Let’s drink some milk tea! Consider the three milk tea chains in Singapore: Chagee, Koi, and LiHo. (There are many others, so please experiment with these other chains if you wish.)

Let 

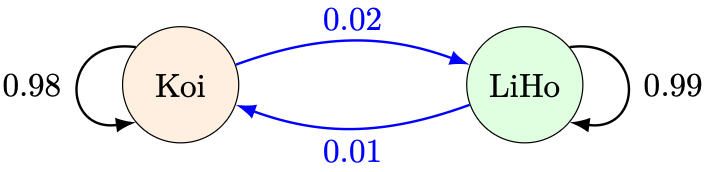
Before Chagee came on the scene, the milk tea scene was mostly split between Koi and LiHo, so that 


- 2% of Koi drinkers switch to LiHo,
- 1% of LiHo drinkers switch to Koi.
Example 1. At the end of the first month, what proportion of the population would be Koi drinkers?
Solution. We can represent these changes using the following diagram. Arrows once again represent similar ideas as they do in probability tree diagrams: the arrow from Koi to LiHo with label 0.02 means that 0.02 of Koi drinkers switch to LiHo.
Recall that 


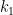
- the 98% of Koi customers who remained loyal to Koi,
- the 1% of LiHo customers who switched to Koi.
Therefore,

Similarly,

Since 

Indeed, Koi lost a small amount of its market share, as predicted.
Now suppose the proportion of drinkers as per Example 1. For reasons that will become apparent later, let’s denote the market shares as vectors:

Due to aggressive social media marketing by Chagee’s youthful team, suppose at the end of every month, the following changes happen after each month:
- 4% of Koi drinkers switch to Chagee,
- 3% of LiHo drinkers switch to Chagee.
- All Chagee drinkers keep drinking Chagee.
Question 1. At the end of the second month, what proportion of the population would be Chagee drinkers?
We can represent these changes using the following diagram, now including Chagee in our calculations.
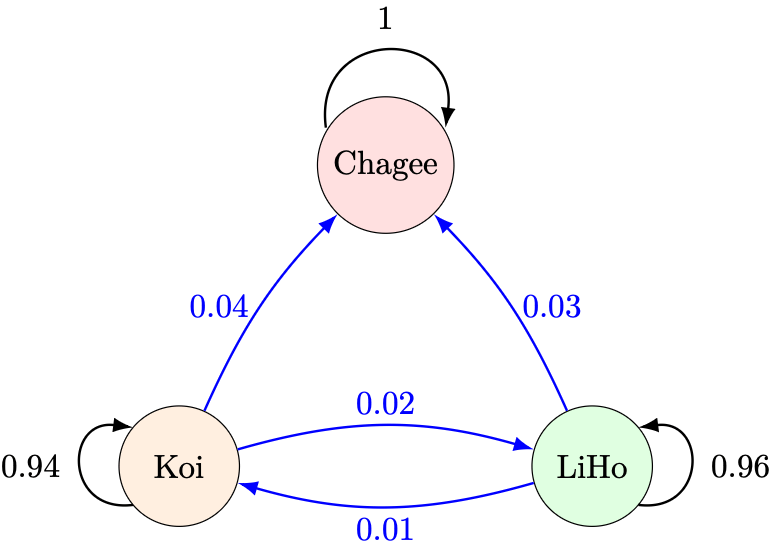
Using similar analysis to Example 1, we write out the following three equations:

Use vector notation to simplify our work:

At this point in time, all we need to do is to substitute 


Remark 1. The setups we gave are specific kinds of Markov chains and more generally, stochastic processes, an model of describing sequences of random variables that satisfy sufficiently nice probability properties.
We can think of the three vectors as the “ingredients” needed that produce our result, while the numbers

This is, in fact, the essential origin-story of the matrix. It wasn’t a-priori defined as a table of numbers equipped with some out-of-the-blue calculations; it was simply a summary of changing data!
Remark 2. Notice that the notion of a 3-dimensional vector just arose from our problem setup. In the physical world, we can still visualise 3 dimensions, but more complicated setups would require the use of 

Definition 1. An 




An 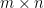

For example, we have the following 

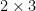


Furthermore, given an 


Define the zero matrix by 
Example 2. Evaluate the expression

giving your answer in terms of a 2-dimensional vector.
Solution. Using Definition 1,

Remark 2. The expression in Example 2, being contrived, doesn’t represent any particular real-world example. However, its calculations are identical to that of the milk tea example (which is, itself, not entirely faithful to reality, but simplified for analogous purposes).
Example 3. Given an 

Solution. Write

where each 
If we could add vectors, could we add matrices? The real question is, why not? Consider the two expressions below:

Let’s expand both terms using the recipe-ingredient analogy:

Now let’s add both sides of the equation together:

where we consolidated our calculations using the recipe-ingredient analogy again. Therefore, it is reasonable to define

so that for any 3-dimensional vector 

A similar thought process works for multiplying a matrix by a number (i.e. scalar multiplication) and matrix subtraction.
Definition 2. Let 


so that for any 
Similarly, given any real number 

so that for any 
In particular, define 

Example 4. Show that 
Solution. By Definition 2 and its implications,

Example 5. Evaluate the following expressions:

Solution. Using Definition 2,

Theorem 1. Given 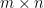


,
,
,
,
,
,
,
.
Proof. Left as a tedious (but ultimately meaningful) exercise.
How might we multiply two matrices together? Consider the expression

Using the ingredient-recipe analogy, the matrix on the right-hand side has two recipes, not one. Therefore, we can think of the expression as cooking two dishes; this is our definition of matrix multiplication:

And we know how to compute the “dishes” 

Example 6. Given an 
Solution. Write

By definition,

In order for each 



Example 7. Evaluate the expression

Solution. Applying Definition 1 to each column,

Combining the results,

Example 8. Given 

Solution. By definition,

Applying Definition 1 to each column,

Combining the results,

Example 9. Show that

where for any 

Solution. By the ingredient-recipe analogy, the 

Expanding the left-hand side,

Therefore,

In particular, by comparing the 

Remark 3. Example 9 is the conventional definition of matrix multiplication, which I have avoided to define a priori since it seems contrived and miscellaneous, rather than the current presentation which shows how matrix multiplication is a necessary consequence of the information-preserving properties that we aimed to achieve.
And that’s all for matrices! Matrices, at the O-level is simply a tool to summarise systems of linear equations. All of its arithmetical properties simply arise from preserving said information. When put together with vectors, we get the all-encompassing study of linear algebra. Here are some further questions you might think about involving matrices and vectors.
Consider the matrix 
- What vector
would satisfy the equation
?
- Is it possible to divide by
- Are there numbers
and vectors
?
- Is it possible to compute
in an efficient manner?
- Does the equation
These questions turn out to be basic problems in undergraduate linear algebra, and are used all the time in applied STEM, like physics, engineering, economics, and finance.
But for now, that is it for O-level mathematics!
—Joel Kindiak, 18 Mar 26, 1612H

Leave a comment