Previously, we looked at the explore-then-commit algorithm, and asked how we can “automate” the optimisation between exploring and exploiting arms.
Lemma 1. Let 




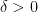

Proof. Since 

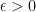

Setting the right-hand side equals 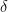


Therefore,

We want to use Lemma 1 to design our algorithm. What Lemma 1 communicates to us is that for small 

That is, with probability close to 

Let 



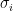

![\displaystyle \mathcal R_n(\pi, \nu) \leq \sum_{i=1}^n \mathbb E[T_i(n)] \cdot \Delta_i,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal+R_n%28%5Cpi%2C+%5Cnu%29+%5Cleq+%5Csum_%7Bi%3D1%7D%5En+%5Cmathbb+E%5BT_i%28n%29%5D+%5Ccdot+%5CDelta_i%2C&bg=ffffff&fg=000&s=0&c=20201002)
where 

- For any
, define
, where
independently.
- For any
.
Hence, given the number of pulls 


We shall design the UCB algorithm as follows. Pull each arm once, so that 




Lemma 2. For any event 
![\begin{aligned} \mathbb E[T_i(n)] &\leq \mathbb E[\mathbb E[T_i(n)] \mid G]] + n \cdot \mathbb P(G^c). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BT_i%28n%29%5D+%26%5Cleq+%5Cmathbb+E%5B%5Cmathbb+E%5BT_i%28n%29%5D+%5Cmid+G%5D%5D+%2B+n+%5Ccdot+%5Cmathbb+P%28G%5Ec%29.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Proof. By the law of total expectation, since 
![\begin{aligned} \mathbb E[T_i(n)] &\leq \mathbb E[\mathbb E[T_i(n)] \mid G] \cdot \underbrace{ \mathbb P(G) }_{\leq 1} + \mathbb E[ \underbrace{\mathbb E[T_i(n)]}_{\leq n} \mid G^c] \cdot \mathbb P(G^c) \\ &\leq \mathbb E[\mathbb E[T_i(n)] \mid G]] + n \cdot \mathbb P(G^c).\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BT_i%28n%29%5D+%26%5Cleq+%5Cmathbb+E%5B%5Cmathbb+E%5BT_i%28n%29%5D+%5Cmid+G%5D+%5Ccdot+%5Cunderbrace%7B+%5Cmathbb+P%28G%29+%7D_%7B%5Cleq+1%7D+%2B+%5Cmathbb+E%5B+%5Cunderbrace%7B%5Cmathbb+E%5BT_i%28n%29%5D%7D_%7B%5Cleq+n%7D+%5Cmid+G%5Ec%5D+%5Ccdot+%5Cmathbb+P%28G%5Ec%29+%5C%5C+%26%5Cleq+%5Cmathbb+E%5B%5Cmathbb+E%5BT_i%28n%29%5D+%5Cmid+G%5D%5D+%2B+n+%5Ccdot+%5Cmathbb+P%28G%5Ec%29.%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
For each 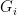
- For any
.
- We have
.
The first condition requires 
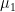
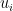


occurs. By Lemma 2,
![\begin{aligned} \mathbb E[T_i(n)] &\leq \mathbb E[\mathbb E[T_i(n)] \mid G_i]] + n \cdot \mathbb P(G_i^c).\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BT_i%28n%29%5D+%26%5Cleq+%5Cmathbb+E%5B%5Cmathbb+E%5BT_i%28n%29%5D+%5Cmid+G_i%5D%5D+%2B+n+%5Ccdot+%5Cmathbb+P%28G_i%5Ec%29.%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
It remains to upper-bound ![\mathbb E[T_i(n)]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BT_i%28n%29%5D+&bg=ffffff&fg=000&s=0&c=20201002)

Lemma 3. Under the good event 
Proof. Suppose 


By the definition of

a contradiction.
Lemma 4. There exists 


Proof. Taking the complement of

Taking a union bound,

We can upper-bound 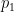

By taking a union bound and applying Lemma 1,

To upper-bound 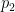

where the final inclusion is obtained by a choice of

Using the same tail concentration in Lemma 1,

Therefore,

Theorem 1. Given the horizon 

If furthermore that 

Proof. Combining Lemmas 3 and 4, there exists
![\displaystyle \mathbb E[T_i(n)] \leq u_i + n \left[ n\delta + \exp\left( -\frac{u_i c^2 \Delta_i^2}{2\sigma_i^2} \right)\right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5BT_i%28n%29%5D+%5Cleq+u_i+%2B+n+%5Cleft%5B+n%5Cdelta+%2B+%5Cexp%5Cleft%28+-%5Cfrac%7Bu_i+c%5E2+%5CDelta_i%5E2%7D%7B2%5Csigma_i%5E2%7D+%5Cright%29%5Cright%5D.&bg=ffffff&fg=000&s=0&c=20201002)
As per Lemma 4, we required

For the arms 

This lower bound allows us to upper-bound the exponential term as

Hence, we set

Therefore,
![\displaystyle \mathbb E[T_i(n)] \leq \frac{ 2 \sigma_i^2 \log(1/\delta) }{ (1-c)^2 \Delta_i^2 } + 1 + n^2 \delta + n\delta^{c^2/(1-c)^2}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5BT_i%28n%29%5D+%5Cleq+%5Cfrac%7B+2+%5Csigma_i%5E2+%5Clog%281%2F%5Cdelta%29+%7D%7B+%281-c%29%5E2+%5CDelta_i%5E2+%7D++%2B+1+%2B+n%5E2+%5Cdelta+%2B+n%5Cdelta%5E%7Bc%5E2%2F%281-c%29%5E2%7D.&bg=ffffff&fg=000&s=0&c=20201002)
For convenience, we choose 

![\displaystyle \mathbb E[T_i(n)] \leq \frac{ 8 \sigma_i^2 \log(1/\delta) }{ \Delta_i^2 } + 1 + n^2 \delta + n\delta.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5BT_i%28n%29%5D+%5Cleq+%5Cfrac%7B+8+%5Csigma_i%5E2+%5Clog%281%2F%5Cdelta%29+%7D%7B++%5CDelta_i%5E2+%7D++%2B+1+%2B+n%5E2+%5Cdelta+%2B+n%5Cdelta.&bg=ffffff&fg=000&s=0&c=20201002)
Setting 


Therefore,
My undergraduate research professor and his collaborators proved a generalised version for 

Theorem 2 (Tan et al, 2022). By modifying the UCB algorithm to account for general risk measures

where 


Proof. See Theorem 51 in the paper here. The technical portion of this proof is deriving a concentration bound analogous to that of Lemma 1, and the rest of the proof follows the same basic strategy in that of Theorem 1.
Though more convoluted due to the generality of

for the computable constant 
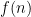
The next algorithm is a modification of the UCB algorithm and is the one closest to my heart—Thompson sampling. In the UCB algorithm, we compute our “optimism” of arm 


The idea for Thompson sampling is to randomise this process in a mathematically meaningful manner: Conditioned on the number of pulls 


![\rho(\tilde{\nu}_i) = \mathbb E[Y]](https://s0.wp.com/latex.php?latex=%5Crho%28%5Ctilde%7B%5Cnu%7D_i%29+%3D+%5Cmathbb+E%5BY%5D&bg=ffffff&fg=000&s=0&c=20201002)

My work aimed to solve this modified
We will explore this approach the next time, and also eventually address what we mean for an algorithm to be optimal.
—Joel Kindiak, 11 Feb 26, 1735H

Leave a comment