Given two random variables  with known distributions (for example,
with known distributions (for example,  and
and  ), what is the distribution of their sum
), what is the distribution of their sum  ? This question is highly nontrivial, and is worth some elementary experimentation.
? This question is highly nontrivial, and is worth some elementary experimentation.
Let’s work with the Bernoulli example and see what we can get. The first case is, in a sense, the “easiest” case to work with:  and
and  . Using ordered-pair notation,
. Using ordered-pair notation,  . In this case,
. In this case,  . Furthermore, if
. Furthermore, if  , then
, then  , so that there is, in a sense, only one possible case to handle. Therefore, at least informally,
, so that there is, in a sense, only one possible case to handle. Therefore, at least informally,

However, the probability on the right side raises a new question: what do we mean by  ? If we insist (rather intuitively) that
? If we insist (rather intuitively) that

we are implicitly assuming that  are independent in some sense (but we need to formalise this notion later on), which may not always be the case! Our first task therefore isn’t even to compute , but to examine what we mean by
are independent in some sense (but we need to formalise this notion later on), which may not always be the case! Our first task therefore isn’t even to compute , but to examine what we mean by  , i.e. the joint distribution of
, i.e. the joint distribution of  and
and  .
.
Lemma 1. Let  be a probability space and
be a probability space and  be discrete random variables. The product map
be discrete random variables. The product map  defined by
defined by

is measurable, when  is equipped with the usual
is equipped with the usual  -algebra
-algebra  , and induces a push-forward measure
, and induces a push-forward measure ![\mathbb P_{\mathbf X_n} : \mathcal P(\mathbb Z^n) \to [0, 1]](https://s0.wp.com/latex.php?latex=%5Cmathbb+P_%7B%5Cmathbf+X_n%7D+%3A+%5Cmathcal+P%28%5Cmathbb+Z%5En%29+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) defined by
defined by

While  shares many properties of discrete random variables, its range is not a subset of , and to reduce confusion we restrict the term “discrete random variables” to the original definition.
shares many properties of discrete random variables, its range is not a subset of , and to reduce confusion we restrict the term “discrete random variables” to the original definition.
But what would be the joint distribution of 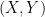 ? That is, what is the value of
? That is, what is the value of

for any  ? Perhaps
? Perhaps  could be defined arbitrarily, as long as we have each value in
could be defined arbitrarily, as long as we have each value in ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) and
and

However, there are two more sneaky conditions.
Lemma 2. For any  with
with  ,
,

Similarly, for any  with
with  ,
,

Proof. Recall that for any such that  , the conditional probability
, the conditional probability
![\displaystyle \mathbb P( \cdot \mid Y = y ) : \mathcal F \to [0, 1]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+P%28+%5Ccdot++%5Cmid++Y+%3D+y+%29++%3A+%5Cmathcal+F+%5Cto+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
is a probability measure, which induces a probability measure
![\mathbb P( X \in \cdot \mid Y = y ) : \mathcal P(\mathbb Z) \to [0, 1].](https://s0.wp.com/latex.php?latex=%5Cmathbb+P%28+X+%5Cin+%5Ccdot++%5Cmid++Y+%3D+y+%29+%3A+%5Cmathcal+P%28%5Cmathbb+Z%29+%5Cto+%5B0%2C+1%5D.&bg=ffffff&fg=000&s=0&c=20201002)
Thus, we must require that

Hence,

Thankfully, convergence issues resolve themselves here.
Still, do we have an algorithmic way to compute the joint distribution? If the events  are independent for any
are independent for any  , then
, then

Hence, we define the independence of the random variables in this manner.
Definition 1. The discrete random variables  are independent if for any
are independent if for any  , the events
, the events  are independent. In this case,
are independent. In this case,

Using p.m.f. notation,

Example 1. Suppose and are independent random variables. Evaluate the distribution of  .
.
Solution. We note that the joint distribution 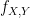 is given by
is given by

We observe that  . Hence,
. Hence,

Notice that  is evaluated by summing the cases of
is evaluated by summing the cases of 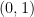 and
and 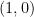 . More generally, we have
. More generally, we have

where the quantity on the right is called the discrete convolution of  and
and  . Time to generalise!
. Time to generalise!
Theorem 1. Let  be discrete random variables. Given any function
be discrete random variables. Given any function  , the random variable
, the random variable  exists and is given by the distribution
exists and is given by the distribution

If are independent, then the distribution is given by

In particular,

Example 2. Fix ![p \in [0, 1]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002) . Given that
. Given that  are independent,
are independent,  has a distribution given by
has a distribution given by

Furthermore, for any  , the distribution of
, the distribution of  is given by
is given by

Proof. The case 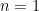 is trivial. Example 1 establishes the case
is trivial. Example 1 establishes the case 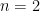 . For the general case, we prove by induction. Suppose for any
. For the general case, we prove by induction. Suppose for any  ,
,

Suppose  . Then
. Then  . By the discrete convolution and Pascal’s identity,
. By the discrete convolution and Pascal’s identity,

Example 2 is basically the definition of the Binomial distribution.
Definition 2. Fix  and . We say that the random variable follows a Binomial distribution with parameters
and . We say that the random variable follows a Binomial distribution with parameters  , denoted
, denoted  , if there exists independent Bernoulli random variables
, if there exists independent Bernoulli random variables  such that
such that

Trivially,  .
.
Corollary 1. If  and
and  are independent, then
are independent, then  .
.
Proof. Find independent random variables  such that
such that

Then

With some distributions at hand, we ask a reasonable question: how do we calculate the averages of these distributions? We will answer this question using expectations next time.
—Joel Kindiak, 29 Jun 25, 2229H

Leave a comment