligned} \mathcal L_a^b(f) &= \sup_P \sum_{i=1}^n m_i(f, P) \Delta x_i \\ &= \sup_P \int_{[a,b]} m_i(f, P) \cdot \mathbb I_{[x_{i-1},x_i)} \\ &\leq \sup_{\substack{\varphi\ \text{simple} \\ 0 \leq \varphi \leq f \cdot \mathbb I_{[a, b]}} } \int_{\mathbb R} \varphi \, \mathrm d\lambda \\ &\leq \inf_P \sum_{i=1}^n M_i(f, P) \Delta x_i \leq \mathcal R_a^b(f). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathcal+L_a%5Eb%28f%29+%26%3D+%5Csup_P+%5Csum_%7Bi%3D1%7D%5En+m_i%28f%2C+P%29+%5CDelta+x_i+%5C%5C+%26%3D+%5Csup_P+%5Cint_%7B%5Ba%2Cb%5D%7D+m_i%28f%2C+P%29+%5Ccdot+%5Cmathbb+I_%7B%5Bx_%7Bi-1%7D%2Cx_i%29%7D+%5C%5C+%26%5Cleq+%5Csup_%7B%5Csubstack%7B%5Cvarphi%5C+%5Ctext%7Bsimple%7D+%5C%5C+0+%5Cleq+%5Cvarphi+%5Cleq+f+%5Ccdot+%5Cmathbb+I_%7B%5Ba%2C+b%5D%7D%7D+%7D+%5Cint_%7B%5Cmathbb+R%7D+%5Cvarphi+%5C%2C+%5Cmathrm+d%5Clambda+%5C%5C+%26%5Cleq+%5Cinf_P+%5Csum_%7Bi%3D1%7D%5En+M_i%28f%2C+P%29+%5CDelta+x_i+%5Cleq+%5Cmathcal+R_a%5Eb%28f%29.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
 , so that
, so that![\displaystyle \int_a^b f\, \mathrm d\lambda = \int_{\mathbb R} f \cdot \mathbb I_{[a, b]}\, \mathrm d\lambda = \sup_{\substack{\varphi\ \text{simple} \\ 0 \leq \varphi \leq f \cdot \mathbb I_{[a, b]}} } \int_{\mathbb R} \varphi \, \mathrm d\lambda = \int_a^b f.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cint_a%5Eb+f%5C%2C+%5Cmathrm+d%5Clambda+%3D+%5Cint_%7B%5Cmathbb+R%7D+f+%5Ccdot+%5Cmathbb+I_%7B%5Ba%2C+b%5D%7D%5C%2C+%5Cmathrm+d%5Clambda+%3D+%5Csup_%7B%5Csubstack%7B%5Cvarphi%5C+%5Ctext%7Bsimple%7D+%5C%5C+0+%5Cleq+%5Cvarphi+%5Cleq+f+%5Ccdot+%5Cmathbb+I_%7B%5Ba%2C+b%5D%7D%7D+%7D+%5Cint_%7B%5Cmathbb+R%7D+%5Cvarphi+%5C%2C+%5Cmathrm+d%5Clambda+%3D+%5Cint_a%5Eb+f.&bg=ffffff&fg=000&s=0&c=20201002)
![-m := \inf_{x \in [a, b]} f(x) < 0](https://s0.wp.com/latex.php?latex=-m+%3A%3D+%5Cinf_%7Bx+%5Cin+%5Ba%2C+b%5D%7D+f%28x%29+%3C+0&bg=ffffff&fg=000&s=0&c=20201002) . Now
. Now ![(f + m)|_{[a,b]}](https://s0.wp.com/latex.php?latex=%28f+%2B+m%29%7C_%7B%5Ba%2Cb%5D%7D&bg=ffffff&fg=000&s=0&c=20201002) is bounded, measurable, and Riemann-integrable. Since it is nonnegative, by the first result, it is Lebesgue-integrable. Therefore,
is bounded, measurable, and Riemann-integrable. Since it is nonnegative, by the first result, it is Lebesgue-integrable. Therefore,  when restricted to
when restricted to ![\begin{aligned} \int_{[a, b]} f\, \mathrm d\lambda &= \int_{[a, b]} ((f + m) - m)\, \mathrm d\lambda \\ &= \int_{[a, b]} (f + m)\, \mathrm d\lambda - \int_{[a, b]} m\, \mathrm d\lambda\\ &= \int_a^b f + \int_a^b m -\int_a^b m = \int_a^b f.\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cint_%7B%5Ba%2C+b%5D%7D+f%5C%2C+%5Cmathrm+d%5Clambda+%26%3D+%5Cint_%7B%5Ba%2C+b%5D%7D+%28%28f+%2B+m%29+-+m%29%5C%2C+%5Cmathrm+d%5Clambda+%5C%5C+%26%3D+%5Cint_%7B%5Ba%2C+b%5D%7D+%28f+%2B+m%29%5C%2C+%5Cmathrm+d%5Clambda+-++%5Cint_%7B%5Ba%2C+b%5D%7D+m%5C%2C+%5Cmathrm+d%5Clambda%5C%5C+%26%3D+%5Cint_a%5Eb+f+%2B+%5Cint_a%5Eb+m+-%5Cint_a%5Eb+m++%3D+%5Cint_a%5Eb+f.%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\nu : \mathcal F \to [0, \infty]](https://s0.wp.com/latex.php?latex=%5Cnu+%3A+%5Cmathcal+F+%5Cto+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) defined by
defined by
 implies that
implies that  .
.
 . Define
. Define  . The sequence
. The sequence  of measurable functions monotonically increases to the measurable function
of measurable functions monotonically increases to the measurable function  . By the monotone convergence theorem,
. By the monotone convergence theorem,
 is countably additive. Finally, suppose
is countably additive. Finally, suppose  . Fix any simple function
. Fix any simple function  ,
,  , where
, where  . By the monotonicity of
. By the monotonicity of  . Hence,
. Hence,

 be a non-negative measurable function. Then
be a non-negative measurable function. Then  if and only if there exists some
if and only if there exists some  such that
such that  . In this case, we say that
. In this case, we say that 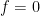


 . Then
. Then
 be integrable functions. Then
be integrable functions. Then  for any
for any  with
with  such that
such that  . In this case, we say that
. In this case, we say that 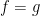
 . For the direction
. For the direction 
 and
and  . Then
. Then  are nonnegative functions and by Lemma 2,
are nonnegative functions and by Lemma 2,
 with
with  such that
such that  . Similarly,
. Similarly, 
 with
with  such that
such that 

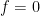
 of simple functions
of simple functions ![f_n : \Omega \to [0, \infty]](https://s0.wp.com/latex.php?latex=f_n+%3A+%5COmega+%5Cto+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) such that
such that  monotonically.
monotonically. , define for
, define for 

 . Define the non-negative simple functions
. Define the non-negative simple functions 
 for illustration:
for illustration:
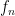 is made up of
is made up of  pieces. By performing necessary real-analysis calculations, it’s not hard to verify that
pieces. By performing necessary real-analysis calculations, it’s not hard to verify that  be a measurable space, and
be a measurable space, and  be a measurable function that induces the pushforward measure
be a measurable function that induces the pushforward measure  on
on  . Then for any integrable
. Then for any integrable  ,
,
![g : \Psi \to [0, \infty]](https://s0.wp.com/latex.php?latex=g+%3A+%5CPsi+%5Cto+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) . Firstly, suppose
. Firstly, suppose  is a simple function. We observe that
is a simple function. We observe that
 , so that
, so that
 of non-negative simple functions
of non-negative simple functions  that monotonically converge to
that monotonically converge to  monotonically as well. By the monotone convergence theorem,
monotonically as well. By the monotone convergence theorem,
 . Applying relevant linearity properties,
. Applying relevant linearity properties,
 denote either of the measure spaces
denote either of the measure spaces  or
or  .
. be a measurable map. Suppose there exists a non-negative integrable function
be a measurable map. Suppose there exists a non-negative integrable function  such that its distribution
such that its distribution 
 , then we call
, then we call  and for any
and for any  ,
,
 , then we call
, then we call  ,
,![\displaystyle \mathbb P_X([a, b]) = \int_a^b f_X \equiv \int_a^b f_X(x)\, \mathrm dx.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+P_X%28%5Ba%2C+b%5D%29+%3D+%5Cint_a%5Eb+f_X+%5Cequiv+%5Cint_a%5Eb+f_X%28x%29%5C%2C+%5Cmathrm+dx.&bg=ffffff&fg=000&s=0&c=20201002)
 is said to be continuous if there exists a non-negative integrable function
is said to be continuous if there exists a non-negative integrable function  such that its distribution
such that its distribution ![\displaystyle \mathbb P_X(K) = \int_K f_X\, \mathrm d \lambda,\quad K \in \mathcal F \quad \Rightarrow \quad \mathbb P_X([a, b]) = \int_a^b f_X.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+P_X%28K%29+%3D+%5Cint_K+f_X%5C%2C+%5Cmathrm+d+%5Clambda%2C%5Cquad+K+%5Cin+%5Cmathcal+F+%5Cquad+%5CRightarrow+%5Cquad+%5Cmathbb+P_X%28%5Ba%2C+b%5D%29+%3D+%5Cint_a%5Eb+f_X.&bg=ffffff&fg=000&s=0&c=20201002)
![F_X(x) := \mathbb P_X((-\infty, x])](https://s0.wp.com/latex.php?latex=F_X%28x%29+%3A%3D+%5Cmathbb+P_X%28%28-%5Cinfty%2C+x%5D%29&bg=ffffff&fg=000&s=0&c=20201002) .
. is a probability measure. Then for any continuous random variable
is a probability measure. Then for any continuous random variable ![\displaystyle \mathbb E[g(X)] = \int_{\Omega} g \circ X\, \mathrm d \mathbb P = \int_{\Psi} g\, \mathrm d \mathbb P_X = \int_{\Psi} g \cdot f_X\, \mathrm d\nu.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5Bg%28X%29%5D+%3D+%5Cint_%7B%5COmega%7D+g+%5Ccirc+X%5C%2C+%5Cmathrm+d+%5Cmathbb+P+%3D+%5Cint_%7B%5CPsi%7D+g%5C%2C+%5Cmathrm+d+%5Cmathbb+P_X+%3D+%5Cint_%7B%5CPsi%7D+g+%5Ccdot+f_X%5C%2C+%5Cmathrm+d%5Cnu.&bg=ffffff&fg=000&s=0&c=20201002)

![g = \sum_{i=1}^n a_i \cdot \mathbb I_{K_i} : \Psi \to [0, \infty]](https://s0.wp.com/latex.php?latex=g+%3D+%5Csum_%7Bi%3D1%7D%5En+a_i+%5Ccdot+%5Cmathbb+I_%7BK_i%7D+%3A+%5CPsi+%5Cto+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) is simple, and the rest follows by the monotone convergence theorem (for non-negative
is simple, and the rest follows by the monotone convergence theorem (for non-negative 
![\mathbb E[g(X)] = \sum_{x \in \mathbb Z} g(x) f_X(x)](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5Bg%28X%29%5D+%3D+%5Csum_%7Bx+%5Cin+%5Cmathbb+Z%7D+g%28x%29+f_X%28x%29&bg=ffffff&fg=000&s=0&c=20201002) ,
,![\mathbb E[g(X)] = \int_{-\infty}^{\infty} g(x) f_X(x)\, \mathrm dx](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5Bg%28X%29%5D+%3D+%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D+g%28x%29+f_X%28x%29%5C%2C+%5Cmathrm+dx&bg=ffffff&fg=000&s=0&c=20201002) .
. or even more specifically
or even more specifically 
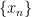 be a non-decreasing sequence of real numbers that is bounded above. Then
be a non-decreasing sequence of real numbers that is bounded above. Then  .
.![f, g : \Omega \to [0, \infty]](https://s0.wp.com/latex.php?latex=f%2C+g+%3A+%5COmega+%5Cto+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) , if
, if  , then
, then
 such that
such that
 yields the desired result.
yields the desired result.
 whenever
whenever 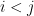 ), then
), then 
![a \in [0, \infty]](https://s0.wp.com/latex.php?latex=a+%5Cin+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) , we have
, we have ![[a, \infty] \in \frak{B}([0,\infty])](https://s0.wp.com/latex.php?latex=%5Ba%2C+%5Cinfty%5D+%5Cin+%5Cfrak%7BB%7D%28%5B0%2C%5Cinfty%5D%29&bg=ffffff&fg=000&s=0&c=20201002) . Since each
. Since each ![f_n^{-1}([a, \infty]) \in \mathcal F](https://s0.wp.com/latex.php?latex=f_n%5E%7B-1%7D%28%5Ba%2C+%5Cinfty%5D%29+%5Cin+%5Cmathcal+F&bg=ffffff&fg=000&s=0&c=20201002) . Therefore,
. Therefore,![\displaystyle f^{-1}([a, \infty]) = \bigcap_{n = 1}^\infty f_n^{-1}([a, \infty]) \in \mathcal F.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f%5E%7B-1%7D%28%5Ba%2C+%5Cinfty%5D%29+%3D+%5Cbigcap_%7Bn+%3D+1%7D%5E%5Cinfty+f_n%5E%7B-1%7D%28%5Ba%2C+%5Cinfty%5D%29+%5Cin+%5Cmathcal+F.&bg=ffffff&fg=000&s=0&c=20201002)
 ,
,  by Lemma 1. By Lemma 2,
by Lemma 1. By Lemma 2,

 . We claim that the right hand side equals
. We claim that the right hand side equals  . Fix
. Fix  . By definition, there exists a simple function
. By definition, there exists a simple function  , such that
, such that 
 . so that
. so that  for each
for each  . There are two cases:
. There are two cases:  or
or 
 and
and  . By continuity of measures,
. By continuity of measures,  . Hence, there exists
. Hence, there exists  such that
such that  . Therefore,
. Therefore,
 ,
,

 . That way,
. That way,  , as required.
, as required. without loss of generality. Define
without loss of generality. Define
 . Thus, there exists
. Thus, there exists  such that
such that  . Hence,
. Hence,
 , as required.
, as required. . Fix
. Fix 

 to be tuned. Define
to be tuned. Define
 and
and  . Hence for any
. Hence for any  , there exists
, there exists  such that
such that  . Hence,
. Hence,
 and
and  to obtain the inequality
to obtain the inequality
 , as required.
, as required.


![\displaystyle f^{-1}([a, \infty]) = \bigcup_{n = 1}^\infty \left( \bigcap_{k=n}^\infty f_k^{-1}([0, \infty]) \right).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+f%5E%7B-1%7D%28%5Ba%2C+%5Cinfty%5D%29+%3D+%5Cbigcup_%7Bn+%3D+1%7D%5E%5Cinfty+%5Cleft%28+%5Cbigcap_%7Bk%3Dn%7D%5E%5Cinfty+f_k%5E%7B-1%7D%28%5B0%2C+%5Cinfty%5D%29+%5Cright%29.&bg=ffffff&fg=000&s=0&c=20201002)
 , which is measurable. By construction,
, which is measurable. By construction,  is monotonically increasing and
is monotonically increasing and  . By the monotone convergence theorem,
. By the monotone convergence theorem,

 yields
yields  satisfying the following properties:
satisfying the following properties: such that
such that  .
. are integrable, and
are integrable, and , which implies that
, which implies that 

 , since
, since  is integrable,
is integrable,

 and
and  and
and  respectively since
respectively since  and
and  . Combine the integrals to yield the desired result.
. Combine the integrals to yield the desired result. whether or not their claim holds weight; that is, whether the exam was harder, and thus, the population mean score
whether or not their claim holds weight; that is, whether the exam was harder, and thus, the population mean score  is called the null hypothesis, denoted
is called the null hypothesis, denoted  , and the proposed change
, and the proposed change  is called the alternative hypothesis, denoted
is called the alternative hypothesis, denoted  . Usually, we abbreviate as follows
. Usually, we abbreviate as follows
 approximately by the central limit theorem.
approximately by the central limit theorem. , and we can compute
, and we can compute
 is an unbiased estimator for
is an unbiased estimator for 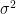 ? We use the unbiased estimator
? We use the unbiased estimator  , where
, where
 ?
? such that
such that
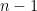 degrees of freedom. We slowly formalise it as follows.
degrees of freedom. We slowly formalise it as follows. , where
, where 
 denotes the gamma function. Recall that
denotes the gamma function. Recall that  .
. . Therefore, we restrict our attention to
. Therefore, we restrict our attention to  . Then
. Then

 ,
,

 reduces the left-hand side reduces to
reduces the left-hand side reduces to
 , so that applying this result to the definition of the gamma function defined by
, so that applying this result to the definition of the gamma function defined by

 ,
,

 is said to follow a chi-squared distribution with
is said to follow a chi-squared distribution with  degrees of freedom, denoted
degrees of freedom, denoted  , if its density function is given by
, if its density function is given by
 and
and  are independent, then
are independent, then  .
. ,
,  , taking convolutions and applying Lemma 2,
, taking convolutions and applying Lemma 2,
 if and only if there exist i.i.d.
if and only if there exist i.i.d.  such that
such that  .
. .
. be i.i.d. with mean
be i.i.d. with mean 

 can only be expressed in terms of
can only be expressed in terms of 
 defined below?
defined below?

 is said to follow a Student’s
is said to follow a Student’s  , if there exist independent
, if there exist independent 
 . As such, we recover the classic
. As such, we recover the classic  given by
given by
 . Denote
. Denote  . By Fubini’s theorem,
. By Fubini’s theorem,


 , so that by the substitution
, so that by the substitution  ,
,

 given by the expressions
given by the expressions
 and
and  , we obtain a
, we obtain a 
 inches towards our suspicions of marks having decreased being correct. Since
inches towards our suspicions of marks having decreased being correct. Since  -value
-value  .
.

 or
or 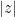 is away from
is away from  , then there is no way that we can reject
, then there is no way that we can reject  for some predetermined
for some predetermined 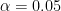 (or in physicists’ case,
(or in physicists’ case,  , known as the 5-sigma-rule), there is a chance of rejecting
, known as the 5-sigma-rule), there is a chance of rejecting  vs.
vs.  ,
, ,
, .
.![\lambda([a, b]) = b-a](https://s0.wp.com/latex.php?latex=%5Clambda%28%5Ba%2C+b%5D%29+%3D+b-a&bg=ffffff&fg=000&s=0&c=20201002) ). Just like constructing the real numbers, we constructed this measure formally for purely logical consistency reasons—the fun starts when we use these constructions to solve problems.
). Just like constructing the real numbers, we constructed this measure formally for purely logical consistency reasons—the fun starts when we use these constructions to solve problems.
 , so that
, so that
 -measurable if
-measurable if  for any
for any  , and omit the prefix when there is no ambiguity.
, and omit the prefix when there is no ambiguity. , where
, where  refers to the Borel
refers to the Borel ![[-\infty, \infty]](https://s0.wp.com/latex.php?latex=%5B-%5Cinfty%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) with the Borel
with the Borel ![\frak{B}([-\infty, \infty])](https://s0.wp.com/latex.php?latex=%5Cfrak%7BB%7D%28%5B-%5Cinfty%2C+%5Cinfty%5D%29&bg=ffffff&fg=000&s=0&c=20201002) . Henceforth, let
. Henceforth, let  is measurable if and only if
is measurable if and only if 
 using these indicator functions by linear extensions, and we will do so slowly.
using these indicator functions by linear extensions, and we will do so slowly. is a finite set. Denote
is a finite set. Denote  , so that
, so that

![f , g: \Omega \to [-\infty, \infty]](https://s0.wp.com/latex.php?latex=f+%2C+g%3A+%5COmega+%5Cto+%5B-%5Cinfty%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) be simple functions. Then
be simple functions. Then  is simple, and for any
is simple, and for any  ,
,  is also simple. Furthermore, if
is also simple. Furthermore, if 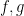 are non-negative, so is
are non-negative, so is  . In these cases,
. In these cases,

 , we observe that
, we observe that
 . Hence,
. Hence,
 is finite,
is finite, 
 , so that
, so that

 is a simple function that satisfies the inequality
is a simple function that satisfies the inequality 
![f+g : \Omega \to [0, \infty]](https://s0.wp.com/latex.php?latex=f%2Bg+%3A+%5COmega+%5Cto+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) is measurable, and
is measurable, and
![\alpha \in [0, \infty]](https://s0.wp.com/latex.php?latex=%5Calpha+%5Cin+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) ,
, ![\alpha f : \Omega \to [0, \infty]](https://s0.wp.com/latex.php?latex=%5Calpha+f+%3A+%5COmega+%5Cto+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) is measurable and
is measurable and
![\varphi : \Omega \to [0, \infty]](https://s0.wp.com/latex.php?latex=%5Cvarphi+%3A+%5COmega+%5Cto+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) such that
such that  and
and
![\psi : \Omega \to [0, \infty]](https://s0.wp.com/latex.php?latex=%5Cpsi+%3A+%5COmega+%5Cto+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) such that
such that  and
and 
![\varphi + \psi : \Omega \to [0,\infty]](https://s0.wp.com/latex.php?latex=%5Cvarphi+%2B+%5Cpsi+%3A+%5COmega+%5Cto+%5B0%2C%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) is a simple function,
is a simple function,
 ,
,

 , if
, if  , then
, then
 , so that Lemma 3 yields
, so that Lemma 3 yields

 and
and  are finite, and define its integral by their difference:
are finite, and define its integral by their difference:


 for additivity. The idea is to find a useful disjoint union
for additivity. The idea is to find a useful disjoint union  , so that
, so that
 and
and  . Define
. Define  . Similarly define
. Similarly define  . By observation,
. By observation,
 ,
,  if and only if
if and only if
 and
and  similarly. Then
similarly. Then
 are non-negative and hence
are non-negative and hence

 . Since
. Since  , the result follows.
, the result follows. be a probability measure on
be a probability measure on ![\displaystyle \mathbb E[X] := \int_{\Omega} X\, \mathrm d\mathbb P,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5BX%5D+%3A%3D+%5Cint_%7B%5COmega%7D+X%5C%2C+%5Cmathrm+d%5Cmathbb+P%2C&bg=ffffff&fg=000&s=0&c=20201002)
![\begin{aligned} \mathbb E[X+Y] &= \int_{\Omega} (X+Y)\, \mathrm d\mathbb P \\ &= \int_{\Omega} X\, \mathrm d\mathbb P + \int_{\Omega} Y\, \mathrm d\mathbb P \\ &= \mathbb E[X] + \mathbb E[Y]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BX%2BY%5D+%26%3D+%5Cint_%7B%5COmega%7D+%28X%2BY%29%5C%2C+%5Cmathrm+d%5Cmathbb+P+%5C%5C+%26%3D+%5Cint_%7B%5COmega%7D+X%5C%2C+%5Cmathrm+d%5Cmathbb+P+%2B+%5Cint_%7B%5COmega%7D+Y%5C%2C+%5Cmathrm+d%5Cmathbb+P+%5C%5C+%26%3D+%5Cmathbb+E%5BX%5D+%2B+%5Cmathbb+E%5BY%5D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
 is finite, then we have already proven this result. But we need to think bigger, and explore the three crucial convergence theorems in measure theory.
is finite, then we have already proven this result. But we need to think bigger, and explore the three crucial convergence theorems in measure theory. . That bit is trivial. But can we assign lengths to meaningful subsets
. That bit is trivial. But can we assign lengths to meaningful subsets  in general? This endeavour requires a lot more effort.
in general? This endeavour requires a lot more effort.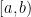 and
and  . Then
. Then  ,
,  . If we can prove that
. If we can prove that 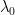 is countably additive, then we can take advantage of the Carathéodory extension theorem to extend it to a proper measure
is countably additive, then we can take advantage of the Carathéodory extension theorem to extend it to a proper measure  . We shall ensure this is the case in Lemma 2.
. We shall ensure this is the case in Lemma 2.![\lambda_0 : \mathcal F^0 \to [0, \infty]](https://s0.wp.com/latex.php?latex=%5Clambda_0+%3A+%5Cmathcal+F%5E0+%5Cto+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) by
by
 ,
,
 . By monotonicity,
. By monotonicity,


 , then we are done. Suppose
, then we are done. Suppose  . Under the assumption that
. Under the assumption that  ,
,  then, so that
then, so that
 forms an open cover for the compact space
forms an open cover for the compact space  . Hence,
. Hence, 

 on
on ![\lambda : \mathcal F \to [0, \infty]](https://s0.wp.com/latex.php?latex=%5Clambda+%3A+%5Cmathcal+F+%5Cto+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) , called the Lebesgue measure, such that
, called the Lebesgue measure, such that  . In particular,
. In particular,  .
.
 by the above argument, we have
by the above argument, we have  .
. ,
,![\lambda((a, b)) = \lambda((a, b]) = \lambda([a, b]) = \lambda([a, b))](https://s0.wp.com/latex.php?latex=%5Clambda%28%28a%2C+b%29%29+%3D+%5Clambda%28%28a%2C+b%5D%29+%3D+%5Clambda%28%5Ba%2C+b%5D%29+%3D+%5Clambda%28%5Ba%2C+b%29%29&bg=ffffff&fg=000&s=0&c=20201002) ,
, ,
, .
. . Therefore,
. Therefore,  . Taking
. Taking  .
.
 denote a bijection (since the latter is countable), and denote
denote a bijection (since the latter is countable), and denote  . Fix
. Fix  . Therefore, by countable additivity,
. Therefore, by countable additivity,
 .
.![\mathbb R \supseteq [0, n]](https://s0.wp.com/latex.php?latex=%5Cmathbb+R+%5Csupseteq+%5B0%2C+n%5D&bg=ffffff&fg=000&s=0&c=20201002) so that monotonicity yields
so that monotonicity yields![\lambda(\mathbb R) \geq \lambda([0, n]) = n.](https://s0.wp.com/latex.php?latex=%5Clambda%28%5Cmathbb+R%29+%5Cgeq+%5Clambda%28%5B0%2C+n%5D%29+%3D+n.&bg=ffffff&fg=000&s=0&c=20201002)
 , since we are interpreting
, since we are interpreting 
 . If
. If  and
and  .
. on
on  of
of 
 is a countable cover of
is a countable cover of  . Furthermore,
. Furthermore,

 . For the reverse inequality,
. For the reverse inequality,
 . It is not hard then to verify that
. It is not hard then to verify that 
 , called a Vitali set, such that
, called a Vitali set, such that  is undefined.
is undefined. on
on  if and only if
if and only if  . Then we obtain the quotient set
. Then we obtain the quotient set  whose take the form
whose take the form  . Furthermore, for each
. Furthermore, for each  ,
,  . By the axiom of choice, select
. By the axiom of choice, select  . Define the Vitali set by
. Define the Vitali set by
 and
and ![\lambda(V) \in [0, \infty]](https://s0.wp.com/latex.php?latex=%5Clambda%28V%29+%5Cin+%5B0%2C+%5Cinfty%5D&bg=ffffff&fg=000&s=0&c=20201002) . Let
. Let ![f : \mathbb N \to \mathbb Q \cap [-1, 1] =: \mathbb Q_{[-1,1]}](https://s0.wp.com/latex.php?latex=f+%3A+%5Cmathbb+N+%5Cto+%5Cmathbb+Q+%5Ccap+%5B-1%2C+1%5D+%3D%3A+%5Cmathbb+Q_%7B%5B-1%2C1%5D%7D&bg=ffffff&fg=000&s=0&c=20201002) be an enumeration of
be an enumeration of  defined by
defined by  (as per the countability of
(as per the countability of  , it is not hard to check that
, it is not hard to check that  is pairwise disjoint. Hence,
is pairwise disjoint. Hence,![\displaystyle \bigsqcup_{k \in \mathbb Q_{[-1,1]}} V_k \in \mathcal F.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbigsqcup_%7Bk+%5Cin+%5Cmathbb+Q_%7B%5B-1%2C1%5D%7D%7D+V_k+%5Cin+%5Cmathcal+F.&bg=ffffff&fg=000&s=0&c=20201002)
![\displaystyle [0, 1] \subseteq \bigsqcup_{k \in \mathbb Q_{[-1,1]}} V_k \subseteq [-1, 2].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B0%2C+1%5D+%5Csubseteq+%5Cbigsqcup_%7Bk+%5Cin+%5Cmathbb+Q_%7B%5B-1%2C1%5D%7D%7D+V_k+%5Csubseteq+%5B-1%2C+2%5D.&bg=ffffff&fg=000&s=0&c=20201002)
![\displaystyle 1 = \lambda([0, 1]) \leq \sum_{k \in \mathbb Q_{[-1,1]}} \lambda(V_k) \leq \lambda ([-1, 2]) = 3.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+1+%3D+%5Clambda%28%5B0%2C+1%5D%29+%5Cleq+%5Csum_%7Bk+%5Cin+%5Cmathbb+Q_%7B%5B-1%2C1%5D%7D%7D+%5Clambda%28V_k%29+%5Cleq+%5Clambda+%28%5B-1%2C+2%5D%29+%3D+3.&bg=ffffff&fg=000&s=0&c=20201002)
 by translational invariance,
by translational invariance,  . However,
. However,  , a contradiction.
, a contradiction.