What would be a zero-th order solution to the 


![\displaystyle \mathcal R_n(\pi, \nu) = \sum_{i=1}^K \mathbb E[T_i(n)] \Delta_i,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal+R_n%28%5Cpi%2C+%5Cnu%29+%3D+%5Csum_%7Bi%3D1%7D%5EK+%5Cmathbb+E%5BT_i%28n%29%5D+%5CDelta_i%2C&bg=ffffff&fg=000&s=0&c=20201002)
where:
denotes our choice of arms, i.e., our solution,
denotes the total number of pulls of arm
as of time
- and
denotes the suboptimality gap.
Here, we assumed that 




As a first pass, let’s explore, then commit.
- We fix an exploration time
, and we explore each arm
times first. During this exploration phase, we would obtain the quantity
, where each
independently.
- For the remaining
turns we pull the arm
.
This algorithm is called the explore-then-commit algorithm.
Lemma 1. For each arm
![\displaystyle \mathbb E[T_i(n)] \leq m + (n - mK) \cdot \mathbb P((\hat{\mu}_i - \mu_i) - (\hat{\mu}_1 - \mu_1) \geq \Delta_i).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5BT_i%28n%29%5D+%5Cleq+m+%2B+%28n+-+mK%29+%5Ccdot+%5Cmathbb+P%28%28%5Chat%7B%5Cmu%7D_i+-+%5Cmu_i%29+-+%28%5Chat%7B%5Cmu%7D_1+-+%5Cmu_1%29+%5Cgeq+%5CDelta_i%29.&bg=ffffff&fg=000&s=0&c=20201002)
Proof. For any arm

Therefore, for each arm
![\begin{aligned} \mathbb E[T_i(n)] &= \mathbb E[T_i(n) \mid E_i] \cdot \mathbb P(E_i) \\ &= m + (n-mK) \cdot \mathbb P(E_i) \\ &\leq m + (n - mK) \cdot \mathbb P((\hat{\mu}_i - \mu_i) - (\hat{\mu}_1 - \mu_1) \geq \Delta_i). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BT_i%28n%29%5D+%26%3D+%5Cmathbb+E%5BT_i%28n%29+%5Cmid+E_i%5D+%5Ccdot+%5Cmathbb+P%28E_i%29+%5C%5C+%26%3D+m+%2B+%28n-mK%29+%5Ccdot+%5Cmathbb+P%28E_i%29+%5C%5C+%26%5Cleq+m+%2B+%28n+-+mK%29+%5Ccdot+%5Cmathbb+P%28%28%5Chat%7B%5Cmu%7D_i+-+%5Cmu_i%29+-+%28%5Chat%7B%5Cmu%7D_1+-+%5Cmu_1%29+%5Cgeq+%5CDelta_i%29.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Therefore, the efficacy of the explore-then-commit algorithm depends on our ability to bound the term

which itself depends on the underlying distributions 
Lemma 2. For any 

![\mathbb E[\exp(\lambda X)] = \exp(\lambda^2 \sigma^2/2).](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%5Cexp%28%5Clambda+X%29%5D+%3D+%5Cexp%28%5Clambda%5E2+%5Csigma%5E2%2F2%29.&bg=ffffff&fg=000&s=0&c=20201002)
Proof. Fix 

![\begin{aligned} \mathbb E[\exp(\lambda X)] &= \int_{\mathbb R} e^{\lambda x} \cdot \frac 1{\sqrt{2\pi}} e^{-x^2/2}\, \mathrm dx \\ &= \frac 1{\sqrt{2\pi}} \int_{\mathbb R} e^{-((x - \lambda)^2 - \lambda^2)/2}\, \mathrm dx \\ &= e^{\lambda^2/2} \cdot \frac 1{\sqrt{2\pi}} \int_{\mathbb R} e^{-(x - \lambda)^2/2}\, \mathrm dx \\ &=e^{\lambda^2/2} \cdot 1 = e^{\lambda^2/2}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5B%5Cexp%28%5Clambda+X%29%5D+%26%3D+%5Cint_%7B%5Cmathbb+R%7D+e%5E%7B%5Clambda+x%7D+%5Ccdot+%5Cfrac+1%7B%5Csqrt%7B2%5Cpi%7D%7D+e%5E%7B-x%5E2%2F2%7D%5C%2C+%5Cmathrm+dx+%5C%5C+%26%3D+%5Cfrac+1%7B%5Csqrt%7B2%5Cpi%7D%7D+%5Cint_%7B%5Cmathbb+R%7D+e%5E%7B-%28%28x+-+%5Clambda%29%5E2+-+%5Clambda%5E2%29%2F2%7D%5C%2C+%5Cmathrm+dx+%5C%5C+%26%3D+e%5E%7B%5Clambda%5E2%2F2%7D+%5Ccdot+%5Cfrac+1%7B%5Csqrt%7B2%5Cpi%7D%7D+%5Cint_%7B%5Cmathbb+R%7D+e%5E%7B-%28x+-+%5Clambda%29%5E2%2F2%7D%5C%2C+%5Cmathrm+dx+%5C%5C+%26%3De%5E%7B%5Clambda%5E2%2F2%7D+%5Ccdot+1+%3D+e%5E%7B%5Clambda%5E2%2F2%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Therefore, 

For the general case, write 
![\mathbb E[\exp(\lambda X)] = \mathbb E[\exp((\sigma \lambda) Z)] = e^{(\sigma \lambda)^2/2} = e^{\lambda^2 \sigma^2/2}.](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%5Cexp%28%5Clambda+X%29%5D+%3D+%5Cmathbb+E%5B%5Cexp%28%28%5Csigma+%5Clambda%29+Z%29%5D+%3D+e%5E%7B%28%5Csigma+%5Clambda%29%5E2%2F2%7D+%3D+e%5E%7B%5Clambda%5E2+%5Csigma%5E2%2F2%7D.&bg=ffffff&fg=000&s=0&c=20201002)
Therefore, 

Hence, we generalise this inequality property. Any distribution that satisfies this inequality property shall hence-forth be called sub-Gaussian.
Definition 1. Let 
![\mathbb E[\exp(\lambda X)] \leq \exp(\lambda^2 \sigma^2/2).](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%5Cexp%28%5Clambda+X%29%5D+%5Cleq+%5Cexp%28%5Clambda%5E2+%5Csigma%5E2%2F2%29.&bg=ffffff&fg=000&s=0&c=20201002)
Unsurprisingly,
Theorem 1. Let 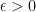

Proof. We use the Cramer-Chernoff method by taking exponentials followed by applying Markov’s inequality: for any 
![\begin{aligned} \mathbb P(X \geq \epsilon) & = \mathbb P(\exp(\lambda X) \geq \exp(\lambda \epsilon)) \\ &\leq \frac{\mathbb E[\exp(\lambda X)]}{\exp(\lambda \epsilon)} \\ &\leq \frac{ \exp(\lambda^2 \sigma^2/2) }{\exp(\lambda \epsilon)} \\ &= \exp(\lambda^2 \sigma^2/2 - \lambda \epsilon). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+P%28X+%5Cgeq+%5Cepsilon%29+%26+%3D+%5Cmathbb+P%28%5Cexp%28%5Clambda+X%29+%5Cgeq+%5Cexp%28%5Clambda+%5Cepsilon%29%29+%5C%5C+%26%5Cleq+%5Cfrac%7B%5Cmathbb+E%5B%5Cexp%28%5Clambda+X%29%5D%7D%7B%5Cexp%28%5Clambda+%5Cepsilon%29%7D+%5C%5C+%26%5Cleq+%5Cfrac%7B+%5Cexp%28%5Clambda%5E2+%5Csigma%5E2%2F2%29+%7D%7B%5Cexp%28%5Clambda+%5Cepsilon%29%7D+%5C%5C+%26%3D+%5Cexp%28%5Clambda%5E2+%5Csigma%5E2%2F2+-+%5Clambda+%5Cepsilon%29.++%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
In particular, 


Therefore, particularising to 
Remark 1. Given 
Sub-Gaussian distributions can produce new distributions.
Lemma 3. Let 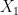
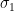

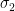
- For any
,
is
-sub-Gaussian.
is
-sub-Gaussian.
Proof. By a similar argument in Lemma 2, for any
![\begin{aligned} \mathbb E[\exp(\lambda (\alpha X))] &= \mathbb E[\exp( (\lambda \alpha) X)] \\ &\leq \exp((\lambda \alpha)^2 \sigma^2/2) \\ &\leq \exp(\lambda^2 (|\alpha| \sigma)^2/2), \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5B%5Cexp%28%5Clambda+%28%5Calpha+X%29%29%5D+%26%3D+%5Cmathbb+E%5B%5Cexp%28+%28%5Clambda+%5Calpha%29+X%29%5D+%5C%5C+%26%5Cleq+%5Cexp%28%28%5Clambda+%5Calpha%29%5E2+%5Csigma%5E2%2F2%29+%5C%5C+%26%5Cleq+%5Cexp%28%5Clambda%5E2+%28%7C%5Calpha%7C+%5Csigma%29%5E2%2F2%29%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
as required. The second result follows similarly by denoting 
![\begin{aligned} \mathbb E[\exp(\lambda (X_1 + X_2))] &= \mathbb E[\exp(\lambda(X_1 + X_2))] \\ &= \mathbb E[\exp(\lambda X_1)\exp(\lambda X_2)] \\ &= \mathbb E[\exp(\lambda X_1)] \cdot \mathbb E[\exp(\lambda X_2)] \\ &\leq \exp(\lambda^2 \sigma_1^2/2) \cdot \exp(\lambda^2 \sigma_2^2/2) \\ &\leq \exp(\lambda^2 (\sigma_1^2 + \sigma_2^2)/2) \\ &\leq \exp(\lambda^2 \sigma^2/2), \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5B%5Cexp%28%5Clambda+%28X_1+%2B+X_2%29%29%5D+%26%3D+%5Cmathbb+E%5B%5Cexp%28%5Clambda%28X_1+%2B+X_2%29%29%5D+%5C%5C+%26%3D+%5Cmathbb+E%5B%5Cexp%28%5Clambda+X_1%29%5Cexp%28%5Clambda+X_2%29%5D+%5C%5C+%26%3D+%5Cmathbb+E%5B%5Cexp%28%5Clambda+X_1%29%5D+%5Ccdot+%5Cmathbb+E%5B%5Cexp%28%5Clambda+X_2%29%5D+%5C%5C+%26%5Cleq+%5Cexp%28%5Clambda%5E2+%5Csigma_1%5E2%2F2%29+%5Ccdot+%5Cexp%28%5Clambda%5E2+%5Csigma_2%5E2%2F2%29+%5C%5C+%26%5Cleq+%5Cexp%28%5Clambda%5E2+%28%5Csigma_1%5E2+%2B+%5Csigma_2%5E2%29%2F2%29+%5C%5C+%26%5Cleq+%5Cexp%28%5Clambda%5E2+%5Csigma%5E2%2F2%29%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
as required.
Definition 2.We say that a probability distribution ![\mathbb E[X] = \nu](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%3D+%5Cnu&bg=ffffff&fg=000&s=0&c=20201002)
Corollary 1. Suppose for simplicity that each 

Proof. Suppose each 


has zero mean and is 

Substituting into Lemma 1 and the definition of 
Having a result that works for basically any sub-Gaussian distribution
Example 1. Given a probability distribution 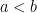
![X \in [a, b]](https://s0.wp.com/latex.php?latex=X+%5Cin+%5Ba%2C+b%5D&bg=ffffff&fg=000&s=0&c=20201002)

Proof. We follow this post. Denote ![M_X(t) = \mathbb E[\exp(tX)]](https://s0.wp.com/latex.php?latex=M_X%28t%29+%3D+%5Cmathbb+E%5B%5Cexp%28tX%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![M_X^{(n)}(t) = \mathbb E[X^n \exp(tX)]](https://s0.wp.com/latex.php?latex=M_X%5E%7B%28n%29%7D%28t%29+%3D+%5Cmathbb+E%5BX%5En+%5Cexp%28tX%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
for any natural number 


and hence,
![\begin{aligned} \psi_X''(t) &= \frac{M_X''(t)}{M_X(t)} - (\psi_X'(t))^2 \\ &= \mathbb E\left[ X^2 \cdot \frac{\exp(tX)}{M_X(t)} \right] - \mathbb E\left[X \cdot \frac{\exp(tX)}{M_X(t)}\right]^2 \\ &= \mathbb E[X^2 \cdot g_t(X)] - \mathbb E[X g_t(X)]^2,\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cpsi_X%27%27%28t%29+%26%3D+%5Cfrac%7BM_X%27%27%28t%29%7D%7BM_X%28t%29%7D+-+%28%5Cpsi_X%27%28t%29%29%5E2+%5C%5C+%26%3D+%5Cmathbb+E%5Cleft%5B+X%5E2+%5Ccdot+%5Cfrac%7B%5Cexp%28tX%29%7D%7BM_X%28t%29%7D+%5Cright%5D+-+%5Cmathbb+E%5Cleft%5BX+%5Ccdot+%5Cfrac%7B%5Cexp%28tX%29%7D%7BM_X%28t%29%7D%5Cright%5D%5E2+%5C%5C+%26%3D+%5Cmathbb+E%5BX%5E2+%5Ccdot+g_t%28X%29%5D+-+%5Cmathbb+E%5BX+g_t%28X%29%5D%5E2%2C%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
where we denoted 


![\displaystyle \mathbb P_t(K) := \int_K g_t(X)\, \mathrm d\nu = \mathbb E[\mathbb I_K \cdot g_t(X)],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+P_t%28K%29+%3A%3D+%5Cint_K+g_t%28X%29%5C%2C+%5Cmathrm+d%5Cnu+%3D+%5Cmathbb+E%5B%5Cmathbb+I_K+%5Ccdot+g_t%28X%29%5D%2C&bg=ffffff&fg=000&s=0&c=20201002)
so that 

![\displaystyle \mathbb E_t[Y] := \int_{\mathbb R}Y\, \mathrm{d}\mathbb P_t = \int_{\mathbb R}Y \cdot g_t(X)\, \mathrm{d}\nu = \mathbb E[Y \cdot g_t(X)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E_t%5BY%5D+%3A%3D+%5Cint_%7B%5Cmathbb+R%7DY%5C%2C+%5Cmathrm%7Bd%7D%5Cmathbb+P_t+%3D+%5Cint_%7B%5Cmathbb+R%7DY+%5Ccdot+g_t%28X%29%5C%2C+%5Cmathrm%7Bd%7D%5Cnu+%3D+%5Cmathbb+E%5BY+%5Ccdot+g_t%28X%29%5D.&bg=ffffff&fg=000&s=0&c=20201002)
Therefore,
![\begin{aligned} \psi_X''(t) &= \mathbb E[X^2 \cdot g_t(X)] - \mathbb E[X g_t(X)]^2 \\ &= \mathbb E_t[X^2] - \mathbb E_t[X^2] \\ &= \mathbb E_t[ (X - \mathbb E_t[X])^2 ] \\ &= \min_{c \in \mathbb R} \mathbb E_t[ (X - c)^2 ] \\&\leq \mathbb E_t\left[ \left(X - \frac{a+b}{2} \right)^2 \right] \\&\leq \mathbb E_t\left[ \left(b - \frac{a+b}{2} \right)^2 \right] \\ &= \frac{(b-a)^2}{4} \cdot \underbrace{ \mathbb E[g_t(X)] }_1 = \frac{(b-a)^2}{4}.\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cpsi_X%27%27%28t%29+%26%3D+%5Cmathbb+E%5BX%5E2+%5Ccdot+g_t%28X%29%5D+-+%5Cmathbb+E%5BX+g_t%28X%29%5D%5E2+%5C%5C+%26%3D+%5Cmathbb+E_t%5BX%5E2%5D+-+%5Cmathbb+E_t%5BX%5E2%5D+%5C%5C+%26%3D+%5Cmathbb+E_t%5B+%28X+-+%5Cmathbb+E_t%5BX%5D%29%5E2+%5D+%5C%5C+%26%3D+%5Cmin_%7Bc+%5Cin+%5Cmathbb+R%7D+%5Cmathbb+E_t%5B+%28X+-+c%29%5E2+%5D+%5C%5C%26%5Cleq+%5Cmathbb+E_t%5Cleft%5B+%5Cleft%28X+-+%5Cfrac%7Ba%2Bb%7D%7B2%7D+%5Cright%29%5E2+%5Cright%5D+%5C%5C%26%5Cleq+%5Cmathbb+E_t%5Cleft%5B+%5Cleft%28b+-+%5Cfrac%7Ba%2Bb%7D%7B2%7D+%5Cright%29%5E2+%5Cright%5D+%5C%5C+%26%3D+%5Cfrac%7B%28b-a%29%5E2%7D%7B4%7D+%5Ccdot+%5Cunderbrace%7B+%5Cmathbb+E%5Bg_t%28X%29%5D+%7D_1+%3D+%5Cfrac%7B%28b-a%29%5E2%7D%7B4%7D.%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Now fix 


![\begin{aligned} \psi(\lambda) &= \psi(0) + \psi'(0) \lambda + \frac{\psi''(\eta)}{2} \cdot \lambda^2 \\ &\leq \log(1) + \mathbb E[X] \cdot \lambda + \frac{(b-a)^2}{4} \cdot \frac 12 \cdot \lambda^2 \\ &= 0 + 0 + \frac{\lambda^2 (b-a)^2}{8}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cpsi%28%5Clambda%29+%26%3D+%5Cpsi%280%29+%2B+%5Cpsi%27%280%29+%5Clambda+%2B+%5Cfrac%7B%5Cpsi%27%27%28%5Ceta%29%7D%7B2%7D+%5Ccdot+%5Clambda%5E2+%5C%5C+%26%5Cleq+%5Clog%281%29+%2B+%5Cmathbb+E%5BX%5D+%5Ccdot+%5Clambda+%2B+%5Cfrac%7B%28b-a%29%5E2%7D%7B4%7D+%5Ccdot+%5Cfrac+12+%5Ccdot+%5Clambda%5E2+%5C%5C+%26%3D+0+%2B+0+%2B+%5Cfrac%7B%5Clambda%5E2+%28b-a%29%5E2%7D%7B8%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Therefore, ![\mathbb E[\exp(\lambda X)] = \exp(\psi(\lambda)) \leq \exp(\lambda^2 (b-a)^2/8)](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%5Cexp%28%5Clambda+X%29%5D+%3D+%5Cexp%28%5Cpsi%28%5Clambda%29%29+%5Cleq+%5Cexp%28%5Clambda%5E2+%28b-a%29%5E2%2F8%29&bg=ffffff&fg=000&s=0&c=20201002)
Remark 2. In the case where ![\mathbb E[X] \neq 0](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BX%5D+%5Cneq+0&bg=ffffff&fg=000&s=0&c=20201002)
![(X - \mathbb E[X])](https://s0.wp.com/latex.php?latex=%28X+-+%5Cmathbb+E%5BX%5D%29&bg=ffffff&fg=000&s=0&c=20201002)
Example 2. Given a probability distribution
Proof. ![X - \mathbb E[X] \in [a - \mathbb E[X], b - \mathbb E[X]]](https://s0.wp.com/latex.php?latex=X+-+%5Cmathbb+E%5BX%5D+%5Cin+%5Ba+-+%5Cmathbb+E%5BX%5D%2C+b+-+%5Cmathbb+E%5BX%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![((b - \mathbb E[X]) - (a - \mathbb E[X]))/2 = (b-a)/2.](https://s0.wp.com/latex.php?latex=%28%28b+-+%5Cmathbb+E%5BX%5D%29+-+%28a+-+%5Cmathbb+E%5BX%5D%29%29%2F2+%3D+%28b-a%29%2F2.&bg=ffffff&fg=000&s=0&c=20201002)
Example 3. For any ![p \in [0, 1]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)

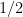
Proof. Given 
![X \in \{0, 1\} \subseteq [0, 1]](https://s0.wp.com/latex.php?latex=X+%5Cin+%5C%7B0%2C+1%5C%7D+%5Csubseteq+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)

Returning to Corollary 1, we notice that the exploration time
The next algorithm aims to do just that—the upper confidence bound (UCB) algorithm. We turn to this algorithm next time.
—Joel Kindiak, 10 Feb 26, 2229H

Leave a comment