In this appendix for the multi-armed bandit writeups, I thought I’d revisit my final year project in a relatively readable manner, demonstrating how 



As a set-up, we initialise 

since the conjugate prior of a Bernoulli distribution is the Beta distribution. For the update function, we use

and 



Observe that the map 
![\tilde{\rho} : [0, 1] \to \mathbb R](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D+%3A+%5B0%2C+1%5D+%5Cto+%5Cmathbb+R&bg=ffffff&fg=000&s=0&c=20201002)

Definition 1. Call a risk functional ![\tilde{\rho} : [0,1] \to \mathbb R](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D+%3A+%5B0%2C1%5D+%5Cto+%5Cmathbb+R&bg=ffffff&fg=000&s=0&c=20201002)
If ![\tilde{\rho}([0,1])](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D%28%5B0%2C1%5D%29&bg=ffffff&fg=000&s=0&c=20201002)
![p_1, p_2 \in [0,1]](https://s0.wp.com/latex.php?latex=p_1%2C+p_2+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)
![p \in [0, 1]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)

Lemma 1. If ![p \in [0,1]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)

![p_* \in [0, 1]](https://s0.wp.com/latex.php?latex=p_%2A+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)

Proof. By definition,

By a direct computation,

so that 
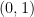
If 





Suppose 

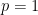


Suppose instead that 

![[r + \epsilon, \tilde{\rho}(p_2)]](https://s0.wp.com/latex.php?latex=%5Br+%2B+%5Cepsilon%2C+%5Ctilde%7B%5Crho%7D%28p_2%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\tilde{\rho}^{-1}( [r + \epsilon, \infty) ) = \tilde{\rho}^{-1}( [r+ \epsilon, \tilde{\rho}(p_2) ] )](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D%5E%7B-1%7D%28+%5Br+%2B+%5Cepsilon%2C+%5Cinfty%29+%29+%3D+%5Ctilde%7B%5Crho%7D%5E%7B-1%7D%28+%5Br%2B+%5Cepsilon%2C+%5Ctilde%7B%5Crho%7D%28p_2%29+%5D+%29&bg=ffffff&fg=000&s=0&c=20201002)
is closed and bounded, and thus compact by the Heine-Borel theorem. Since the sets
![\begin{aligned} C_1(\epsilon) &:= \tilde{\rho}^{-1}( [r+ \epsilon, \infty) ) \cap [0, p],\\ C_2 (\epsilon)&:= \tilde{\rho}^{-1}( [r+ \epsilon, \infty) ) \cap [p, 1], \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+C_1%28%5Cepsilon%29+%26%3A%3D+%5Ctilde%7B%5Crho%7D%5E%7B-1%7D%28+%5Br%2B+%5Cepsilon%2C+%5Cinfty%29+%29+%5Ccap+%5B0%2C+p%5D%2C%5C%5C+C_2+%28%5Cepsilon%29%26%3A%3D+%5Ctilde%7B%5Crho%7D%5E%7B-1%7D%28+%5Br%2B+%5Cepsilon%2C+%5Cinfty%29+%29+%5Ccap+%5Bp%2C+1%5D%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
are also compact, we can define their extrema

At least one of these sets will always be non-empty, since ![r_2 \in [0, 1]](https://s0.wp.com/latex.php?latex=r_2+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)






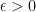
Using monotonicity properties, 


Now it is clear that 

![q_j \in [0,1]](https://s0.wp.com/latex.php?latex=q_j+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)


Define 


Taking 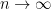

Finally, choose

to deduce that

Remark 1. Most arguments in Lemma 1 boils down to the compactness of ![[a, b]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%5D&bg=ffffff&fg=000&s=0&c=20201002)

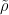

- Generalise the risk functional to
, where
is a space of probability distributions that is compact under a suitable metric or topology.
- We would probably need to partition
into
.
- During the sequential argument, we could use sequential compactness to concoct a convergent subsequence
in place of a by-default convergent subsequence. That way, we might still be able to infimise over
via
.
- Since we only care about infimising, we do not need the strength of full continuity for
; rather we would only require its lower semi-continuity property, which could be conceived as the “lower half” of vanilla continuity.
Thanks to the continuity of
Theorem 1. Fix 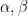

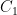


Proof. Denote the closed (and thus, compact) sets 
![S_2 := \tilde{\rho}^{-1}((-\infty, r])](https://s0.wp.com/latex.php?latex=S_2+%3A%3D+%5Ctilde%7B%5Crho%7D%5E%7B-1%7D%28%28-%5Cinfty%2C+r%5D%29&bg=ffffff&fg=000&s=0&c=20201002)

for brevity. Using the conjugate-prior connection between Beta distributions and Bernoulli distributions, since the sum of i.i.d. Bernoullis yield a Binomial,

where 



![\begin{aligned} f_{X|Y}(x \mid y) &= \frac{ f_{Y\mid X}(y \mid x) \cdot f_X(x) }{ f_Y(y) } \\ &= \frac{ f_{Y\mid X}(y \mid x) \cdot f_X(x) }{ \int_{[0,1]} f_{Y \mid X}(y \mid x) \cdot f_X(x) \, \mathrm dx} \\ &= \frac{ {n \choose y} \cdot x^{y} (1-x)^{n-y} \cdot 1 }{ \int_{[0,1]} {n \choose y} \cdot x^{y} (1-x)^{n-y} \cdot 1 \, \mathrm dx} \\ &= \frac{ x^{y} (1-x)^{n-y} }{ \int_{[0,1]} x^{y} (1-x)^{n-y} \, \mathrm dx}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+f_%7BX%7CY%7D%28x+%5Cmid+y%29+%26%3D+%5Cfrac%7B+f_%7BY%5Cmid+X%7D%28y+%5Cmid+x%29+%5Ccdot+f_X%28x%29+%7D%7B+f_Y%28y%29+%7D+%5C%5C+%26%3D+%5Cfrac%7B+f_%7BY%5Cmid+X%7D%28y+%5Cmid+x%29+%5Ccdot+f_X%28x%29+%7D%7B+%5Cint_%7B%5B0%2C1%5D%7D++f_%7BY+%5Cmid+X%7D%28y+%5Cmid+x%29+%5Ccdot+f_X%28x%29+%5C%2C+%5Cmathrm+dx%7D+%5C%5C+%26%3D+%5Cfrac%7B+%7Bn+%5Cchoose+y%7D+%5Ccdot+x%5E%7By%7D+%281-x%29%5E%7Bn-y%7D+%5Ccdot+1+%7D%7B+%5Cint_%7B%5B0%2C1%5D%7D++%7Bn+%5Cchoose+y%7D++%5Ccdot+x%5E%7By%7D+%281-x%29%5E%7Bn-y%7D+%5Ccdot++1+%5C%2C+%5Cmathrm+dx%7D+%5C%5C+%26%3D+%5Cfrac%7B+x%5E%7By%7D+%281-x%29%5E%7Bn-y%7D++%7D%7B+%5Cint_%7B%5B0%2C1%5D%7D++x%5E%7By%7D+%281-x%29%5E%7Bn-y%7D+%5C%2C+%5Cmathrm+dx%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
In particular,
![\begin{aligned} \mathbb P(X \in S \mid Y = \alpha) &= \int_{S} f_{X\mid Y}(x \mid \alpha)\, \mathrm dx \\ &= \int_{S} \frac{ x^{y} (1-x)^{n-y} }{ \int_{[0,1]} x^{\alpha} (1-x)^{n-\alpha} \, \mathrm dx}, \mathrm dx \\ &= \frac{ \int_{S} x^{\alpha} (1-x)^{n-\alpha} \, \mathrm dx }{ \int_{[0,1]} x^{\alpha} (1-x)^{n-\alpha} \, \mathrm dx} . \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+P%28X+%5Cin+S+%5Cmid+Y+%3D+%5Calpha%29+%26%3D+%5Cint_%7BS%7D+f_%7BX%5Cmid+Y%7D%28x+%5Cmid+%5Calpha%29%5C%2C+%5Cmathrm+dx+%5C%5C+%26%3D+%5Cint_%7BS%7D+%5Cfrac%7B+x%5E%7By%7D+%281-x%29%5E%7Bn-y%7D++%7D%7B+%5Cint_%7B%5B0%2C1%5D%7D++x%5E%7B%5Calpha%7D+%281-x%29%5E%7Bn-%5Calpha%7D+%5C%2C+%5Cmathrm+dx%7D%2C+%5Cmathrm+dx+%5C%5C+%26%3D+%5Cfrac%7B+%5Cint_%7BS%7D++x%5E%7B%5Calpha%7D+%281-x%29%5E%7Bn-%5Calpha%7D+%5C%2C+%5Cmathrm+dx+%7D%7B+%5Cint_%7B%5B0%2C1%5D%7D++x%5E%7B%5Calpha%7D+%281-x%29%5E%7Bn-%5Calpha%7D+%5C%2C+%5Cmathrm+dx%7D+.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
In what follows, set

where 


would be a somewhat confusing random variable, and the tail concentration bounds are conditioned on 
Remark 2. The challenge to generalise this result comes in require concrete distributions to work with, and so our general version would need to be “simplified” into, or expressed in terms of, a more computationally tractable option. One possible area for exploration would be considering the compact set of bounded-mean Gaussian distributions

where 
These upper bounds are, with more technical bookkeeping, ultimately responsible for the asymptotically optimal regret bounds. And since contiunity is a relatively benign condition, many risk functionals enjoy the tail upper bound of Theorem 1, and potentially, the asymptotically optimal regret bound for
Example 1. Given continuous risk functionals 
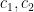

However, a proper proof of the Thompson sampling algorithm requires tail lower bounds. To achieve that goal, we introduce the notion of a dominant risk functional.
Definition 2. For any
![V(p, 0) = [p, 1],\quad V(p, 1) = [0,p].](https://s0.wp.com/latex.php?latex=V%28p%2C+0%29+%3D+%5Bp%2C+1%5D%2C%5Cquad++V%28p%2C+1%29+%3D+%5B0%2Cp%5D.&bg=ffffff&fg=000&s=0&c=20201002)
We say that a risk functional ![q \in [0,1]](https://s0.wp.com/latex.php?latex=q+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)


and 
In the original version, it was this concept that I dreamt of while struggling to solve the bandit problem. I prayed long and hard, and solved the problem in my dream thrice. I was shocked, and said to myself, “I must be dreaming. I will wake up and write down my solution.” And so at 4.30am sometime in February 2022, I did just that, and after a sanity check at 8.30am the next morning, concluded that the solution was correct.
In any case, the dominant risk functional property guarantees for us a much-needed tail lower bound.
Theorem 2. Fix 

Proof. Fix
and 

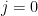
![\begin{aligned} \mathbb P(\tilde{\rho}(X) \in [r, \infty)) &\geq \mathbb P( \tilde{\rho}(X) \in \tilde{\rho}( V(q,0) )) \\ &= \mathbb P( \tilde{\rho}(X) \in \tilde{\rho}( [q, 1] )) \\ &= \mathbb P(X \in [q, 1]) \\ &= \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\int_q^1 x^{\alpha-1} (1-x)^{\beta-1}\, \mathrm dx \\ &\geq \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)} \cdot q^{\alpha-1} \int_q^1 x^{\beta-1}\, \mathrm dx \\ &=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)} \cdot q^{\alpha-1} \cdot \frac{(1-q)^{\beta}}{\beta} \\ &=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)} \cdot \underbrace{ \frac{\beta}{q} }_{\geq \beta} \cdot \underbrace{ \frac{q^{\alpha}}{(\alpha/n)^{\alpha}} \cdot \frac{(1-q)^{\beta}}{(\beta/n)^{\beta}} }_{\exp(-n \cdot \mathrm{KL}( \alpha/n, q ) )} \cdot \frac{\alpha^{\alpha} \cdot \beta^{\beta}}{n^n} \\ &\geq \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta+1)} \cdot \frac{\alpha^{\alpha} \cdot \beta^{\beta}}{n^n} \cdot \exp(-n \cdot \mathrm{KL}( \alpha/n, q ) ) . \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+P%28%5Ctilde%7B%5Crho%7D%28X%29+%5Cin+%5Br%2C+%5Cinfty%29%29+%26%5Cgeq+%5Cmathbb+P%28+%5Ctilde%7B%5Crho%7D%28X%29+%5Cin+%5Ctilde%7B%5Crho%7D%28+V%28q%2C0%29+%29%29+%5C%5C+%26%3D+%5Cmathbb+P%28+%5Ctilde%7B%5Crho%7D%28X%29+%5Cin+%5Ctilde%7B%5Crho%7D%28+%5Bq%2C+1%5D+%29%29+%5C%5C+%26%3D+%5Cmathbb+P%28X+%5Cin+%5Bq%2C+1%5D%29+%5C%5C+%26%3D+%5Cfrac%7B%5CGamma%28%5Calpha%2B%5Cbeta%29%7D%7B%5CGamma%28%5Calpha%29%5CGamma%28%5Cbeta%29%7D%5Cint_q%5E1+x%5E%7B%5Calpha-1%7D+%281-x%29%5E%7B%5Cbeta-1%7D%5C%2C+%5Cmathrm+dx+%5C%5C+%26%5Cgeq+%5Cfrac%7B%5CGamma%28%5Calpha%2B%5Cbeta%29%7D%7B%5CGamma%28%5Calpha%29%5CGamma%28%5Cbeta%29%7D+%5Ccdot+q%5E%7B%5Calpha-1%7D+%5Cint_q%5E1+x%5E%7B%5Cbeta-1%7D%5C%2C+%5Cmathrm+dx+%5C%5C+%26%3D%5Cfrac%7B%5CGamma%28%5Calpha%2B%5Cbeta%29%7D%7B%5CGamma%28%5Calpha%29%5CGamma%28%5Cbeta%29%7D+%5Ccdot+q%5E%7B%5Calpha-1%7D+%5Ccdot+%5Cfrac%7B%281-q%29%5E%7B%5Cbeta%7D%7D%7B%5Cbeta%7D+%5C%5C+%26%3D%5Cfrac%7B%5CGamma%28%5Calpha%2B%5Cbeta%29%7D%7B%5CGamma%28%5Calpha%29%5CGamma%28%5Cbeta%29%7D+%5Ccdot+%5Cunderbrace%7B+%5Cfrac%7B%5Cbeta%7D%7Bq%7D+%7D_%7B%5Cgeq+%5Cbeta%7D+%5Ccdot+%5Cunderbrace%7B+%5Cfrac%7Bq%5E%7B%5Calpha%7D%7D%7B%28%5Calpha%2Fn%29%5E%7B%5Calpha%7D%7D+%5Ccdot+%5Cfrac%7B%281-q%29%5E%7B%5Cbeta%7D%7D%7B%28%5Cbeta%2Fn%29%5E%7B%5Cbeta%7D%7D+%7D_%7B%5Cexp%28-n+%5Ccdot+%5Cmathrm%7BKL%7D%28+%5Calpha%2Fn%2C+q+%29+%29%7D+%5Ccdot+%5Cfrac%7B%5Calpha%5E%7B%5Calpha%7D+%5Ccdot+%5Cbeta%5E%7B%5Cbeta%7D%7D%7Bn%5En%7D+%5C%5C+%26%5Cgeq+%5Cfrac%7B%5CGamma%28%5Calpha%2B%5Cbeta%29%7D%7B%5CGamma%28%5Calpha%29%5CGamma%28%5Cbeta%2B1%29%7D+%5Ccdot+%5Cfrac%7B%5Calpha%5E%7B%5Calpha%7D+%5Ccdot+%5Cbeta%5E%7B%5Cbeta%7D%7D%7Bn%5En%7D+%5Ccdot+%5Cexp%28-n+%5Ccdot+%5Cmathrm%7BKL%7D%28+%5Calpha%2Fn%2C+q+%29+%29+.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
The rest of the calculation follows from the proof of Lemma 2 in Baudry et al (2021) by using Stirling’s approximation, and yields the desired lower bound

Remark 3. This tail bound eventually bounds all other terms by constants, once the exponentials cancel other exponentials out in subsequent calculations. The dream dealt with the slightly more general case 

Remark 4. The bounds in Theorems 1 and 2 work precisely for a special class of distributions, namely Bernoulli bandits (or slightly more generally, multinomial bandits). For other common classes of distributions, like Gaussians for example, we would need different tail lower bounds. Moreover, we would need to work with specific conjugate pairs of distributions, and approximate non-parametric bandits using parametric ones, which leads to messier approximation-controlling calculations when evaluating the regret bound.
But you might wonder—what functionals could pass the dominant risk functional criteria?
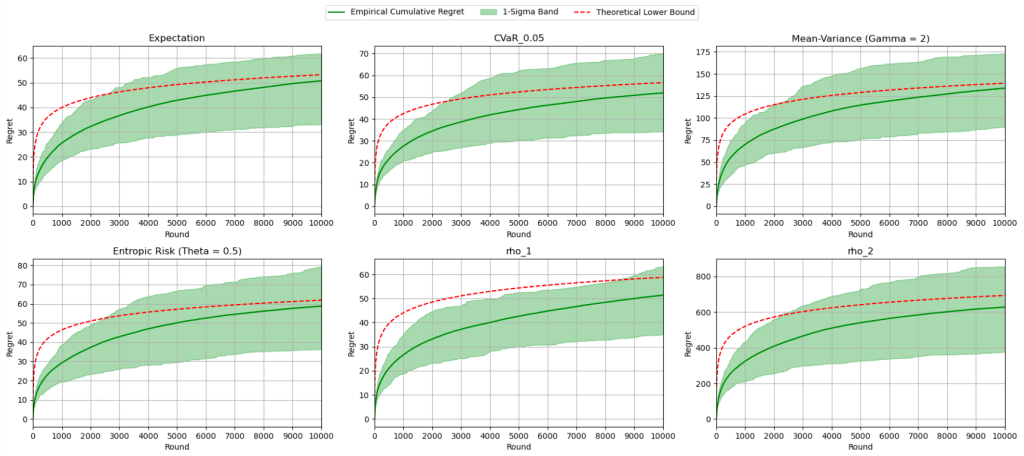
Lemma 2. Let ![c \in [0, 1]](https://s0.wp.com/latex.php?latex=c+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\tilde{\rho}|_{[0,c]}](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D%7C_%7B%5B0%2Cc%5D%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\tilde{\rho}|_{[c,1]}](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D%7C_%7B%5Bc%2C1%5D%7D&bg=ffffff&fg=000&s=0&c=20201002)
Proof. Fix

Set 

![q \in [0, c]](https://s0.wp.com/latex.php?latex=q+%5Cin+%5B0%2C+c%5D&bg=ffffff&fg=000&s=0&c=20201002)
![q \in [c, 1]](https://s0.wp.com/latex.php?latex=q+%5Cin+%5Bc%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)

![s \in [0, q]](https://s0.wp.com/latex.php?latex=s+%5Cin+%5B0%2C+q%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\tilde{\rho}(V(q,1)) = \tilde{\rho}([0, q]) \subseteq [\tilde{\rho}(q), \infty),](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D%28V%28q%2C1%29%29+%3D+%5Ctilde%7B%5Crho%7D%28%5B0%2C+q%5D%29+%5Csubseteq+%5B%5Ctilde%7B%5Crho%7D%28q%29%2C+%5Cinfty%29%2C&bg=ffffff&fg=000&s=0&c=20201002)
as required. In the latter, ![s \in [q,1]](https://s0.wp.com/latex.php?latex=s+%5Cin+%5Bq%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\tilde{\rho}(V(q,0)) = \tilde{\rho}([q, 1]) \subseteq [\tilde{\rho}(q), \infty),](https://s0.wp.com/latex.php?latex=%5Ctilde%7B%5Crho%7D%28V%28q%2C0%29%29+%3D+%5Ctilde%7B%5Crho%7D%28%5Bq%2C+1%5D%29+%5Csubseteq+%5B%5Ctilde%7B%5Crho%7D%28q%29%2C+%5Cinfty%29%2C&bg=ffffff&fg=000&s=0&c=20201002)
as required. If 
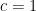
Remark 5. For two risk functionals 



Example 2. Given 


![\phi : [0, 1] \to [0,\infty)](https://s0.wp.com/latex.php?latex=%5Cphi+%3A+%5B0%2C+1%5D+%5Cto+%5B0%2C%5Cinfty%29&bg=ffffff&fg=000&s=0&c=20201002)

- Expected value:
,
- Conditional value-at-risk:
- Proportional hazard:
- Lookback:
- Spectral risk:
- Entropic risk:
- Dual power distortion:
- Wang transform:
- Logarithmic distortion:
-Sharpe ratio:









Remark 6. Since the Sharpe ratio is not well-defined at 

![[0, (1-\delta)^{-1}) \supseteq [0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C+%281-%5Cdelta%29%5E%7B-1%7D%29+%5Csupseteq+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)



satisfies the requirements of Lemma 1, and we recover its useful tail bounds.
Lemma 3. If ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)

Proof. We claim that no matter what,
- If
, then
- If
, then
- If there exists
such that
, then the intermediate value property of derivatives yields
such that
. Since
is non-increasing and
.
In all three cases,
Remark 7. More generally, if ![t \in [0, 1]](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
![x, y \in [0, 1]](https://s0.wp.com/latex.php?latex=x%2C+y+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)

the risk functional
Example 3. Given
- Second moment:
- Negative variance:
- Mean-variance:
- Target semi-variance:
- Exponential tilt:
- Quadratic utility:
![\rho_{\text{SM}}(\nu_p) = \mathbb E[X^2] = p](https://s0.wp.com/latex.php?latex=%5Crho_%7B%5Ctext%7BSM%7D%7D%28%5Cnu_p%29+%3D+%5Cmathbb+E%5BX%5E2%5D+%3D+p&bg=ffffff&fg=000&s=0&c=20201002)


![\rho_{\mathrm{TSV}_r}(\nu) = -\mathbb E[\min\{ X-r , 0 \}^2 ]](https://s0.wp.com/latex.php?latex=%5Crho_%7B%5Cmathrm%7BTSV%7D_r%7D%28%5Cnu%29+%3D+-%5Cmathbb+E%5B%5Cmin%5C%7B+X-r+%2C++0+%5C%7D%5E2+%5D+&bg=ffffff&fg=000&s=0&c=20201002)


Furthermore, for two risk functionals 

Therefore, most risk functionals as listed in Examples 1, 2, and 3 are the ones that most people care about are in fact continuous and dominant, and therefore, by passing the relevant arguments through much book-keeping, enjoy the asymptotically optimal regret bound for
Theorem 3. The regret bound of

Proof. Follow the proof of Theorem 1 in Chang and Tan (2022), and apply Theorems 1 and 2 in the analysis. Left as an exercise (effectively) in algebra and mildly clever calculus.
Oh, by the way, with the help of ChatGPT, here’s a Jupyter writeup of the implemented algorithm and some pretty pictures!
The red curve indicates the theoretical asymptotic lower bound, and each diagram reflects the algorithm running for a fixed 


And for them all, the asymptotic lower bound lies happily in their 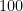
And with that, we are truly done. Happy lunar new year!
—Joel Kindiak, 16 Feb 26, 1131H

Leave a comment