This set of posts hit close to my heart, as the subject matter of my undergraduate research experience. Most of what I write references the “Bandit Bible” by Tor Lattimore and Csaba Szepesvári. In a sense, the goal of these posts is to communicate my research, and hopefully, accomplish its lofty potential (that did not happen while I was an undergraduate).
Suppose you entered a casino with 1000 one-dollar coins, and there are 5 slot machines in front of you. Each turn, you insert one coin into a machine of your choice. Your goal is to maximise your gains from the machine. How would you allocate your coins?
Definition 1. A stochastic 

Suppose you pull the arms for a total of 




Seeing that this task is rather ambitious, since we need to optimise over uncountably many possibilities, we can, and should, simplify our objectives. Instead of maximising our total reward, lets maximise the total expected reward:
![\displaystyle \mathbb E\left[ \sum_{t=1}^n X_t \right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt%3D1%7D%5En+X_t+%5Cright%5D.&bg=ffffff&fg=000&s=0&c=20201002)
For this goal to be a meaningful one, one of the arms should have the highest mean. Let’s formalise this intuition a bit more:
- For each
, assume that the mean of the
-th arm
, where
, is finite.
- In this case, the quantity
exists. Suppose
without loss of generality.
- Suppose furthermore that for
,
. Define the suboptimality gap by
.
Hence, we would like to choose our arms so that we can minimise our cumulative regret:
![\displaystyle \mathcal R_n(\nu) = n \mu_1 - \mathbb E\left[ \sum_{t=1}^n X_t \right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal+R_n%28%5Cnu%29+%3D+n+%5Cmu_1+-+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt%3D1%7D%5En+X_t+%5Cright%5D.&bg=ffffff&fg=000&s=0&c=20201002)
We call our choice of arms our policy, denoted 



Different policies 
![\displaystyle \mathcal R_n(\pi, \nu) = n \mu_1 - \mathbb E\left[ \sum_{t=1}^n X_t \right] \geq 0,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal+R_n%28%5Cpi%2C+%5Cnu%29+%3D+n+%5Cmu_1+-+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt%3D1%7D%5En+X_t+%5Cright%5D+%5Cgeq+0%2C&bg=ffffff&fg=000&s=0&c=20201002)
to emphasise that the rewards 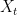
Theorem 1. Using our formalisations, we can decompose the regret as follows:
![\displaystyle \mathcal R_n(\pi, \nu) = \sum_{i=1}^K \mathbb E[T_n(i)] \Delta_i ,\quad T_n(i) := \sum_{t=1}^n \mathbb I\{A_t = i\}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal+R_n%28%5Cpi%2C+%5Cnu%29+%3D+%5Csum_%7Bi%3D1%7D%5EK+%5Cmathbb+E%5BT_n%28i%29%5D+%5CDelta_i+%2C%5Cquad+T_n%28i%29+%3A%3D+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+I%5C%7BA_t+%3D+i%5C%7D.&bg=ffffff&fg=000&s=0&c=20201002)
Proof. At each 

Summing over 

Taking expectations,
![\begin{aligned} \mathbb E\left[ \sum_{t=1}^n X_t \right] &= \sum_{i=1}^K \sum_{t=1}^n \mathbb E[ X_{A_t} \cdot \mathbb I\{A_t = i\} ]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt%3D1%7D%5En+X_t+%5Cright%5D+%26%3D+%5Csum_%7Bi%3D1%7D%5EK+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+E%5B+X_%7BA_t%7D+%5Ccdot+%5Cmathbb+I%5C%7BA_t+%3D+i%5C%7D+%5D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Using the tower rule,
![\begin{aligned} \mathbb E[ X_{A_t} \cdot \mathbb I\{A_t = i\} ] &= \mathbb E[ \mathbb E[ X_{A_t} \cdot \mathbb I\{A_t = i\} \mid A_t]] \\ &= \mathbb E[ \mathbb I\{A_t = i\} \cdot \mathbb E[ X_{A_t} \mid A_t]] \\ &= \mathbb E[ \mathbb I\{A_t = i\} \cdot \mu_{A_t}] \\ &= \mathbb E[ \mathbb I\{A_t = i\} \cdot \mu_i].\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5B+X_%7BA_t%7D+%5Ccdot+%5Cmathbb+I%5C%7BA_t+%3D+i%5C%7D+%5D+%26%3D+%5Cmathbb+E%5B+%5Cmathbb+E%5B+X_%7BA_t%7D+%5Ccdot+%5Cmathbb+I%5C%7BA_t+%3D+i%5C%7D+%5Cmid+A_t%5D%5D+%5C%5C+%26%3D+%5Cmathbb+E%5B+%5Cmathbb+I%5C%7BA_t+%3D+i%5C%7D+%5Ccdot+%5Cmathbb+E%5B+X_%7BA_t%7D++%5Cmid+A_t%5D%5D+%5C%5C+%26%3D+%5Cmathbb+E%5B+%5Cmathbb+I%5C%7BA_t+%3D+i%5C%7D+%5Ccdot+%5Cmu_%7BA_t%7D%5D+%5C%5C+%26%3D+%5Cmathbb+E%5B+%5Cmathbb+I%5C%7BA_t+%3D+i%5C%7D+%5Ccdot+%5Cmu_i%5D.%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Using the definition of 
![\begin{aligned} \mathcal R_n(\pi, \nu) &= n \mu_1 - \mathbb E\left[ \sum_{t=1}^n X_t \right] \\ &= n \mu_1 - \sum_{i=1}^K \sum_{t=1}^n \mathbb E[ X_{A_t} \cdot \mathbb I\{A_t = i\} ] \\ &= n \mu_1 - \sum_{i=1}^K \sum_{t=1}^n \mathbb E[ \mathbb I\{A_t = i\} \cdot \mu_{i}] \\ &= \sum_{i=1}^K \sum_{t=1}^n \mathbb E[ \mathbb I\{A_t = i\} \cdot (\mu_1 - \mu_i)] \\ &= \sum_{i=1}^K \sum_{t=1}^n \mathbb E[ \mathbb I\{A_t = i\} \cdot \Delta_i] \\ &= \sum_{i=1}^K\mathbb E\left[ \sum_{t=1}^n \mathbb I\{A_t = i\} \right]\Delta_i \\ &= \sum_{i=1}^K\mathbb E[T_n(i)] \Delta_i. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++%5Cmathcal+R_n%28%5Cpi%2C+%5Cnu%29+%26%3D+n+%5Cmu_1+-+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt%3D1%7D%5En+X_t+%5Cright%5D+%5C%5C+%26%3D+n+%5Cmu_1++-+%5Csum_%7Bi%3D1%7D%5EK+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+E%5B+X_%7BA_t%7D+%5Ccdot+%5Cmathbb+I%5C%7BA_t+%3D+i%5C%7D+%5D+%5C%5C+%26%3D+n+%5Cmu_1++-+%5Csum_%7Bi%3D1%7D%5EK+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+E%5B+%5Cmathbb+I%5C%7BA_t+%3D+i%5C%7D+%5Ccdot+%5Cmu_%7Bi%7D%5D+%5C%5C+%26%3D+%5Csum_%7Bi%3D1%7D%5EK+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+E%5B+%5Cmathbb+I%5C%7BA_t+%3D+i%5C%7D+%5Ccdot+%28%5Cmu_1+-+%5Cmu_i%29%5D+%5C%5C+%26%3D+%5Csum_%7Bi%3D1%7D%5EK+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+E%5B+%5Cmathbb+I%5C%7BA_t+%3D+i%5C%7D+%5Ccdot+%5CDelta_i%5D+%5C%5C+%26%3D+%5Csum_%7Bi%3D1%7D%5EK%5Cmathbb+E%5Cleft%5B++%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+I%5C%7BA_t+%3D+i%5C%7D+%5Cright%5D%5CDelta_i+%5C%5C+%26%3D+%5Csum_%7Bi%3D1%7D%5EK%5Cmathbb+E%5BT_n%28i%29%5D+%5CDelta_i.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
My work focused on risk-averse bandits, which basically asks for the same cumulative regret minimisation goal, except that the vanilla suboptimality gap 
![\displaystyle \mathcal R_n^{\rho}(\pi, \nu) = \sum_{i=1}^K \mathbb E[T_n(i)] \Delta _i^\rho.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal+R_n%5E%7B%5Crho%7D%28%5Cpi%2C+%5Cnu%29+%3D+%5Csum_%7Bi%3D1%7D%5EK+%5Cmathbb+E%5BT_n%28i%29%5D+%5CDelta+_i%5E%5Crho.&bg=ffffff&fg=000&s=0&c=20201002)
Here, 

![\mathbb E[X] = \mu_i](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%3D+%5Cmu_i&bg=ffffff&fg=000&s=0&c=20201002)

![\mathbb E[X] = \nu_i = \mathbb E[Y]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%3D+%5Cnu_i+%3D+%5Cmathbb+E%5BY%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\rho_{\mathbb E}(\nu_i) := \mathbb E[X]](https://s0.wp.com/latex.php?latex=%5Crho_%7B%5Cmathbb+E%7D%28%5Cnu_i%29+%3A%3D+%5Cmathbb+E%5BX%5D&bg=ffffff&fg=000&s=0&c=20201002)

Therefore, 

![\rho_{\mathbb{V}}(\nu_i) := \mathrm{Var}(X_i) \equiv \mathbb E[(X-\mathbb E[X])^2],\quad X \sim \nu_i.](https://s0.wp.com/latex.php?latex=%5Crho_%7B%5Cmathbb%7BV%7D%7D%28%5Cnu_i%29+%3A%3D+%5Cmathrm%7BVar%7D%28X_i%29+%5Cequiv+%5Cmathbb+E%5B%28X-%5Cmathbb+E%5BX%5D%29%5E2%5D%2C%5Cquad+X+%5Csim+%5Cnu_i.&bg=ffffff&fg=000&s=0&c=20201002)
A popular risk measure in modern portfolio theory is the mean-variance with parameter 

The risk measure that I was initially interested in was the conditional value-at-risk.
In any case, given a risk functional 

Hence, our goal is to design a policy that minimises the cumulative
We are going to first work with the usual case ![\rho_{\mathbb E}(\nu_i) = \mathbb E[X]](https://s0.wp.com/latex.php?latex=%5Crho_%7B%5Cmathbb+E%7D%28%5Cnu_i%29+%3D+%5Cmathbb+E%5BX%5D&bg=ffffff&fg=000&s=0&c=20201002)

- Explore-then-Commit
- Upper Confidence Bound
- Thompson Sampling
It is this last algorithm that consumed my waking and sleeping hours in my undergraduate years.
—Joel Kindiak, 9 Feb 26, 1306H

Leave a comment