Previously, we have looked at three proposed solutions for the 




We will assume this stricter condition, since Gaussian distributions with variance 

The ETC strategy, though simple, is a bit too simplistic. Disregarding the fact that our exploration phase 



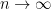

Round 1: UCB wins against ETC.
Where does Thompson sampling come into the picture? Let’s compare their regret bounds:

Trivially, 
Round 2: Thompson sampling wins against UCB.
Remark 1. The reality is, however, a lot more subtle. It turns out that a clever choice of 
But here’s the problem—how do we know that Thompson sampling or the modified UCB in Remark 1 are really the best algorithms for a bandit instance of Gaussians with variance
Denote 

Let 
Definition 1. A policy (i.e. bandit algorithm) is 



In particular, UCB and TS are 




For any policy consistent over the

it turns out that we have a very elegant regret lower bound, that even extends to the generalised risk setting. To describe this lower-bound, however, requires us to explore some baby information theory, and in particular, the Kullback-Leibler divergence.
Definition 2 (KL-Divergence). Let 




![\displaystyle \mathrm{KL}(\nu, \kappa) := \int_{\Omega} \frac{\mathrm d\nu}{\mathrm d\lambda} \cdot \log \left( \frac{\mathrm d\nu}{\mathrm d\kappa} \right)\, \mathrm d\lambda = \mathbb E_{\nu}\left[\log\left( \frac{\mathrm d\nu}{\mathrm d\kappa} \right)\right],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathrm%7BKL%7D%28%5Cnu%2C+%5Ckappa%29+%3A%3D+%5Cint_%7B%5COmega%7D+%5Cfrac%7B%5Cmathrm+d%5Cnu%7D%7B%5Cmathrm+d%5Clambda%7D++%5Ccdot+%5Clog+%5Cleft%28+%5Cfrac%7B%5Cmathrm+d%5Cnu%7D%7B%5Cmathrm+d%5Ckappa%7D+%5Cright%29%5C%2C+%5Cmathrm+d%5Clambda+%3D+%5Cmathbb+E_%7B%5Cnu%7D%5Cleft%5B%5Clog%5Cleft%28+%5Cfrac%7B%5Cmathrm+d%5Cnu%7D%7B%5Cmathrm+d%5Ckappa%7D+%5Cright%29%5Cright%5D%2C&bg=ffffff&fg=000&s=0&c=20201002)
where ![\displaystyle \mathbb E_{\nu}[g(X)] \equiv \int_{\mathbb R} g(x)\, \mathrm d \nu(x)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E_%7B%5Cnu%7D%5Bg%28X%29%5D+%5Cequiv+%5Cint_%7B%5Cmathbb+R%7D+g%28x%29%5C%2C+%5Cmathrm+d+%5Cnu%28x%29&bg=ffffff&fg=000&s=0&c=20201002)
Example 1. Given the Gaussian distributions 

In the special case 

Furthermore, if 

Proof. See this page.
Definition 3. Fix 

Now let 
Example 2. For 

where 
Proof. By definition,

By Example 1, given 



Taking 

Why do we care about the optimised KL-divergence? Because it plays a fundamental role in (asymptotically) lower-bounding the cumulative regret!
Theorem 1. Let 

Then for any

Proof. We follow the proof of Theorem 16.2 in Lattimore and Szepesvari (2020). Denote the bandit instance by 
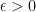




Define the alternate bandit instance 

for a suitably chosen ![\mathbb E[T_i(n)] \geq 1/(K_i + \epsilon)](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5BT_i%28n%29%5D+%5Cgeq+1%2F%28K_i+%2B+%5Cepsilon%29&bg=ffffff&fg=000&s=0&c=20201002)
![\mathrm{KL}(\mathbb P_{\nu}, \mathbb P_{\nu'}) = \mathbb E[T_i(n)] \cdot \mathrm{KL}(\nu_i, \nu_i'),](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BKL%7D%28%5Cmathbb+P_%7B%5Cnu%7D%2C+%5Cmathbb+P_%7B%5Cnu%27%7D%29+%3D+%5Cmathbb+E%5BT_i%28n%29%5D+%5Ccdot+%5Cmathrm%7BKL%7D%28%5Cnu_i%2C+%5Cnu_i%27%29%2C&bg=ffffff&fg=000&s=0&c=20201002)
which implies that
![\displaystyle \mathbb E[T_i(n)] > \frac{ \mathrm{KL}(\mathbb P_{\nu}, \mathbb P_{\nu'}) }{ K_i + \epsilon }.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb+E%5BT_i%28n%29%5D+%3E+%5Cfrac%7B+%5Cmathrm%7BKL%7D%28%5Cmathbb+P_%7B%5Cnu%7D%2C+%5Cmathbb+P_%7B%5Cnu%27%7D%29+%7D%7B+K_i+%2B+%5Cepsilon+%7D.&bg=ffffff&fg=000&s=0&c=20201002)
Denote 

![\displaystyle R_n + R_n' \geq \frac n4 \cdot \min \{ \Delta_i^\rho, \rho(\nu_i') - \rho(\nu_1)\} \cdot \exp(- \mathbb E[T_i(n)] \cdot (K_i +\epsilon)).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+R_n+%2B+R_n%27+%5Cgeq+%5Cfrac+n4+%5Ccdot+%5Cmin+%5C%7B+%5CDelta_i%5E%5Crho%2C+%5Crho%28%5Cnu_i%27%29+-+%5Crho%28%5Cnu_1%29%5C%7D+%5Ccdot+%5Cexp%28-+%5Cmathbb+E%5BT_i%28n%29%5D+%5Ccdot+%28K_i+%2B%5Cepsilon%29%29.&bg=ffffff&fg=000&s=0&c=20201002)
Performing algebra,
![\displaystyle \frac{ \mathbb E[T_i(n)] }{ \log(n) } \geq \frac 1{K_i +\epsilon} \cdot \left(1 - \frac{ \log\left( \frac{ 4 \cdot (R_n + R_n') }{ \min \{ \Delta_i^\rho, \rho(\nu_i') - \rho(\nu_1)\} } \right) }{ \log(n) } \right).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B+%5Cmathbb+E%5BT_i%28n%29%5D+%7D%7B+%5Clog%28n%29+%7D+%5Cgeq+%5Cfrac+1%7BK_i+%2B%5Cepsilon%7D+%5Ccdot+%5Cleft%281+-+%5Cfrac%7B+%5Clog%5Cleft%28+%5Cfrac%7B+4+%5Ccdot+%28R_n+%2B+R_n%27%29+%7D%7B+%5Cmin+%5C%7B+%5CDelta_i%5E%5Crho%2C+%5Crho%28%5Cnu_i%27%29+-+%5Crho%28%5Cnu_1%29%5C%7D++%7D+%5Cright%29+%7D%7B+%5Clog%28n%29+%7D+%5Cright%29.&bg=ffffff&fg=000&s=0&c=20201002)
Since 


![\displaystyle \liminf_{n \to \infty} \frac{ \mathcal R_n^{\rho}(\pi, \nu) }{ \log(n) } = \sum_{i : \Delta_i^{\rho}} \frac {\mathbb E[T_i(n)]}{\log(n)} \cdot \Delta_i^{\rho} \geq \sum_{i : \Delta_i^{\rho}} \frac 1{K_i +\epsilon} \cdot \Delta_i^{\rho}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Climinf_%7Bn+%5Cto+%5Cinfty%7D+%5Cfrac%7B+%5Cmathcal+R_n%5E%7B%5Crho%7D%28%5Cpi%2C+%5Cnu%29+%7D%7B+%5Clog%28n%29+%7D+%3D+%5Csum_%7Bi+%3A+%5CDelta_i%5E%7B%5Crho%7D%7D+%5Cfrac+%7B%5Cmathbb+E%5BT_i%28n%29%5D%7D%7B%5Clog%28n%29%7D+%5Ccdot+%5CDelta_i%5E%7B%5Crho%7D+%5Cgeq+%5Csum_%7Bi+%3A+%5CDelta_i%5E%7B%5Crho%7D%7D+%5Cfrac+1%7BK_i+%2B%5Cepsilon%7D+%5Ccdot+%5CDelta_i%5E%7B%5Crho%7D.&bg=ffffff&fg=000&s=0&c=20201002)
Taking
Example 3. For any policy 

Definition 4. Using the notation in Theorem 1, we say that

Corollary 1. Thompson sampling is asymptotically optimal over 
Proof. By previous discussions,

so that Thompson sampling is

By Definition 4, Thompson sampling is asymptotically optimal over

In that sense, Thompson sampling is the ultimate winner! And of course, the modified UCB that achieves the same regret bound is also the ultimate winner over
And the discussion is far from over. Denoting ![\mathrm{Ber} \equiv \{\mathrm{Ber}(p) : p \in [0, 1]\}](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BBer%7D+%5Cequiv+%5C%7B%5Cmathrm%7BBer%7D%28p%29+%3A+p+%5Cin+%5B0%2C+1%5D%5C%7D&bg=ffffff&fg=000&s=0&c=20201002)

- Expectation:
,
- Variance:
,
- Conditional value-at-risk:
,
- Mean-variance:
,
- Entropic risk:
,
.
Denoting the collection of probability distributions with support bounded in ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\mathcal M_{[0,1]}](https://s0.wp.com/latex.php?latex=%5Cmathcal+M_%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\mathcal M_{[0,1]}^K](https://s0.wp.com/latex.php?latex=%5Cmathcal+M_%7B%5B0%2C1%5D%7D%5EK&bg=ffffff&fg=000&s=0&c=20201002)

, i.e. the collection of
, i.e. the collection of
, i.e. the collection of
I honestly don’t know, and don’t have enough funding in time or money to find out. But I have to say that the nostalgia of revisiting this topic four years later brought me a much-needed closure from those research years.
For now, we are done.
Happy Valentine’s Day!
Remark 2. As of 9 June 2026, the task has been answered in the affirmative, namely for ![\mathcal C_{[0,1]}](https://s0.wp.com/latex.php?latex=%5Cmathcal+C_%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000&s=0&c=20201002)


—Joel Kindiak, 14 Feb 26, 1602H

Leave a comment