Let’s finally discuss Thompson sampling.
Previously, we looked at the UCB algorithm that incorporates the dynamic reward history into its exploration-exploitation tradeoff, yielding an upper-bound on its regret of the form

After an initial pull that yields the reward history 

where the expression being arg-maxxed is motivated by, given 

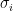

Thompson sampling aims to randomise this selection. To simplify our discussion, we will be given knowledge that each 


When we initialise the algorithm, we are completely ignorant of the distribution of any 





where 
The Thompson sampling algorithm then proceeds as follows. As an initial exploration phase, for each 


For each 

where 


where the various probability measures are still conditioned on the reward history, but omitted for brevity.
Our current discussion has brought us far too high into the stratosphere, and we need to return to earth. It stands to reason then that, in the absence of additional information, a meaningful “initial guess” would be

After pulling arm 



Lemma 1. Suppose for any 

Using conjugate priors,

In particular, if 

Proof. See Section 34.3 and Example 34.7 in Lattimore and Szepesvari (2020).
Therefore, we would use the 

with all relevant quantities defined in Lemma 1.
Remark 1. Observe that 




Remark 2. If all we know is that 

to form the randomised distribution 


similar in spirit to Lemma 1. Denoting

we sampled 



Now we ask the crucial question: given 

![\displaystyle \mathcal R_n(\rho\text{-}\mathrm{TS},\nu) = \sum_{i : \Delta_i^{\rho} > 0} \mathbb E[T_i(n)] \Delta_i^{\rho}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal+R_n%28%5Crho%5Ctext%7B-%7D%5Cmathrm%7BTS%7D%2C%5Cnu%29+%3D+%5Csum_%7Bi+%3A+%5CDelta_i%5E%7B%5Crho%7D+%3E+0%7D+%5Cmathbb+E%5BT_i%28n%29%5D+%5CDelta_i%5E%7B%5Crho%7D&bg=ffffff&fg=000&s=0&c=20201002)
My attempt at solving this problem for the risk functional 

Remark 3. There are many other distributions that ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
Lemma 2. Assume that arm 
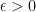

and 
independently,
,
,
).
Then
![\displaystyle \mathbb E[T_i(n)] \leq \mathbb E\left[ \sum_{s=0}^{n-1} \left( \frac 1{G_{1,s}} - 1 \right) \right] + \mathbb E\left[ \sum_{s=0}^{n-1} \mathbb I\{ G_{i,s} > 1/n \} \right] + 1.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5BT_i%28n%29%5D+%5Cleq+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bs%3D0%7D%5E%7Bn-1%7D+%5Cleft%28+%5Cfrac+1%7BG_%7B1%2Cs%7D%7D+-+1+%5Cright%29+%5Cright%5D+%2B+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bs%3D0%7D%5E%7Bn-1%7D+%5Cmathbb+I%5C%7B+G_%7Bi%2Cs%7D+%3E+1%2Fn+%5C%7D+%5Cright%5D+%2B+1.&bg=ffffff&fg=000&s=0&c=20201002)
Hence, we remove the randomness of 
Proof. The result and proof are all a mild generalisation of Theorem 36.2 in Lattimore and Szepesvari (2020). By construction,

almost surely. Therefore, we now decompose ![\mathbb E[T_i(n)]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BT_i%28n%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\begin{aligned} \mathbb E[T_i(n)] &= \mathbb E\left[ \sum_{t=1}^n \mathbb I\{ A_t = i \} \right] \\ &= \underbrace{ \mathbb E\left[ \sum_{t=1}^n \mathbb I\{ A_t = i, E_{i,t} \} \right] }_{M_1} + \underbrace{ \mathbb E\left[ \sum_{t=1}^n \mathbb I\{ A_t = i, E_{i,t}^c \} \right] }_{M_2}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BT_i%28n%29%5D+%26%3D+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+I%5C%7B+A_t+%3D+i+%5C%7D+%5Cright%5D+%5C%5C+%26%3D+%5Cunderbrace%7B+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+I%5C%7B+A_t+%3D+i%2C+E_%7Bi%2Ct%7D+%5C%7D+%5Cright%5D+%7D_%7BM_1%7D+%2B+%5Cunderbrace%7B+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+I%5C%7B+A_t+%3D+i%2C+E_%7Bi%2Ct%7D%5Ec+%5C%7D+%5Cright%5D+%7D_%7BM_2%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
To upper-bound 

Using a union bound,
![\begin{aligned} \mathbb E\left[ \sum_{t=1}^n \mathbb I \{ A_t = i, E_{i,t}^c \} \right] &= \mathbb E\left[ \sum_{t \in \mathcal T} \mathbb I \{ A_t = i, E_{i,t}^c \} \right] + \mathbb E\left[ \sum_{t \notin \mathcal T} \mathbb I \{ A_t = i, E_{i,t}^c \} \right] \\ &\leq \underbrace{\mathbb E\left[ \sum_{t \in \mathcal T} \mathbb I \{ A_t = i \} \right] }_{M_{2,1}} + \underbrace{ \mathbb E\left[ \sum_{t \notin \mathcal T} \mathbb I \{ E_{i,t}^c \} \right] }_{M_{2,2}}.\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+I+%5C%7B+A_t+%3D+i%2C+E_%7Bi%2Ct%7D%5Ec+%5C%7D+%5Cright%5D+%26%3D+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt+%5Cin+%5Cmathcal+T%7D+%5Cmathbb+I+%5C%7B+A_t+%3D+i%2C+E_%7Bi%2Ct%7D%5Ec+%5C%7D+%5Cright%5D+%2B+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt+%5Cnotin+%5Cmathcal+T%7D+%5Cmathbb+I+%5C%7B+A_t+%3D+i%2C+E_%7Bi%2Ct%7D%5Ec+%5C%7D+%5Cright%5D+%5C%5C+%26%5Cleq+%5Cunderbrace%7B%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt+%5Cin+%5Cmathcal+T%7D+%5Cmathbb+I+%5C%7B+A_t+%3D+i+%5C%7D+%5Cright%5D+%7D_%7BM_%7B2%2C1%7D%7D+%2B+%5Cunderbrace%7B+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt+%5Cnotin+%5Cmathcal+T%7D+%5Cmathbb+I+%5C%7B+E_%7Bi%2Ct%7D%5Ec+%5C%7D+%5Cright%5D+%7D_%7BM_%7B2%2C2%7D%7D.%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Therefore, it suffices to upper-bound
![\mathbb E[T_i(n)] \leq M_1 + M_{2,1} + M_{2,2}.](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BT_i%28n%29%5D+%5Cleq+M_1+%2B+M_%7B2%2C1%7D+%2B+M_%7B2%2C2%7D.&bg=ffffff&fg=000&s=0&c=20201002)
To upper-bound 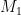


Then

since 



and conditional independence given

Therefore, we can upper-bound
![\begin{aligned} M_1 &= \mathbb E\left[ \sum_{t=1}^n \mathbb I\{ A_t = i, E_{i,t}\} \right] \\ &\leq \mathbb E \left[ \sum_{t=1}^n \mathbb P ( A_t = i, E_{i,t} \mid \mathcal F_{t-1})\right] \\ &\leq \mathbb E \left[ \sum_{t=1}^n \left( \frac{1}{G_{1,T_1(t-1)}} -1 \right) \cdot \mathbb P(A_t = 1 \mid \mathcal F_{t-1})\right] \\ &=\mathbb E \left[ \sum_{t=1}^n \left( \frac{1}{G_{1,T_1(t-1)}} -1 \right) \cdot \mathbb I \{ A_t = 1 \} \right] \\ &\leq \mathbb E \left[ \sum_{s=0}^{n-1} \left( \frac{1}{G_{1,s}} -1 \right) \right]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+M_1+%26%3D+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+I%5C%7B+A_t+%3D+i%2C+E_%7Bi%2Ct%7D%5C%7D+%5Cright%5D+%5C%5C+%26%5Cleq+%5Cmathbb+E+%5Cleft%5B+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+P+%28+A_t+%3D+i%2C+E_%7Bi%2Ct%7D++%5Cmid+%5Cmathcal+F_%7Bt-1%7D%29%5Cright%5D+%5C%5C+%26%5Cleq+%5Cmathbb+E+%5Cleft%5B+%5Csum_%7Bt%3D1%7D%5En++%5Cleft%28+%5Cfrac%7B1%7D%7BG_%7B1%2CT_1%28t-1%29%7D%7D+-1+%5Cright%29+%5Ccdot+%5Cmathbb+P%28A_t+%3D+1+%5Cmid+%5Cmathcal+F_%7Bt-1%7D%29%5Cright%5D+%5C%5C+%26%3D%5Cmathbb+E+%5Cleft%5B+%5Csum_%7Bt%3D1%7D%5En++%5Cleft%28+%5Cfrac%7B1%7D%7BG_%7B1%2CT_1%28t-1%29%7D%7D+-1+%5Cright%29+%5Ccdot+%5Cmathbb+I+%5C%7B+A_t+%3D+1+%5C%7D+%5Cright%5D+%5C%5C+%26%5Cleq+%5Cmathbb+E+%5Cleft%5B+%5Csum_%7Bs%3D0%7D%5E%7Bn-1%7D++%5Cleft%28+%5Cfrac%7B1%7D%7BG_%7B1%2Cs%7D%7D+-1+%5Cright%29+%5Cright%5D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
To upper-bound 

Therefore,

Taking expectations,
![\begin{aligned} M_{2,1} = \mathbb E\left[ \sum_{t \in \mathcal T} \mathbb I\{ A_t = i \} \right] &\leq \mathbb E\left[ \sum_{s=0}^{n-1} \mathbb I\{ G_{i,s} > 1/n \} \right]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+M_%7B2%2C1%7D+%3D+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt+%5Cin+%5Cmathcal+T%7D+%5Cmathbb+I%5C%7B+A_t+%3D+i+%5C%7D+%5Cright%5D+%26%5Cleq+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bs%3D0%7D%5E%7Bn-1%7D+%5Cmathbb+I%5C%7B+G_%7Bi%2Cs%7D+%3E+1%2Fn+%5C%7D+%5Cright%5D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
To upper-bound 


![\begin{aligned} M_{2,2} &= \mathbb E\left[ \sum_{t \notin \mathcal T} \mathbb I\{E_{i,t}^c\} \right] \\ &= \sum_{t=1}^n \mathbb E[ \mathbb I\{E_{i,t}^c, G_{i, T_i(t-1)} \leq 1/n\} ] \\ &= \sum_{t=1}^n \mathbb E[ \mathbb E[\mathbb I\{E_{i,t}^c, G_{i, T_i(t-1)} \leq 1/n\}\mid \mathcal F_{t-1}] ] \\ &= \sum_{t=1}^n \mathbb E[ \mathbb I\{ G_{i, T_i(t-1)} \leq 1/n \}] \cdot \mathbb P(E_{i,t}^c) ] \\ &= \sum_{t=1}^n \mathbb E[ \mathbb I\{ G_{i, T_i(t-1)} \leq 1/n \}] \cdot G_{i,T_i(t-1)} ] \\ &\leq \sum_{t=1}^n \mathbb E[ \mathbb I\{ G_{i, T_i(t-1)} \leq 1/n \}] \cdot 1/n ] \\ &= \sum_{t=1}^n \mathbb P(G_{i, T_i(t-1)} \leq 1/n ) \cdot 1/n \\ &\leq \sum_{t=1}^n 1 \cdot 1/n = 1. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+M_%7B2%2C2%7D+%26%3D+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bt+%5Cnotin+%5Cmathcal+T%7D+%5Cmathbb+I%5C%7BE_%7Bi%2Ct%7D%5Ec%5C%7D+%5Cright%5D+%5C%5C+%26%3D+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+E%5B+%5Cmathbb+I%5C%7BE_%7Bi%2Ct%7D%5Ec%2C+G_%7Bi%2C+T_i%28t-1%29%7D+%5Cleq+1%2Fn%5C%7D+%5D+%5C%5C+%26%3D+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+E%5B+%5Cmathbb+E%5B%5Cmathbb+I%5C%7BE_%7Bi%2Ct%7D%5Ec%2C+G_%7Bi%2C+T_i%28t-1%29%7D+%5Cleq+1%2Fn%5C%7D%5Cmid++%5Cmathcal+F_%7Bt-1%7D%5D++%5D+%5C%5C+%26%3D+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+E%5B+%5Cmathbb+I%5C%7B+G_%7Bi%2C+T_i%28t-1%29%7D+%5Cleq+1%2Fn+%5C%7D%5D+%5Ccdot+%5Cmathbb+P%28E_%7Bi%2Ct%7D%5Ec%29++%5D+%5C%5C+%26%3D+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+E%5B+%5Cmathbb+I%5C%7B+G_%7Bi%2C+T_i%28t-1%29%7D+%5Cleq+1%2Fn+%5C%7D%5D+%5Ccdot+G_%7Bi%2CT_i%28t-1%29%7D+%5D+%5C%5C+%26%5Cleq+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+E%5B+%5Cmathbb+I%5C%7B+G_%7Bi%2C+T_i%28t-1%29%7D+%5Cleq+1%2Fn+%5C%7D%5D+%5Ccdot+1%2Fn+%5D+%5C%5C+%26%3D+%5Csum_%7Bt%3D1%7D%5En+%5Cmathbb+P%28G_%7Bi%2C+T_i%28t-1%29%7D+%5Cleq+1%2Fn+%29+%5Ccdot+1%2Fn++%5C%5C+%26%5Cleq+%5Csum_%7Bt%3D1%7D%5En+1+%5Ccdot+1%2Fn+%3D+1.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Therefore,
![\begin{aligned} \mathbb E[T_i(n)] &\leq M_1 + M_{2,1} + M_{2,2} \\ &\leq \mathbb E\left[ \sum_{s=0}^{n-1} \left(\frac 1{G_{1,s}} - 1 \right) \right] + \mathbb E\left[ \sum_{s=1}^n \mathbb I\{G_{i,s-1} > 1/n\} \right] + 1. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5BT_i%28n%29%5D+%26%5Cleq+M_1+%2B+M_%7B2%2C1%7D+%2B+M_%7B2%2C2%7D+%5C%5C+%26%5Cleq+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bs%3D0%7D%5E%7Bn-1%7D+%5Cleft%28%5Cfrac+1%7BG_%7B1%2Cs%7D%7D+-+1+%5Cright%29+%5Cright%5D+%2B+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bs%3D1%7D%5En+%5Cmathbb+I%5C%7BG_%7Bi%2Cs-1%7D+%3E+1%2Fn%5C%7D+%5Cright%5D+%2B+1.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Lemma 2 gives us the general recipe to evaluate the regret bound for 



How do we upper-bound the cumulative regret 
Fix
![\displaystyle \mathbb E[T_i(n)] \leq \underbrace{ \mathbb E\left[ \sum_{s=0}^{n-1} \left( \frac 1{G_{1,s}} - 1 \right) \right] }_{C_1(n,\epsilon)} + \underbrace{ \mathbb E\left[ \sum_{s=0}^{n-1} \mathbb I\{ G_{i,s} > 1/n \} \right] }_{C_2(n,\epsilon)} + 1,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5BT_i%28n%29%5D+%5Cleq+%5Cunderbrace%7B+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bs%3D0%7D%5E%7Bn-1%7D+%5Cleft%28+%5Cfrac+1%7BG_%7B1%2Cs%7D%7D+-+1+%5Cright%29+%5Cright%5D+%7D_%7BC_1%28n%2C%5Cepsilon%29%7D+%2B+%5Cunderbrace%7B+%5Cmathbb+E%5Cleft%5B+%5Csum_%7Bs%3D0%7D%5E%7Bn-1%7D+%5Cmathbb+I%5C%7B+G_%7Bi%2Cs%7D+%3E+1%2Fn+%5C%7D+%5Cright%5D+%7D_%7BC_2%28n%2C%5Cepsilon%29%7D+%2B+1%2C&bg=ffffff&fg=000&s=0&c=20201002)
where 

where 
We aim to upper-bound 


Lemma 3. 
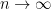
Proof. To upper-bound
![\displaystyle C_1(n,\epsilon) = \sum_{s=0}^{n-1} \mathbb E\left[ \frac{1}{ G_{1,s} } - 1 \right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+C_1%28n%2C%5Cepsilon%29+%3D+%5Csum_%7Bs%3D0%7D%5E%7Bn-1%7D+%5Cmathbb+E%5Cleft%5B+%5Cfrac%7B1%7D%7B+G_%7B1%2Cs%7D+%7D+-+1+%5Cright%5D.&bg=ffffff&fg=000&s=0&c=20201002)
The key idea is to note that the value of

is deterministic when conditioned on 

and the distribution of 

Therefore, we can let 


and 

Conditioned on 

so that

almost surely. Therefore, by taking advantage of the marginal distribution and using the change of variables 
![\begin{aligned}\mathbb E\left[ \frac{1}{ G_{1,s} } - 1 \right] &= \int_{\mathbb R} \left( \frac 1{1-F( \mu_1 - y - \epsilon)} - 1 \right) f(\mu_1-y)\, \mathrm dy \\ &= \int_{\mathbb R} \left( \frac 1{1-F( y )} - 1 \right) f(y + \epsilon )\, \mathrm dy \\ &= \int_{\mathbb R} \frac {F(y)}{1 - F(y)} \cdot f( y + \epsilon)\, \mathrm dy \\ &= \left( \int_{-\infty}^0 + \int_0^\infty \right) \frac {F(y)}{1 - F(y)} \cdot f( y + \epsilon)\, \mathrm dy. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cmathbb+E%5Cleft%5B+%5Cfrac%7B1%7D%7B+G_%7B1%2Cs%7D+%7D+-+1+%5Cright%5D+%26%3D+%5Cint_%7B%5Cmathbb+R%7D+%5Cleft%28+%5Cfrac+1%7B1-F%28+%5Cmu_1+-+y+-+%5Cepsilon%29%7D+-+1+%5Cright%29+f%28%5Cmu_1-y%29%5C%2C+%5Cmathrm+dy+%5C%5C++%26%3D+%5Cint_%7B%5Cmathbb+R%7D+%5Cleft%28+%5Cfrac+1%7B1-F%28+y+%29%7D+-+1+%5Cright%29+f%28y+%2B+%5Cepsilon+%29%5C%2C+%5Cmathrm+dy+%5C%5C+%26%3D+%5Cint_%7B%5Cmathbb+R%7D+%5Cfrac+%7BF%28y%29%7D%7B1+-+F%28y%29%7D+%5Ccdot+f%28+y+%2B+%5Cepsilon%29%5C%2C+%5Cmathrm+dy+%5C%5C+%26%3D+%5Cleft%28+%5Cint_%7B-%5Cinfty%7D%5E0+%2B+%5Cint_0%5E%5Cinfty+%5Cright%29+%5Cfrac+%7BF%28y%29%7D%7B1+-+F%28y%29%7D+%5Ccdot+f%28+y+%2B+%5Cepsilon%29%5C%2C+%5Cmathrm+dy.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Therefore, we need to upper-bound two integrals. For the first integral, 


we have

For the second integral, 

followed by algebra and integration by parts,

Combining both results,
![\begin{aligned} C_1(n,\epsilon) &= \sum_{s=0}^{n-1} \mathbb E\left[ \frac 1{G_{1,s}} - 1 \right] \\ &\leq 1 + 2 \cdot \sum_{s=1}^{\infty} \left( \exp(-s\epsilon^2/2) + \frac{1+\epsilon \sqrt{s}}{\epsilon s\sqrt{2\pi}} \cdot \exp(-s\epsilon^2/2) \right) \\ &\leq 1 + 2 \cdot \left(1 + \frac{1+\epsilon }{\epsilon \sqrt{2\pi}}\right) \cdot \sum_{s=0}^{\infty} \exp(-s\epsilon^2/2) \\ &\leq 1 + 2 \cdot \left(1 + \frac{1+\epsilon }{\epsilon \sqrt{2\pi}}\right) \cdot \frac{1}{1 - \exp(-\epsilon^2/2)}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+C_1%28n%2C%5Cepsilon%29+%26%3D+%5Csum_%7Bs%3D0%7D%5E%7Bn-1%7D+%5Cmathbb+E%5Cleft%5B+%5Cfrac+1%7BG_%7B1%2Cs%7D%7D+-+1+%5Cright%5D+%5C%5C+%26%5Cleq+1+%2B+2+%5Ccdot+%5Csum_%7Bs%3D1%7D%5E%7B%5Cinfty%7D+%5Cleft%28+%5Cexp%28-s%5Cepsilon%5E2%2F2%29+%2B+%5Cfrac%7B1%2B%5Cepsilon+%5Csqrt%7Bs%7D%7D%7B%5Cepsilon+s%5Csqrt%7B2%5Cpi%7D%7D+%5Ccdot+%5Cexp%28-s%5Cepsilon%5E2%2F2%29+%5Cright%29+%5C%5C+%26%5Cleq+1+%2B+2+%5Ccdot+%5Cleft%281+%2B+%5Cfrac%7B1%2B%5Cepsilon+%7D%7B%5Cepsilon+%5Csqrt%7B2%5Cpi%7D%7D%5Cright%29+%5Ccdot+%5Csum_%7Bs%3D0%7D%5E%7B%5Cinfty%7D+%5Cexp%28-s%5Cepsilon%5E2%2F2%29+%5C%5C+%26%5Cleq+1+%2B+2+%5Ccdot+%5Cleft%281+%2B+%5Cfrac%7B1%2B%5Cepsilon+%7D%7B%5Cepsilon+%5Csqrt%7B2%5Cpi%7D%7D%5Cright%29+%5Ccdot+%5Cfrac%7B1%7D%7B1+-+%5Cexp%28-%5Cepsilon%5E2%2F2%29%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
In particular,
Remark 4. In the general setting, we would also aim to prove that 


and the intermediate dependency has a relatively characterisable distribution conditioned on the reward history. More generally, at any time

where 
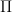

,
,
,
,
.
If we adopt the same strategy as in Lemma 3, then we would like 



![\begin{aligned} \mathbb E\left[ \frac 1{G_{1,s}} - 1 \right] &= \int_{\Omega} \frac{1 - G_{1,s}(\omega)}{G_{1,s}(\omega)} f(\omega)\, \mathrm d\mu(\omega). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5Cleft%5B+%5Cfrac+1%7BG_%7B1%2Cs%7D%7D+-+1+%5Cright%5D+%26%3D+%5Cint_%7B%5COmega%7D+%5Cfrac%7B1+-+G_%7B1%2Cs%7D%28%5Comega%29%7D%7BG_%7B1%2Cs%7D%28%5Comega%29%7D+f%28%5Comega%29%5C%2C+%5Cmathrm+d%5Cmu%28%5Comega%29.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Hence, we would require tail lower bounds on 

for non-negative functions 

and

so that
![\begin{aligned} \mathbb E\left[ \frac 1{G_{1,s}} - 1 \right] &= \left( \int_{\Omega_1} + \int_{\Omega_2}\right) \frac{1 - G_{1,s}(\omega)}{G_{1,s}(\omega)} f(\omega)\, \mathrm d\mu(\omega) \\ &\leq \psi_1(s,\epsilon) + \psi_2(s,\epsilon), \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cmathbb+E%5Cleft%5B+%5Cfrac+1%7BG_%7B1%2Cs%7D%7D+-+1+%5Cright%5D+%26%3D+%5Cleft%28+%5Cint_%7B%5COmega_1%7D+%2B+%5Cint_%7B%5COmega_2%7D%5Cright%29+%5Cfrac%7B1+-+G_%7B1%2Cs%7D%28%5Comega%29%7D%7BG_%7B1%2Cs%7D%28%5Comega%29%7D+f%28%5Comega%29%5C%2C+%5Cmathrm+d%5Cmu%28%5Comega%29+%5C%5C+%26%5Cleq+%5Cpsi_1%28s%2C%5Cepsilon%29+%2B+%5Cpsi_2%28s%2C%5Cepsilon%29%2C+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
and 

where we are reminded that

Lemma 4. 
Proof. To upper-bound

Define 

Using the Gaussian tail bound again,

where the last line follows from the proof of Theorem 8.1 in Lattimore and Szepesvari (2020). In particular,

Remark 5. For the general case, we would like to obtain a concentration bound of the form

where 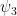




In particular, setting

yields

so that 
Theorem 1. Given that 

Proof. Combining the displays in Lemmas 2, 3 and 4,
![\begin{aligned} \limsup_{n \to \infty} \frac{\mathbb E[T_i(n)]}{\log(n)} &\leq \lim_{n \to \infty} \frac{C_1(n,\epsilon) + C_2(n,\epsilon) + 1}{\log(n)} \\ &\leq \lim_{n \to \infty} \frac{C_1(n,\epsilon) }{\log(n)} + \lim_{n \to \infty} \frac{C_2(n,\epsilon) }{\log(n)} + \lim_{n \to \infty} \frac{1 }{\log(n)} \\ &= 0 + \frac {2}{(\Delta_i - \epsilon)^2} + 0 = \frac {2}{(\Delta_i - \epsilon)^2} . \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Climsup_%7Bn+%5Cto+%5Cinfty%7D+%5Cfrac%7B%5Cmathbb+E%5BT_i%28n%29%5D%7D%7B%5Clog%28n%29%7D+%26%5Cleq+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cfrac%7BC_1%28n%2C%5Cepsilon%29+%2B+C_2%28n%2C%5Cepsilon%29+%2B+1%7D%7B%5Clog%28n%29%7D+%5C%5C+%26%5Cleq+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cfrac%7BC_1%28n%2C%5Cepsilon%29+%7D%7B%5Clog%28n%29%7D+%2B+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cfrac%7BC_2%28n%2C%5Cepsilon%29+%7D%7B%5Clog%28n%29%7D+%2B+%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Cfrac%7B1+%7D%7B%5Clog%28n%29%7D+%5C%5C+%26%3D+0+%2B+%5Cfrac+%7B2%7D%7B%28%5CDelta_i+-+%5Cepsilon%29%5E2%7D+%2B+0+%3D+%5Cfrac+%7B2%7D%7B%28%5CDelta_i+-+%5Cepsilon%29%5E2%7D+.+%5Cend%7Baligned%7D&bg=ffffff&fg=000&s=0&c=20201002)
Plugging into the regret decomposition,

Taking

Remark 6. Assuming the presence of sufficiently nice concentration bounds in Remarks 4 and 5, we can recover the generalised regret bound

Taking

That was…intense. I took at least six hours to type this out. And several more days to include the generalising remarks. And this was supposedly the warm-up for my undergraduate research projects. I have to say…I probably would have progressed much further if I took the time then to write this proof out as I did today.
Before we can finally lay our short detour into multi-armed bandits, we must ask the question: is this Thompson sampling algorithm, in a sense, the best? We will answer this question in the affirmative next time.
—Joel Kindiak, 13 Feb 26, 2117H

Leave a comment